duplicut
v2.2 release
如今,密码单词列表的创建通常意味着连接多个数据源。
理想情况下,最可能的密码应位于单词列表的开头,因此最常见的密码会立即被破解。
使用现有的重复数据删除工具,您必须选择是希望保留顺序还是处理大量单词列表。
不幸的是,创建单词列表需要以下两者:

所以我用高度优化的 C 语言编写了 duplicut 来解决这个非常具体的需求?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt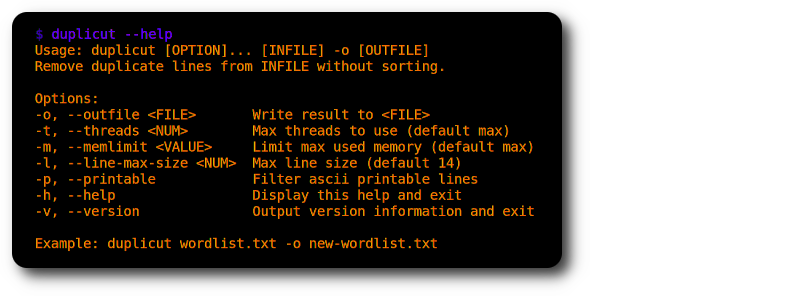
特征:
-l选项)-p选项)执行:
限制:
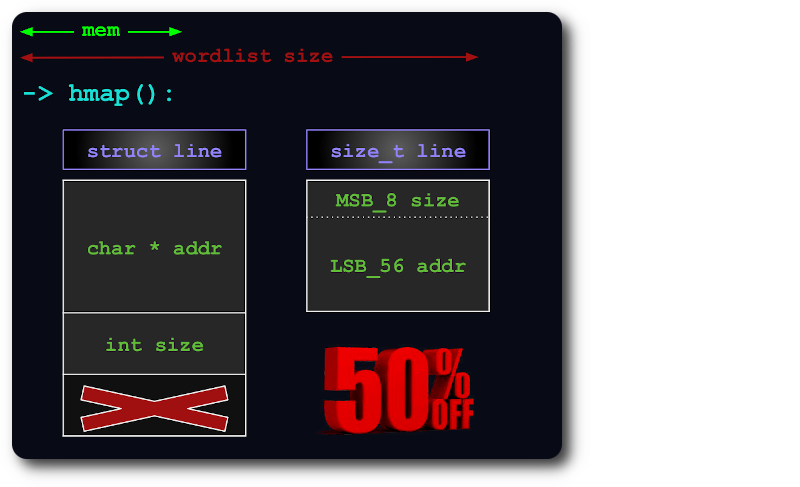
通过将size信息打包在指针的额外位中, uint64足以索引哈希图中的行:
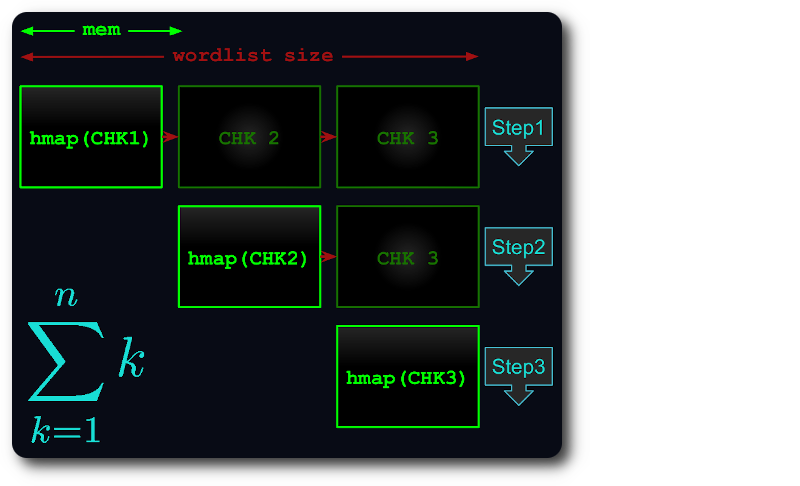
如果整个文件无法容纳在内存中,则会将其拆分为虚拟块,这样每个块都会使用尽可能多的 RAM。
然后将每个块加载到哈希映射中,进行重复数据删除,并针对后续块进行测试。
这样,执行时间最多减少到第 th 个三角形:
如果您发现错误,或者某些内容未按预期工作,请在调试模式下编译重复项并发布带有附加输出的问题:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


