RLAIF V
1.0.0

通过开源 AI 反馈调整 MLLM 以实现超级 GPT-4V 可信度
中文 |英语
[2024.11.26] 支持LoRA训练啦!
[2024.05.28] 我们的论文现在可以在 arXiv 上访问了!
[2024.05.20] 我们的RLAIF-V-Dataset用于训练MiniCPM-Llama3-V 2.5,它代表了第一个端侧GPT-4V级别MLLM!
[2024.05.20] 我们开源了RLAIF-V的代码、权重(7B、12B)和数据!
我们推出了 RLAIF-V,这是一种新颖的框架,它将 MLLM 与完全开源的范式结合起来,以实现超级 GPT-4V 的可信度。 RLAIF-V从高质量反馈数据和在线反馈学习算法两个关键角度最大限度地利用开源反馈。 RLAIF-V 的显着特点包括:
通过开源反馈实现超级 GPT-4V 可信度。通过学习开源 AI 反馈,RLAIF-V 12B 在生成和判别任务中实现了超级 GPT-4V 的可信度。
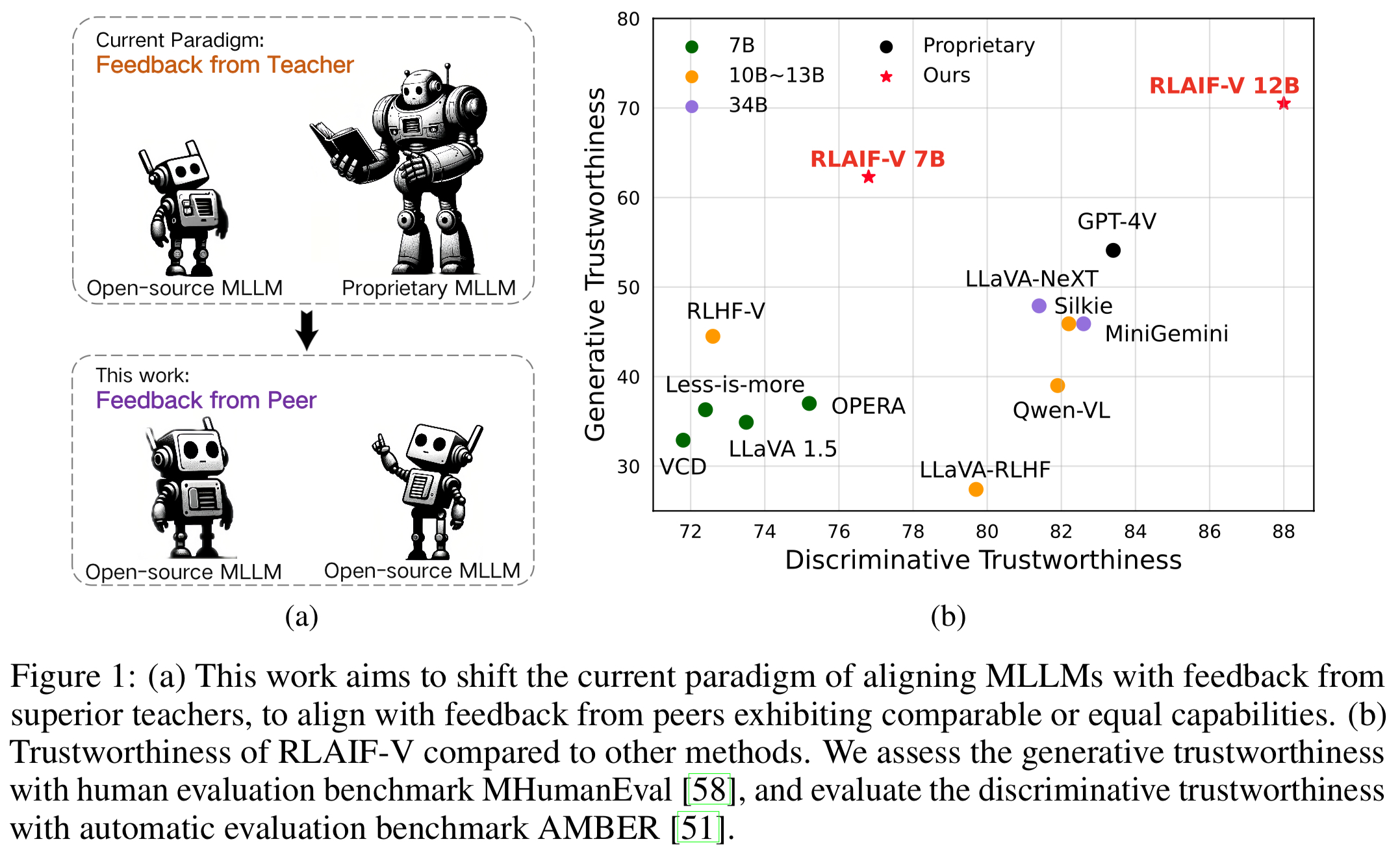
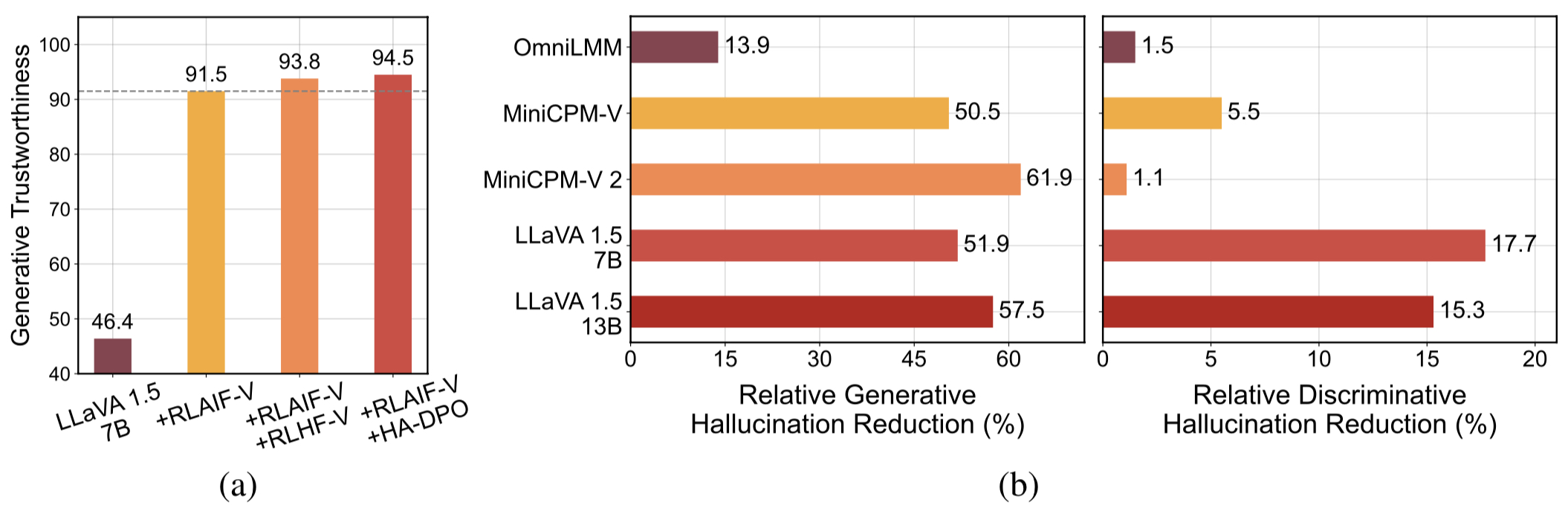
高质量的可概括的反馈数据。 RLAIF-V使用的反馈数据有效减少了不同MLLM的幻觉。
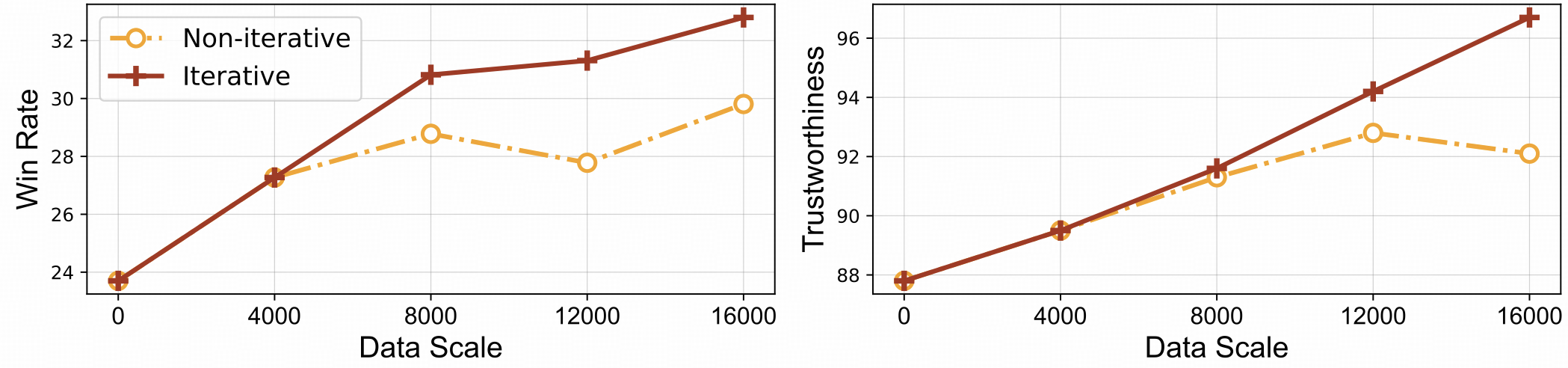
⚡️通过迭代对齐进行有效的反馈学习。与非迭代方法相比,RLAIF-V 表现出更好的学习效率和更高的性能。
数据集
安装
型号重量
推理
数据生成
火车
评估
对象 HalBench
MMHal 长凳
RefoMB
引文
我们提出了 RLAIF-V 数据集,这是一个人工智能生成的偏好数据集,涵盖各种任务和领域。这个开源多模式偏好数据集包含83,132 个高质量比较对。该数据集包含不同模型的每次训练迭代中生成的偏好对,包括 LLaVA 1.5 7B、OmniLMM 12B 和 MiniCPM-V。
克隆此存储库并导航到 RLAIF-V 文件夹
git 克隆 https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
安装包
conda 创建-n rlaifv python=3.10 -y conda 激活 rlaifv pip install -e 。
安装所需的 spaCy 模型
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip install en_core_web_trf-3.7.3.tar.gz
| 模型 | 描述 | 下载 |
|---|---|---|
| RLAIF-V 7B | LLaVA 1.5 上最值得信赖的变体 | ? |
| RLAIF-V 12B | 基于OmniLMM-12B,实现超级GPT-4V可信度。 | ? |
我们提供一个简单的示例来展示如何使用 RLAIF-V。
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # 或 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "详细描述以下人员图片。"inputs = {"image": image_path, "question": msgs}answer = chat_model.chat(输入)打印(答案)您还可以通过执行以下脚本来运行此示例:
蟒蛇聊天.py

问题:
图中的车为什么停了下来?
预期产出:
图中,由于路面上有一只羊,一辆汽车停在了路上。汽车停下来可能是为了让羊安全地让开,或者避免与动物发生任何潜在的事故。这种情况凸显了驾驶时小心谨慎的重要性,尤其是在动物可能在道路附近漫步的地区。
环境设置
我们提供 OmniLMM 12B 模型和 MiniCPM-Llama3-V 2.5 模型用于反馈生成。如果您希望使用MiniCPM-Llama3-V 2.5进行反馈,请按照MiniCPM-V GitHub存储库中的说明配置其推理环境。
请下载我们微调后的Llama3 8B模型:分割模型和问题转换模型,并将它们分别存储在./models/llama3_split文件夹和./models/llama3_changeq文件夹中。
OmniLMM 12B 型号反馈
以下脚本演示了使用 LLaVA-v1.5-7b 模型生成候选答案并使用 OmniLMM 12B 模型提供反馈。
mkdir ./结果 bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
MiniCPM-Llama3-V 2.5 模型反馈
以下脚本演示了使用 LLaVA-v1.5-7b 模型生成候选答案以及使用 MiniCPM-Llama3-V 2.5 模型提供反馈。首先,将./script/data_gen/run_data_pipeline_llava15_minicpmv.sh中的minicpmv_python替换为您创建的MiniCPM-V环境的Python路径。
mkdir ./结果 bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
准备数据(可选)
如果您可以访问huggingface数据集,则可以跳过此步骤,我们将自动下载RLAIF-V数据集。
如果您已经下载了数据集,则可以将第 38 行的“openbmb/RLAIF-V-Dataset”替换为您的数据集路径。
训练
在这里,我们提供了一个训练脚本来在1 次迭代中训练模型。 max_step参数应根据您的数据量进行调整。
全面微调
运行以下命令开始完全微调。
bash ./script/train/llava15_train.sh
洛拉
运行以下命令开始lora训练。
pip 安装peft bash ./script/train/llava15_train_lora.sh
迭代对齐
为了重现论文中的迭代训练过程,需要执行以下步骤4次:
S1。数据生成。
按照数据生成中的说明为基本模型生成偏好对。将生成的 jsonl 文件转换为 Huggingface Parquet。
S2。更改训练配置。
在数据集代码中,将此处的'openbmb/RLAIF-V-Dataset'替换为您的数据路径。
在训练脚本中,将--data_dir替换为新目录,将--model_name_or_path替换为基本模型路径,将--max_step设置为 4 epoch 的步数,将--save_steps设置为 1/4 epoch 的步数。
S3。进行 DPO 培训。
运行训练脚本来训练基本模型。
S4。选择下一次迭代的基础模型。
在 Object HalBench 和 MMHal Bench 上评估每个检查点,选择性能最好的检查点作为下一次迭代的基础模型。
准备COCO2014注释
Object HalBench 的评估依赖于 COCO2014 数据集的标题和分割注释。请先从COCO数据集官网下载COCO2014数据集。
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip 解压annotations_trainval2014.zip
推理、评价和总结
请将{YOUR_OPENAI_API_KEY}替换为有效的 OpenAI api 密钥。
注:评估基于gpt-3.5-turbo-0613 。
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}准备MMHal数据
请在此处下载 MMHal 评估数据,并将文件保存在eval/data中。
运行以下脚本来生成 MMHal Bench:
注:评估基于gpt-4-1106-preview 。
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}准备
要使用 GPT-4 评估,请首先运行pip install openai==0.28安装 openai 软件包。接下来,将eval/gpt4.py中的openai.base和openai.api_key更改为您自己的设置。
开发集的评估数据可以在eval/data/RefoMB_dev.jsonl中找到。您需要从每行中的image_url键下载每个图像。
综合评分评价
将模型答案保存在输入数据文件eval/data/RefoMB_dev.jsonl的answer键中,例如:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}运行以下脚本来评估您的模型结果:
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
幻觉评分评估
评估总分后,将创建一个名为A-GPT-4V_B-${model_name}.json评估结果文件。使用该评估结果文件计算幻觉分数如下:
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_result注意:为了更好的稳定性,我们建议您评估3次以上,并使用平均得分作为最终的模型得分。
使用和许可声明:数据、代码和检查点仅供研究使用并获得许可。它们还仅限于遵循 LLaMA、Vicuna 和 Chat GPT 许可协议的使用。该数据集为 CC BY NC 4.0(仅允许非商业用途),使用该数据集训练的模型不应在研究目的之外使用。
RLHF-V:我们构建的代码库。
LLaVA:RLAIF-V-7B 的指令模型和贴标机模型。
MiniCPM-V:RLAIF-V-12B的指令型号和贴标机型号。
如果您发现我们的模型/代码/数据/论文有帮助,请考虑引用我们的论文并给我们加星️!
@article{yu2023rlhf,title={Rlhf-v:通过细粒度矫正人类反馈的行为调整实现可信赖的MLLMs},作者={Yu,Tianyu和Yao,Yuan和Zhang,Haoye和He,Taiwen和Han,Yifeng和崔甘渠与胡、金一与刘、志远与郑、海涛与孙、毛松等},期刊={arXiv预印本arXiv:2312.00849},year={2023}}@article{yu2024rlaifv,title={RLAIF-V:通过开源 AI 反馈调整 MLLM 以实现超级 GPT-4V 可信度},作者={Yu、Tianyu 和Zhang、Haoye 和尧、元、党、云开、陈、大、禄、小满、崔、甘曲、何、泰文、刘志远和蔡,达成和孙茂松},期刊={arXiv预印本arXiv:2405.17220},年份={2024},
} 

