dialog eval
1.0.0
一个轻量级存储库,用于使用17 个指标自动评估对话模型。
? 选择您想要计算的指标
评估可以在响应文件或包含多个文件的目录上自动运行
? 指标以预定义的易于处理的格式保存
运行此命令来安装所需的软件包:
pip install -r requirements.txt
主文件可以从任何地方调用,但是在指定目录路径时,您应该从存储库的根目录给出它们。
python code/main.py -h
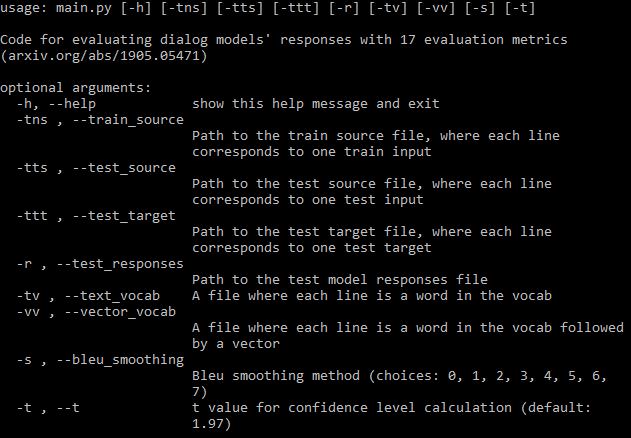
如需完整文档,请访问 wiki。
您应该提供尽可能多的所需参数路径(上图)。如果您错过了一些,程序仍然会运行,但它不会计算需要这些文件的一些指标(它将打印这些指标)。如果您有训练数据文件,程序可以自动生成词汇表并下载 fastText 嵌入。
如果您不想计算所有指标,您可以非常轻松地设置应在配置文件中计算哪些指标。
文件将保存到响应文件所在的目录中。第一行包含指标的名称,然后每行包含一个文件的指标。文件名后跟由空格分隔的各个指标值。每个指标由三个以逗号分隔的数字组成:平均值、标准差和置信区间。您可以在参数中设置置信区间的 t 值,默认为 95% 置信度。
有趣的是,在 DailyDialog 上训练 Transformer 模型期间,所有 17 个指标都会改善直到某个点,然后停滞不前,不会发生过拟合。检查论文附录中的数字。 
TRF 是在验证损失最小值下评估的 Transformer 模型,TRF-O 是在 150 个 epoch 训练后评估的 Transformer 模型,其中指标开始停滞。 RT 表示从训练集中随机选择的响应,GT 表示真实响应。

TRF 是 Transformer 模型,RT 是指从训练集中随机选择的响应,GT 是指真实响应。这些结果是在验证损失最小的检查点在测试集上测量的。

TRF 是 Transformer 模型,RT 是指从训练集中随机选择的响应,GT 是指真实响应。这些结果是在验证损失最小的检查点在测试集上测量的。
可以通过为指标创建一个类来添加新指标,该类处理给定数据的指标计算。查看 BLEU 指标的示例。通常,init 函数会处理稍后需要的任何数据设置,并且 update_metrics 使用参数中的当前示例更新指标字典。在类中,您应该定义 self.metrics 字典,它存储给定测试文件的指标值列表。这些指标的名称(字典的键)也应该添加到配置文件 self.metrics 中。最后,您需要将度量类的实例添加到 self.objects 中。如果您的指标需要任何设置,则在初始化时您可以使用数据文件的路径。此后,您的指标应该会自动计算并保存。
但是,您还应该向指标添加一些约束,例如,如果指标计算所需的文件丢失,则应通知用户,如下所示。
该项目根据 MIT 许可证获得许可 - 有关详细信息,请参阅许可证文件。
如果您在工作中使用该存储库,请包含该存储库的链接,并考虑引用以下论文:
@inproceedings{Csaky:2019,
title = "Improving Neural Conversational Models with Entropy-Based Data Filtering",
author = "Cs{'a}ky, Rich{'a}rd and Purgai, Patrik and Recski, G{'a}bor",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1567",
pages = "5650--5669",
}


