customer support chatbot
1.0.0
聊天机器人是一种以类似人类的方式进行对话的计算机程序。该项目实现了聊天机器人,它尝试作为客户支持代理回答用户的问题。实施了以下客户支持聊天机器人:AppleSupport、AmazonHelp、Uber_Support、Delta 和 SpotifyCares。聊天机器人接受了 Twitter 上客户支持和用户之间公开对话的训练。
聊天机器人被实现为具有注意力的序列到序列深度学习模型。项目主要基于 Bahdanau 等人。 2014,Luong 等人。 2015. 和 Vinyals 等人,2015..
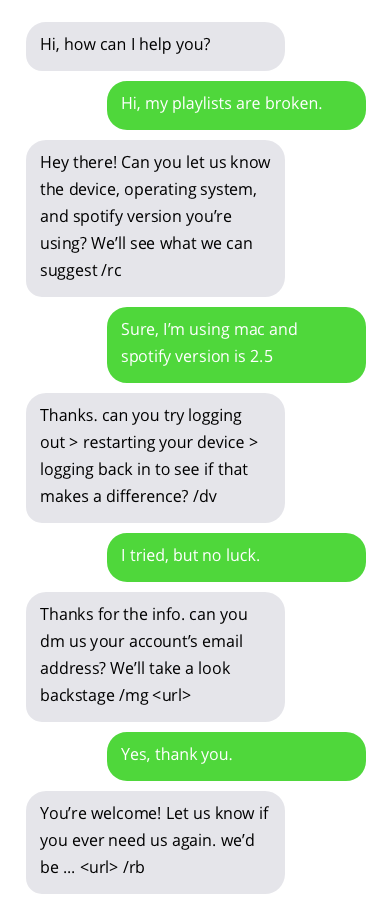
与客户支持聊天机器人的对话示例。与聊天机器人的对话并不理想,但显示出有希望的结果。聊天机器人的答案位于灰色气泡中。
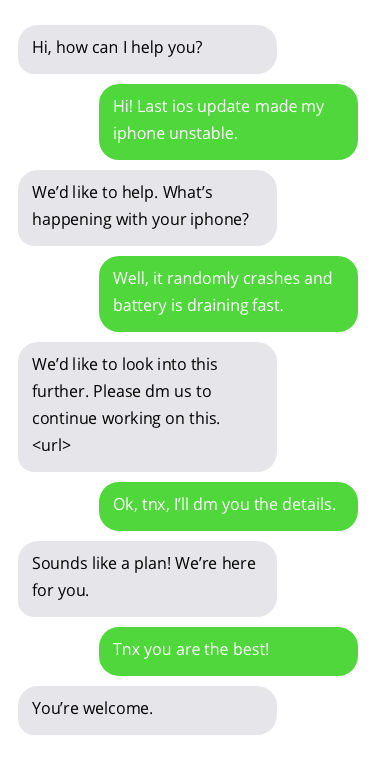
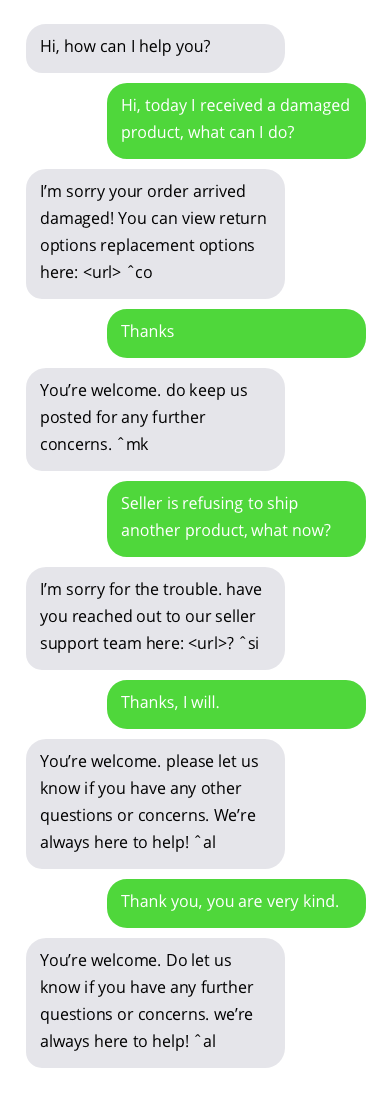
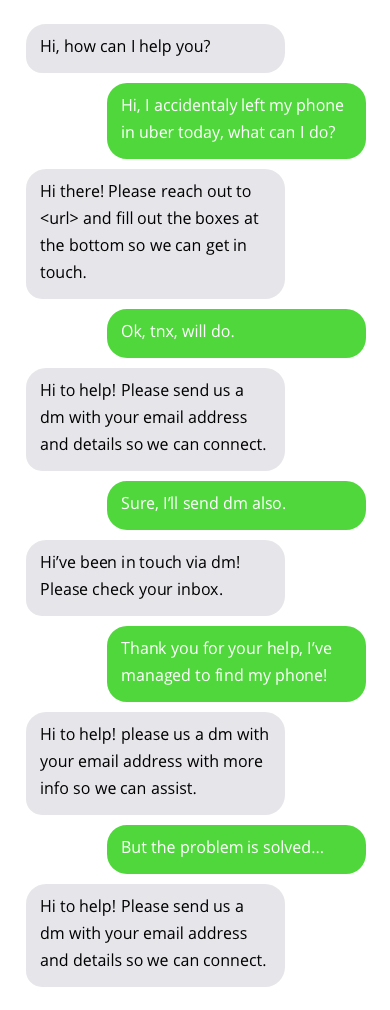
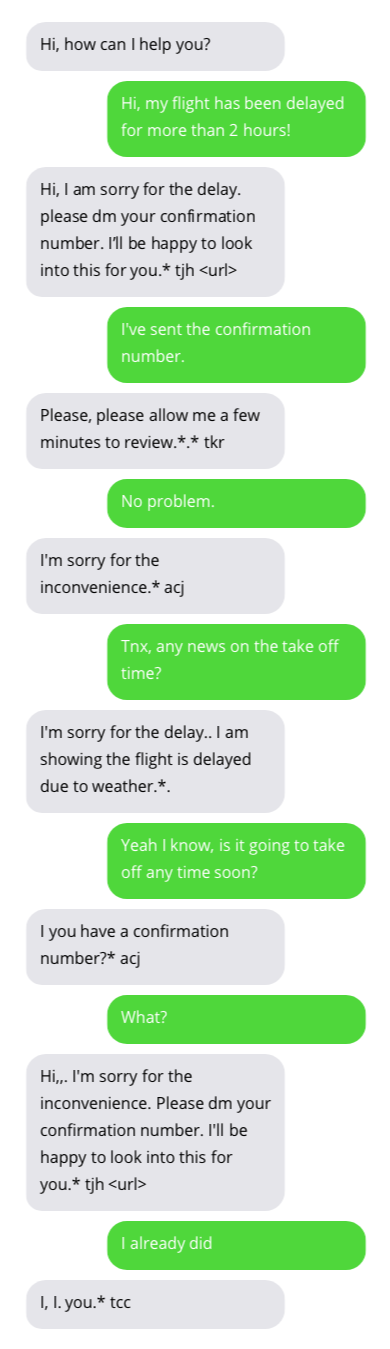
用于训练聊天机器人的数据集可以在这里找到。该数据集是通过收集 Twitter 上客户支持和用户之间的公开对话创建的。非常感谢数据集的作者!
您可以通过使用预先训练的模型或训练您自己的聊天机器人来尝试聊天机器人。
pip3 install -r requirements.txt
python3 -m spacy download en在此存储库的根目录中运行以下命令以下载预先训练的客户服务聊天机器人。
wget https://www.dropbox.com/s/ibm49gx1gefpqju/pretrained-models.zip
unzip pretrained-models.zip
rm pretrained-models.zip
sudo chmod +x predict.py现在您可以使用predict.py脚本与客户服务聊天机器人“交谈”。以下客户服务聊天机器人可用: apple,amazon,uber,delta,spotify 。以下示例展示了如何运行apple客户服务聊天机器人:
./predict.py -cs apple您可以选择自己训练聊天机器人。运行以下命令来下载并格式化本项目中使用的 Twitter 数据集:
wget https://www.dropbox.com/s/nmnlcncn7jtb7i9/twcs.zip
unzip twcs.zip
mkdir data
mv twcs.csv data
rm twcs.zip
python3 datasets/twitter_customer_support/format.py # this runs for couple of hours
sudo chmod +x train.py警告此块将运行几个小时!
现在您可以使用train.py来训练聊天机器人。
train.py用于训练 seq2seq 聊天机器人。
usage: train.py [-h] [--max-epochs MAX_EPOCHS] [--gradient-clip GRADIENT_CLIP]
[--batch-size BATCH_SIZE] [--learning-rate LEARNING_RATE]
[--train-embeddings] [--save-path SAVE_PATH]
[--save-every-epoch]
[--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}]
[--teacher-forcing-ratio TEACHER_FORCING_RATIO] [--cuda]
[--multi-gpu]
[--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d} | --embedding-size EMBEDDING_SIZE]
[--encoder-rnn-cell {LSTM,GRU}]
[--encoder-hidden-size ENCODER_HIDDEN_SIZE]
[--encoder-num-layers ENCODER_NUM_LAYERS]
[--encoder-rnn-dropout ENCODER_RNN_DROPOUT]
[--encoder-bidirectional] [--decoder-type {bahdanau,luong}]
[--decoder-rnn-cell {LSTM,GRU}]
[--decoder-hidden-size DECODER_HIDDEN_SIZE]
[--decoder-num-layers DECODER_NUM_LAYERS]
[--decoder-rnn-dropout DECODER_RNN_DROPOUT]
[--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE]
[--luong-input-feed]
[--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}]
[--attention-type {none,global,local-m,local-p}]
[--attention-score {dot,general,concat}]
[--half-window-size HALF_WINDOW_SIZE]
[--local-p-hidden-size LOCAL_P_HIDDEN_SIZE]
[--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE]
Script for training seq2seq chatbot.
optional arguments:
-h, --help show this help message and exit
--max-epochs MAX_EPOCHS
Max number of epochs models will be trained.
--gradient-clip GRADIENT_CLIP
Gradient clip value.
--batch-size BATCH_SIZE
Batch size.
--learning-rate LEARNING_RATE
Initial learning rate.
--train-embeddings Should gradients be propagated to word embeddings.
--save-path SAVE_PATH
Folder where models (and other configs) will be saved
during training.
--save-every-epoch Save model every epoch regardless of validation loss.
--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}
Dataset for training model.
--teacher-forcing-ratio TEACHER_FORCING_RATIO
Teacher forcing ratio used in seq2seq models. [0-1]
--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d}
Pre-trained embeddings type.
--embedding-size EMBEDDING_SIZE
Dimensionality of word embeddings.
GPU:
GPU related settings.
--cuda Use cuda if available.
--multi-gpu Use multiple GPUs if available.
Encoder:
Encoder hyperparameters.
--encoder-rnn-cell {LSTM,GRU}
Encoder RNN cell type.
--encoder-hidden-size ENCODER_HIDDEN_SIZE
Encoder RNN hidden size.
--encoder-num-layers ENCODER_NUM_LAYERS
Encoder RNN number of layers.
--encoder-rnn-dropout ENCODER_RNN_DROPOUT
Encoder RNN dropout probability.
--encoder-bidirectional
Use bidirectional encoder.
Decoder:
Decoder hyperparameters.
--decoder-type {bahdanau,luong}
Type of the decoder.
--decoder-rnn-cell {LSTM,GRU}
Decoder RNN cell type.
--decoder-hidden-size DECODER_HIDDEN_SIZE
Decoder RNN hidden size.
--decoder-num-layers DECODER_NUM_LAYERS
Decoder RNN number of layers.
--decoder-rnn-dropout DECODER_RNN_DROPOUT
Decoder RNN dropout probability.
--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE
Luong decoder attention hidden projection size
--luong-input-feed Whether Luong decoder should use input feeding
approach.
--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}
Decoder initial RNN hidden state initialization.
Attention:
Attention hyperparameters.
--attention-type {none,global,local-m,local-p}
Attention type.
--attention-score {dot,general,concat}
Attention score function type.
--half-window-size HALF_WINDOW_SIZE
D parameter from Luong et al. paper. Used only for
local attention.
--local-p-hidden-size LOCAL_P_HIDDEN_SIZE
Local-p attention hidden size (used when predicting
window position).
--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE
Attention layer hidden size. Used only with concat
score function.
predict.py用于与 seq2seq 聊天机器人“交谈”。
usage: predict.py [-h] [-cs {apple,amazon,uber,delta,spotify}] [-p MODEL_PATH]
[-e EPOCH] [--sampling-strategy {greedy,random,beam_search}]
[--max-seq-len MAX_SEQ_LEN] [--cuda]
Script for "talking" with pre-trained chatbot.
optional arguments:
-h, --help show this help message and exit
-cs {apple,amazon,uber,delta,spotify}, --customer-service {apple,amazon,uber,delta,spotify}
-p MODEL_PATH, --model-path MODEL_PATH
Path to directory with model args, vocabulary and pre-
trained pytorch models.
-e EPOCH, --epoch EPOCH
Model from this epoch will be loaded.
--sampling-strategy {greedy,random,beam_search}
Strategy for sampling output sequence.
--max-seq-len MAX_SEQ_LEN
Maximum length for output sequence.
--cuda Use cuda if available.


