dream
v1.13.0
DeepPavlov Dream是一个用于创建多技能生成式人工智能助手的平台。
要了解有关该平台以及如何用它构建人工智能助手的更多信息,请访问 Dream。如果您想了解有关为 Dream 提供支持的 DeepPavlov Agent 的更多信息,请访问 DeepPavlov Agent 文档。
我们已经包含了六个发行版:其中四个基于轻量级 Deepy 社交机器人,一个是英文版的全尺寸 Dream 聊天机器人(基于 Alexa 奖挑战版),另一个是俄语版 Dream 聊天机器人。
月球助手的基础版本。 Deepy Base 包含拼写预处理注释器、基于模板的 Harvesters Maintenance Skill 和基于 Dialog Flow Framework 的 AIML 开放域 Program-y Skill。
月球助手进阶版。 Deepy Advanced 包含拼写预处理、句子分割、实体链接和意图捕捉器注释器、用于目标导向响应的 Harvesters Maintenance GoBot Skill 以及基于 Dialog Flow Framework 的 AIML 开放域 Program-y Skill。
月球助手FAQ版本。 Deepy FAQ包含拼写预处理注释器、基于模板的常见问题解答技能和基于对话流框架的基于AIML的开放域Program-y技能。
月球助手的目标导向版本。 Deepy GoBot Base 包含拼写预处理注释器、用于目标导向响应的 Harvesters Maintenance GoBot Skill 以及基于 Dialog Flow Framework 的 AIML 开放域 Program-y Skill。
DeepPavlov Dream 社交机器人的完整版。这几乎与 Alexa 大奖挑战赛 4 结束时的 DREAM 社交机器人版本相同。一些 API 服务被可训练模型取代。某些服务(例如新闻注释器、游戏技能、天气技能)需要底层 API 的私钥,其中大多数可以免费获取。如果您想在本地部署中使用这些服务,请将您的密钥添加到环境变量中(例如./.env 、 ./.env_ru )。此版本的 Dream Socialbot 由于其模块化架构和最初的目标(参加 Alexa 大奖挑战赛)而消耗了大量资源。我们在我们的网站上提供了 Dream Socialbot 的演示。
DeepPavlov Dream 社交机器人的迷你版。这是一个基于生成的社交机器人,使用英语 DialoGPT 模型来生成大部分响应。它还包含意图捕获器和响应器组件来满足特殊的用户请求。链接到发行版。
DeepPavlov Dream 社交机器人的俄语版本。这是一个基于生成的社交机器人,它使用 DeepPavlov 的 Russian DialoGPT 来生成大部分响应。它还包含意图捕获器和响应器组件来满足特殊的用户请求。链接到发行版。
DeepPavlov Dream Socialbot 的迷你版,使用基于提示的生成模型。这是一个基于生成的社交机器人,它使用大型语言模型来生成大部分响应。您可以将自己的提示(json 文件)上传到 common/prompts,将提示名称添加到PROMPTS_TO_CONSIDER (以逗号分隔),提供的信息将在 LLM 支持的回复生成中用作提示。链接到发行版。
docker版本20及以上;docker-compose v1.29.2 版本; git clone https://github.com/deeppavlov/dream.git
如果运行 docker-compose 时出现“权限被拒绝”错误,请确保正确配置 docker 用户。
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
尝试 Dream 的最简单方法是通过代理部署它。所有请求都将被重定向到 DeepPavlov API,因此您不必使用任何本地资源。有关详细信息,请参阅代理使用情况。
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
请注意,DeepPavlov Dream 组件需要大量资源。请参阅组件部分以了解估计的需求。
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
我们还提供了针对多 GPU 环境的 GPU 分配配置:
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
当您需要重新启动特定的 docker 容器而不重新构建时(确保assistant_dists/dream/dev.yml中的映射正确):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
我们还提供了针对多 GPU 环境的 GPU 分配配置。
DeepPavlov Agent 提供了多种交互选项:命令行界面、HTTP API 和 Telegram 机器人
在单独的终端选项卡中运行:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
输入您的用户名并与 Dream 聊天!
启动机器人后,DeepPavlov 的代理 API 将在http://localhost:4242上运行。您可以从 DeepPavlov Agent 文档了解该 API。
基本的聊天界面将在http://localhost:4242/chat上提供。
目前,部署的是 Telegram bot,而不是HTTP API。在docker-compose.override.yml配置中编辑agent command定义:
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
注意:将您的 Telegram 令牌视为秘密,不要将其提交到公共存储库!
Dream 使用几个 docker-compose 配置文件:
./docker-compose.yml是核心配置,其中包括 DeepPavlov Agent 和 mongo 数据库的容器;
./assistant_dists/*/docker-compose.override.yml列出了该发行版的所有组件;
./assistant_dists/dream/dev.yml包含卷绑定,以便于 Dream 调试;
./assistant_dists/dream/proxy.yml是代理容器的列表。
如果您的部署资源有限,您可以将容器替换为由 DeepPavlov 托管的代理副本。为此,请覆盖proxy.yml中的那些容器定义,例如:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
并将此配置包含在您的部署命令中:
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
默认情况下, proxy.yml包含所有可用的代理定义。
梦想建筑如下图所示: 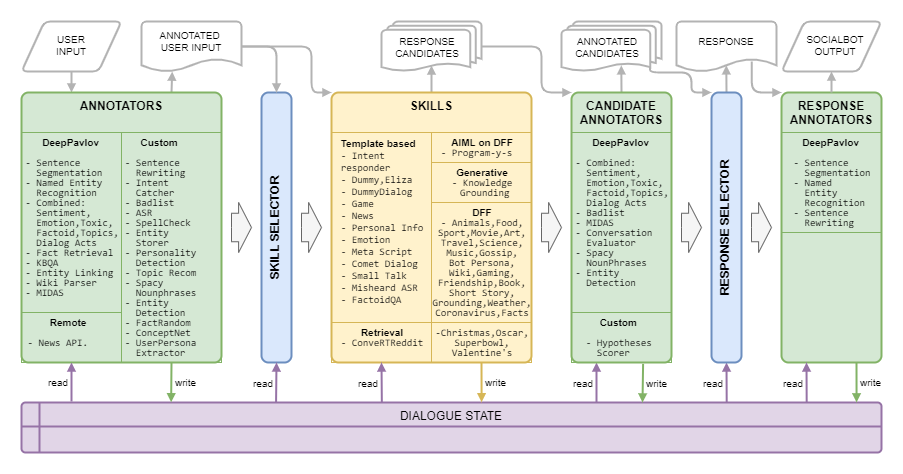
| 姓名 | 要求 | 描述 |
|---|---|---|
| 基于规则的选择器 | 根据主题、实体、情绪、毒性、对话行为和对话历史选择技能列表来生成对当前上下文的候选响应的算法 | |
| 响应选择器 | 50MB 内存 | 从给定的候选响应列表中选择最终响应的算法 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| 自动语音识别 | 40MB 内存 | 计算给定话语的总体 ASR 置信度,并将其评级为非常低、低、中或高(针对亚马逊标记) |
| 列入不良清单的单词 | 150MB 内存 | 检测不良列表中的单词和短语 |
| 组合分类 | 1.5 GB 内存,3.5 GB GPU | 基于BERT的模型,包括主题分类、对话行为分类、情感、毒性、情绪、事实分类 |
| 组合分类轻量化 | 1.6 GB 内存 | 与组合分类相同的模型,但由于主干网更轻,花费的时间减少了 42% |
| 彗星原子 | 2 GB 内存,1.1 GB GPU | 常识性预测模型 COMeT Atomic |
| COMeT概念网 | 2 GB 内存,1.1 GB GPU | 常识性预测模型 COMeT ConceptNet |
| Convers 评估器注释器 | 1 GB 内存,4.5 GB GPU | 根据之前比赛的 Alexa 奖数据进行训练,并预测候选人的回答是否有趣、可理解、切题、有吸引力或错误 |
| 情绪分类 | 2.5 GB 内存 | 情感分类标注器 |
| 实体检测 | 1.5 GB 内存,3.2 GB GPU | 从话语中提取实体及其类型 |
| 实体链接 | 2.5 GB 内存,1.3 GB GPU | 查找使用实体检测检测到的实体的维基数据实体 ID |
| 实体存储 | 220MB 内存 | 基于规则的组件,如果使用模式或 MIDAS 分类器检测到意见表达,则存储来自用户和社交机器人话语的实体,并将它们与检测到的对话状态态度一起保存 |
| 事实随机 | 50MB 内存 | 返回给定实体的随机事实(对于来自用户话语的实体) |
| 事实检索 | 7.4 GB 内存,1.2 GB GPU | 从 Wikipedia 和 wikiHow 中提取事实 |
| 意图捕手 | 1.7 GB 内存,2.4 GB GPU | 将用户话语分类为许多预定义的意图,这些意图在一组短语和正则表达式上进行训练 |
| KBQA | 2 GB 内存,1.4 GB GPU | 根据 Wikidata KB 回答用户的事实问题 |
| 迈达斯分类 | 1.1 GB 内存,4.5 GB GPU | 基于 BERT 的模型在 MIDAS 数据集的语义类子集上进行训练 |
| MIDAS 预测器 | 30MB 内存 | 基于 BERT 的模型在 MIDAS 数据集的语义类子集上进行训练 |
| NER | 2.2 GB 内存,5 GB GPU | 从无大小写文本中提取人名、地点名称、组织名称 |
| 新闻 API 注释器 | 80MB 内存 | 使用 GNews API 提取有关实体或主题的最新新闻。 DeepPavlov Dream 部署使用我们自己的 API 密钥。 |
| 个性捕手 | 30MB 内存 | 该技能是通过聊天界面改变系统的个性描述,它的作用相当于系统命令,响应的是类似系统的消息 |
| 提示选择器 | 50MB 内存 | 注释器利用句子排名器对提示进行排名并选择N_SENTENCES_TO_RETURN最相关的提示(基于提示中提供的问题) |
| 财产提取 | 6.3 GiB 内存 | 从话语中提取用户属性 |
| 耙动关键词 | 40MB 内存 | 借助 RAKE 算法从话语中提取关键字 |
| 相对角色提取器 | 50MB 内存 | 注释器利用句子排名器对人物句子进行排名并选择N_SENTENCES_TO_RETURN最相关的句子 |
| 森特瑞特 | 200MB 内存 | 通过用特定名称替换代词来重写用户的话语,为下游组件提供更多有用的信息 |
| 圣塞格 | 1 GB 内存 | 允许我们通过将用户的话语分成句子并恢复标点符号来处理长而复杂的用户话语 |
| 空格名词短语 | 180MB 内存 | 使用 Spacy 提取名词短语并过滤掉通用短语 |
| 语音功能分类器 | 1.1 GB 内存,4.5 GB GPU | Eggins 和 Slade 描述的基于多个线性模型的分层算法和基于规则的语音函数预测方法 |
| 语音功能预测器 | 1.1 GB 内存,4.5 GB GPU | 产生可以遵循语音函数分类器预测的语音函数的语音函数的概率 |
| 拼写预处理 | 50MB 内存 | 基于模式的组件将不同的口语表达重写为更正式的对话风格 |
| 话题推荐 | 40MB 内存 | 使用有关讨论的主题和用户偏好的信息提供进一步对话的主题。当前版本基于 Reddit 人物(请参阅 Alexa 奖 4 的梦想报告)。 |
| 毒性分类 | 3.5 GB 内存,3 GB GPU | 来自 Transformers 的有毒分类模型指定为 PRETRAINED_MODEL_NAME_OR_PATH |
| 用户角色提取器 | 40MB 内存 | 根据一些关键词判断用户属于哪个年龄段 |
| 维基解析器 | 100MB 内存 | 提取通过实体链接检测到的实体的维基数据三元组 |
| 维基事实 | 1.7GB 内存 | 从 Wikipedia 和 WikiHow 页面提取相关事实的模型 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| 迪亚洛GPT | 1.2 GB 内存,2.1 GB GPU | 基于 Transformers 生成模型的生成服务,该模型在 docker compose 参数PRETRAINED_MODEL_NAME_OR_PATH中设置(例如, microsoft/DialoGPT-small ,GPU 上的时间为 0.2-0.5 秒) |
| 基于 DialoGPT 角色 | 1.2 GB 内存,2.1 GB GPU | 基于 Transformers 生成模型的生成服务,该模型在 PersonaChat 数据集上进行了预训练,以生成以社交机器人角色的几个句子为条件的响应 |
| 图像字幕 | 4 GB 内存,5.4 GB GPU | 创建接收到的图像的文本表示 |
| 填充 | 1 GB 内存,1.2 GB GPU | (关闭但代码可用)基于 Infilling 模型的生成服务,对于给定的话语返回话语,其中原始文本中的_被生成的标记替换 |
| 知识基础 | 2 GB 内存,2.1 GB GPU | 基于 BlenderBot 架构的生成服务,考虑附加文本段落,提供对上下文的响应 |
| 蒙面LM | 1.1 GB 内存,1 GB GPU | (已关闭但代码可用) |
| 基于Seq2seq Persona | 1.5 GB 内存,1.5 GB GPU | 基于 Transformers seq2seq 模型的生成服务,该模型在 PersonaChat 数据集上进行了预训练,以生成以社交机器人角色的几个句子为条件的响应 |
| 句子排名 | 1.2 GB 内存,2.1 GB GPU | 以PRETRAINED_MODEL_NAME_OR_PATH给出的排名模型,对于一对 os 句子返回对应的浮点分数 |
| 故事GPT | 2.6 GB 内存,2.15 GB GPU | 基于微调 GPT-2 的生成服务,对于给定的一组关键字,返回使用该关键字的短篇故事 |
| GPT-3.5 | 100MB 内存 | 基于 OpenAI API 服务的生成服务,模型在 docker compose 参数PRETRAINED_MODEL_NAME_OR_PATH中设置(特别是,在此服务中,使用了text-davinci-003 。 |
| 聊天GPT | 100MB 内存 | 基于 OpenAI API 服务的生成服务,模型在 docker compose 参数PRETRAINED_MODEL_NAME_OR_PATH中设置(特别是,在此服务中,使用gpt-3.5-turbo 。 |
| 提示故事GPT | 3 GB 内存,4 GB GPU | 基于微调 GPT-2 的生成服务,对于由一个名词表示的给定主题,返回给定主题的短篇故事 |
| GPT-J 6B | 1.5 GB 内存,24.2 GB GPU | 基于 Transformers 生成模型的生成服务,模型在 docker compose 参数PRETRAINED_MODEL_NAME_OR_PATH中设置(特别是,在该服务中,使用 GPT-J 模型。 |
| 布卢姆兹7B | 2.5 GB 内存,29 GB GPU | 基于 Transformers 生成模型的生成服务,该模型在 docker compose 参数PRETRAINED_MODEL_NAME_OR_PATH中设置(特别是,在此服务中,使用 BLOOMZ-7b1 模型。 |
| GPT-JT 6B | 2.5 GB 内存,25.1 GB GPU | 基于 Transformers 生成模型的生成服务,模型在 docker compose 参数PRETRAINED_MODEL_NAME_OR_PATH中设置(特别是,在该服务中,使用 GPT-JT 模型。 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| 亚历克斯·汉德勒 | 30MB 内存 | 几个特定 Alexa 命令的处理程序 |
| 圣诞技能 | 30MB 内存 | 支持圣诞节常见问题解答、事实和脚本 |
| 彗星对话技能 | 300MB 内存 | 使用 COMeT ConceptNet 模型来表达意见、提出问题或对对话中提到的用户操作进行评论 |
| 转换 Reddit | 1.2GB 内存 | 使用 ConveRT 编码器为句子构建有效的表示 |
| 假人技能 | 代理容器的一部分 | 具有多个无毒候选响应的后备技能 |
| 虚拟技能对话框 | 600MB 内存 | 如果用户对虚拟技能的响应与源数据中的相应响应相似,则返回主题聊天数据集中的下一个回合 |
| 伊丽莎 | 30MB 内存 | 聊天机器人 (https://github.com/wadetb/eliza) |
| 情感技巧 | 40MB 内存 | 返回对来自组合分类注释器的情绪分类检测到的情绪的模板响应 |
| 事实问答 | 170MB 内存 | 回答事实问题 |
| 游戏合作技巧 | 100MB 内存 | 为用户提供有关电脑游戏的对话:过去一年、过去一个月和上周的最佳游戏排行榜 |
| 收割机维护技巧 | 30MB 内存 | 收割机的维护保养技巧 |
| 收割机维护 Gobot 技能 | 30MB 内存 | 收割机维护 目标导向技能 |
| 知识基础技能 | 100MB 内存 | 根据对话历史生成响应并提供与当前对话主题相关的知识 |
| 元脚本技能 | 150MB 内存 | 提供围绕人类活动的多轮对话。该技能使用 COMeT Atomic 模型生成多个方面的常识性描述和问题 |
| 听错了 ASR | 40MB 内存 | 当 ASR 置信度太低时,使用 ASR 处理器注释向用户提供反馈 |
| 新闻API技巧 | 60MB 内存 | 使用 GNews API 呈现有关实体或主题的最受好评的最新新闻 |
| 奥斯卡技能 | 30MB 内存 | 支持奥斯卡常见问题解答、事实和脚本 |
| 个人信息技能 | 40MB 内存 | 查询并存储用户的姓名、出生地和位置 |
| DFF 计划 Y 技能 | 800MB 内存 | [新 DFF 版本]聊天机器人程序 Y (https://github.com/keiffster/program-y) 适用于 Dream 社交机器人 |
| DFF 计划 Y 危险技能 | 100MB 内存 | [新 DFF 版本]聊天机器人程序 Y (https://github.com/keiffster/program-y) 适用于 Dream 社交机器人,包含对对话中危险情况的响应 |
| DFF 计划 Y 广泛技能 | 110MB 内存 | [新DFF版本] Chatbot Program Y(https://github.com/keiffster/program-y)适用于Dream Socialbot,仅包含非常通用的模板(置信度较低) |
| 闲聊技巧 | 35MB 内存 | 使用手写脚本提出 25 个主题的问题,包括但不限于爱情、运动、工作、宠物等。 |
| 超级碗技巧 | 30MB 内存 | 支持 SuperBowl 的常见问题解答、事实和脚本 |
| 文本质量检查 | 1.8 GB 内存,2.8 GB GPU | 该服务在文本中查找事实问题的答案。 |
| 情人节技巧 | 30MB 内存 | 支持情人节常见问题解答、事实和脚本 |
| 维基数据拨号技巧 | 100MB 内存 | 使用 Wikidata 三元组生成话语。未开启,需要改进 |
| DFF动物技能 | 200MB 内存 | 使用 DFF 创建,具有关于动物的三个对话分支:用户的宠物、社交机器人的宠物和野生动物 |
| DFF艺术技巧 | 100MB 内存 | 基于 DFF 的艺术讨论技巧 |
| DFF书籍技能 | 400MB 内存 | [新 DFF 版本]借助 Wiki 解析器和实体链接检测用户话语中提到的书名和作者,并利用 GoodReads 数据库中的信息推荐书籍 |
| DFF 机器人角色技能 | 150MB 内存 | 旨在通过短篇故事讨论用户最喜欢的内容和 20 个最受欢迎的事物,表达社交机器人对他们的看法 |
| DFF 冠状病毒技能 | 110MB 内存 | [新 DFF 版本]检索来自约翰·霍普金斯大学系统科学与工程中心的不同地点的冠状病毒病例数和死亡人数数据 |
| DFF 食物技能 | 150MB 内存 | 用 DFF 构建,鼓励与食物相关的对话 |
| DFF友谊技能 | 100MB 内存 | [新 DFF 版本]基于 DFF 的技能在对话框开始时问候用户,并将用户转发到一些脚本化技能 |
| DFF 功能技能 | 100MB 内存 | 【新DFF版本】告诉用户有趣的事实 |
| DFF游戏技巧 | 80MB 内存 | 提供视频游戏讨论。游戏技能是关于视频游戏的更一般性的讨论 |
| DFF八卦技能 | 95MB 内存 | 基于 DFF 的技能来讨论其他人的新闻 |
| DFF图像技巧 | 100MB 内存 | [新 DFF 版本]脚本化技能,基于发送的图像字幕(来自注释)响应,在检测到食物、动物或人的情况下具有指定响应,否则默认响应 |
| DFF模板技巧 | 50MB 内存 | [新DFF版本]基于DFF的技能,提供DFF使用示例 |
| DFF模板提示技巧 | 50MB 内存 | [新 DFF 版本]基于 DFF 的技能,提供语言模型根据指定提示和对话上下文生成的答案。要使用的模型在 GENERATIVE_SERVICE_URL 中指定。例如,您可以使用 Transformer LM GPTJ 服务。 |
| DFF接地技巧 | 90MB 内存 | [新DFF版本]基于DFF的技能来回答对话的主题是什么,生成确认,通过MIDAS对某些对话行为生成通用响应 |
| DFF 意图响应器 | 100MB 内存 | [新DFF版本]为Intent Catcher注释器检测到的一些意图提供基于模板的回复 |
| DFF电影技巧 | 1.1GB 内存 | 使用 DFF 实现并处理与电影相关的对话 |
| DFF音乐技巧 | 70MB 内存 | 基于 DFF 的音乐讨论技巧 |
| DFF科学技能 | 90MB 内存 | 基于 DFF 的科学讨论技能 |
| DFF短篇小说技巧 | 90MB 内存 | 【新DFF版本】为用户讲述3类短故事:(1)睡前故事,例如寓言和道德故事,(2)恐怖故事,(3)搞笑故事 |
| DFF运动技能 | 70MB 内存 | 基于 DFF 的体育讨论技能 |
| DFF 旅行技巧 | 70MB 内存 | 基于 DFF 的旅行讨论技巧 |
| DFF 天气技能 | 1.4 GB 内存 | [新DFF版本]使用OpenWeatherMap服务获取用户位置的天气预报 |
| DFF 维基技能 | 150MB 内存 | 用于制作包含实体提取、槽填充、事实插入和确认的场景 |
| 姓名 | 要求 | 描述 |
|---|---|---|
| AI常见问题解答技巧 | 150MB 内存 | 【新DFF版本】关于现代人工智能你想知道但又不敢问的一切!此常见问题解答助手会与您聊天,同时解释当今技术世界中最简单的主题。 |
| 时尚造型师技能 | 150MB 内存 | 【新DFF版本】达科斯塔工业服装助手,让每个季节都受到保护!无论天气如何,都能体验终极的舒适和保护。冬天要注意保暖,... |
| 梦境角色技能 | 150MB 内存 | [新DFF版本]基于提示的技能,利用给定的生成服务根据给定的提示生成响应 |
| 营销技巧 | 150MB 内存 | [新DFF版本]通过营销AI助手以前所未有的方式与您的受众建立联系!通过利用同理心的力量达到成功的新高度。告别.. |
| 童话技能 | 150MB 内存 | 【新版DFF】小助手将为您或您的孩子讲述一个简短却引人入胜的童话故事。选择人物和主题,剩下的就交给人工智能想象吧。 |
| 营养技能 | 150MB 内存 | 【DFF新版】与AI助手一起探索健康饮食的秘密!轻松为您和您所爱的人找到营养丰富的食物选择。告别用餐压力,迎接美味…… |
| 生活辅导技巧 | 150MB 内存 | 【新DFF版本】使用Rhodes & Co的专利AI助手释放您的全部潜力!在工作和家庭中达到最佳表现。轻松进入最佳状态并激励他人。 |
库拉托夫 Y. 等人。 2019 年 Alexa 奖的 DREAM 技术报告//Alexa 奖论文集。 – 2020 年。
Baymurzina D.等人。 Alexa 奖 4 //Alexa 奖程序的 DREAM 技术报告。 – 2021 年。
DeepPavlov Dream 在 Apache 2.0 下获得许可。
Program-y(请参阅dream/skills/dff_program_y_skill 、 dream/skills/dff_program_y_wide_skill 、 dream/skills/dff_program_y_dangerous_skill )在 Apache 2.0 下获得许可。 Eliza(参见dream/skills/eliza )根据 MIT 许可证获得许可。
要制作带有机器人响应的认证xlsx文件,您可以通过执行来使用xlsx_responder.py脚本
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json确保所有服务均已部署。 --input - 包含认证问题的xlsx文件, --output - 包含机器人响应的xlsx文件, --cache - json ,其中包含详细标记并用于缓存。


