msg_reply
1.0.0
您见过或使用过 Google 智能回复吗?它是一项为用户消息提供自动回复建议的服务。见下文。
这是基于检索的聊天机器人的一个有用应用。想一想。我们有多少次发短信,比如“谢谢” 、 “嘿”或“稍后见” ?在这个项目中,我们构建了一个简单的消息回复建议系统。
奎平公园
Yj Choe 进行代码审查
我们需要设置要显示的建议列表。自然,首先考虑频率。但是那些含义相似的短语又如何呢?例如,是否应该非常感谢您并希望得到独立对待?我们不这么认为。我们想将它们分组并保存我们的位置。如何?我们使用平行语料库。 “非常感谢”和“谢谢”很可能被翻译成相同的文本。基于这个假设,我们构建了具有相同翻译的英语同义词组。
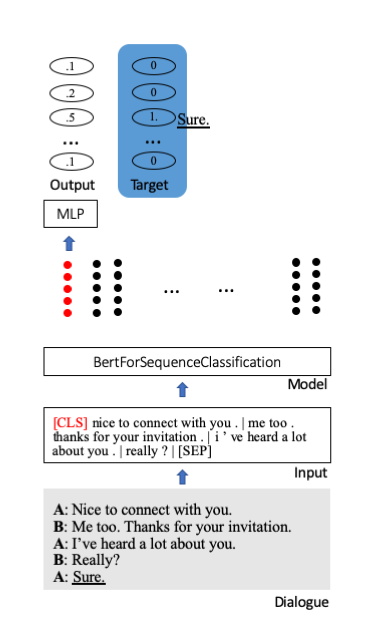
我们微调 Huggingface 的 Bert 预训练模型以进行序列分类。其中,一个特殊的起始标记[CLS]存储了句子的全部信息。附加额外层将压缩信息投射到分类单元(此处为 100)。
我们使用 OpenSubtitles 2018 西班牙语-英语平行语料库来构建同义词组。 OpenSubtitles 是翻译电影字幕的大型集合。 en-es 数据由超过 61M 的对齐行组成。
理想情况下,训练需要一个(非常)大的对话语料库,但我们未能找到。我们使用康奈尔大学电影对话语料库。它由 83,097 个对话或 304,713 行台词组成。
蟒蛇>=3.6
tqdm>=4.30.0
火炬>=1.0
pytorch_pretrained_bert>=0.6.1
nltk>=3.4
步骤 0. 下载 OpenSubtitles 2018 西班牙语-英语并行数据。
bash download.sh
步骤 1. 从语料库构建同义词组。
python construct_sg.py
步骤 2. 制作 phr2sg_id 和 sg_id2phr 字典。
python make_phr2sg_id.py
步骤 3. 将单语英语文本转换为 ids。
python encode.py
步骤 4. 创建训练数据并将其保存为 pickle。
python prepro.py
第 5 步:训练。
python train.py
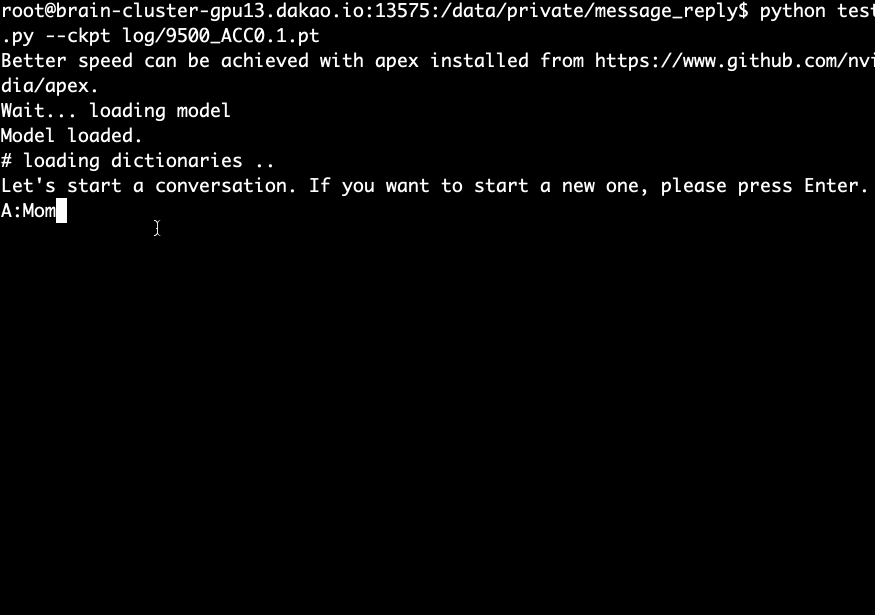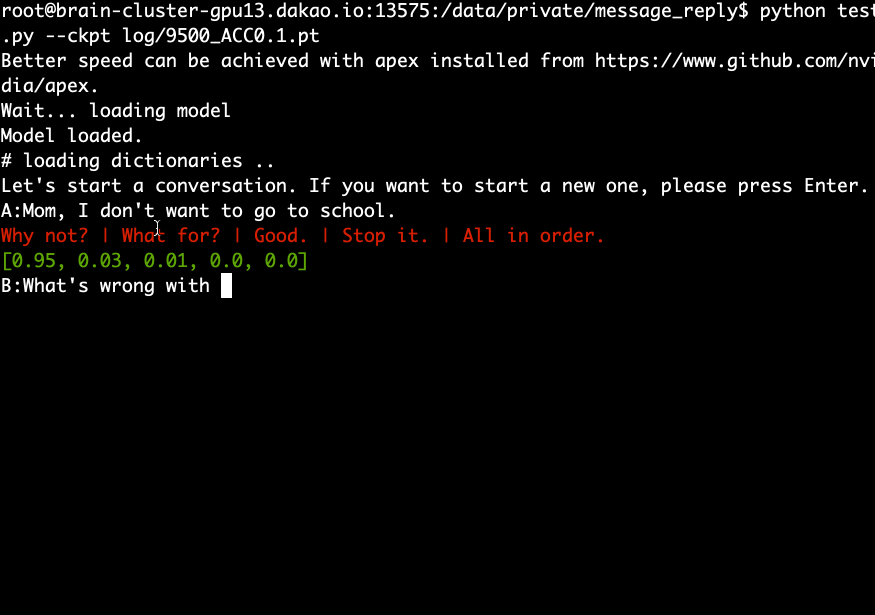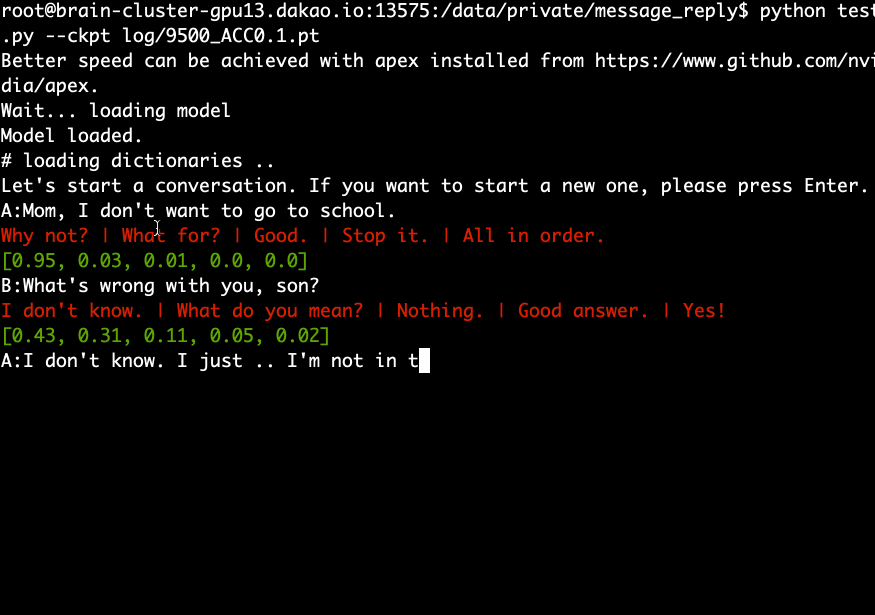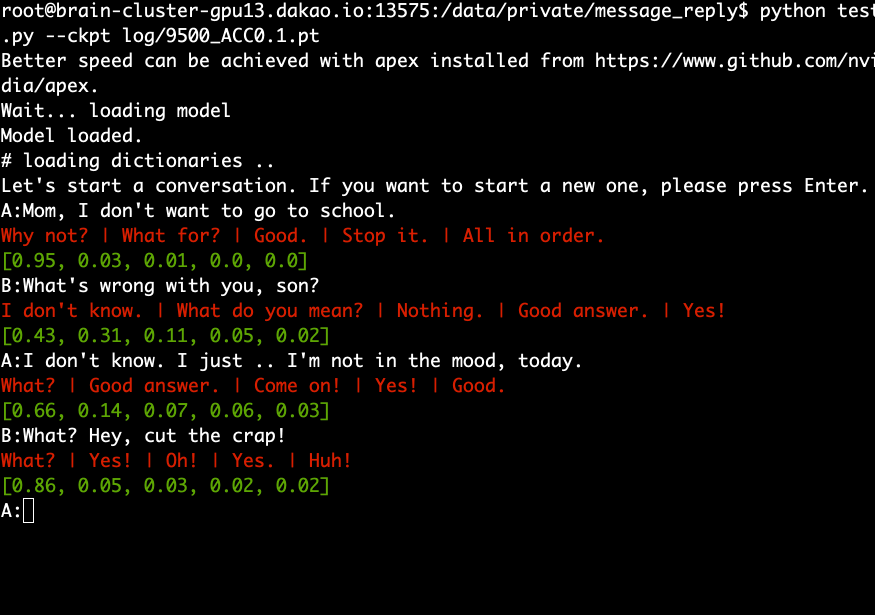
下载并提取预训练模型并运行以下命令。
python test.py --ckpt log/9500_ACC0.1.pt
训练损失缓慢但稳定地减少。
评估数据的 Accuracy@5 为 10% 至 20%。
对于实际应用,需要更大的语料库。
不确定电影剧本与消息对话有多少相似之处。
需要更好的构建同义词组的策略。
基于检索的聊天机器人是一种现实的应用程序,因为它比基于生成的聊天机器人更安全、更容易。


