Seq2seq Chatbot for Keras
1.0.0
该存储库包含基于 seq2seq 建模的新聊天机器人生成模型。有关该模型的更多详细信息,请参阅论文“生成对话代理的端到端对抗学习”的第 3 节。如果使用此存储库中的想法或代码片段进行发布,请引用本文。
此处可用的训练模型使用由约 8K 对上下文(截至当前点的对话的最后两个话语)和相应响应组成的小型数据集。数据是从在线英语课程的对话中收集的。这种经过训练的模型可以使用封闭域数据集针对实际应用进行微调。
规范的 seq2seq 模型在神经机器翻译中变得流行,该任务对于属于输入和输出序列的单词具有不同的先验概率分布,因为输入和输出话语是用不同的语言编写的。这里提出的架构假设输入和输出词具有相同的先验分布。因此,它通过采用新的模型在编码和解码过程之间共享一个嵌入层(Glove预训练词嵌入)。为了提高上下文敏感性,思想向量(即编码器输出)对直到当前点的对话的最后两个话语进行编码。为了避免在答案生成过程中忘记上下文,思想向量被连接到一个密集向量,该密集向量对截至当前点生成的不完整答案进行编码。得到的向量被提供给预测答案的当前标记的密集层。请参阅我们论文的第 3.1 节,以更好地了解我们模型的优势。
该算法通过将预测的标记包含到不完整的答案中并将其反馈到如下所示的模型的右侧输入层来进行迭代。
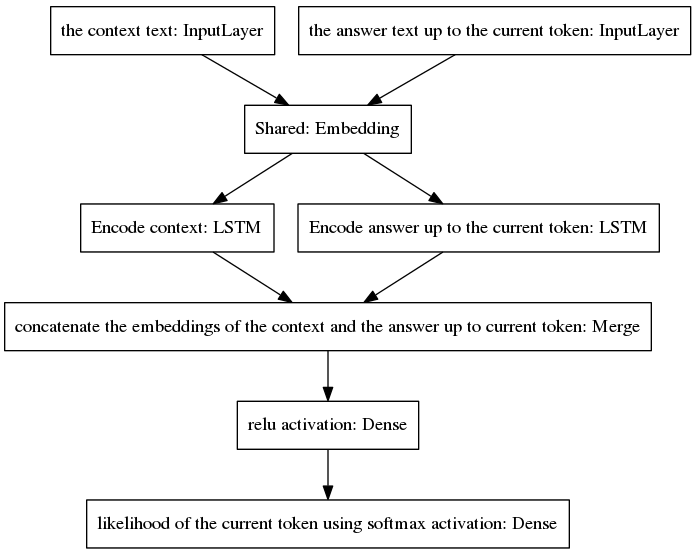
从上图中可以看出,两个 LSTM 是并行排列的,而规范的 seq2seq 的编码器和解码器的循环层是串联排列的。循环层在随时间反向传播期间展开,导致大量嵌套函数,因此梯度消失的风险更高,而规范 seq2seq 模型的循环层级联会加剧这种情况,即使在门控架构的情况下也是如此例如 LSTM。我相信这是我的模型在训练过程中比规范 seq2seq 表现更好的原因之一。
以下伪代码解释了该算法。

这个新模型的训练在几个时期内收敛。使用我们的 8K 训练示例数据集,只需要 100 个时期即可达到 0.0318 的分类交叉熵损失,而在 GPU GTX980 中运行的成本为 139 秒/时期。这个经过训练的模型(在此存储库中提供)的性能似乎与在康奈尔电影对话语料库的约 300K 训练示例上训练的普通 seq2seq 模型的性能一样令人信服,但训练所需的计算量要少得多。
与预训练模型聊天:
下载Python文件“conversation.py”、词汇文件“vocabulary_movie”和净权值“my_model_weights20”,可以在这里找到;
运行对话.py。
与我们新的基于 GAN 的训练算法训练的新模型聊天:
下载Python文件“conversation_discriminator.py”、词汇文件“vocabulary_movie”和净权重“my_model_weights20.h5”、“my_model_weights.h5”和“my_model_weights_discriminator.h5”,可以在此处找到;
运行conversation_discriminator.py。
该模型使用相同的训练数据具有更好的性能。基于 GAN 的模型的判别器用于在两个模型之间选择最佳答案,一个模型由教师强制训练,另一个模型由我们新的类似 GAN 的训练方法训练,其详细信息可以在本文中找到。
要训练新模型或微调您自己的数据:
如果您想从头开始训练,请删除文件 my_model_weights20.h5。要微调您的数据,请保留此文件;
下载 Glove 文件夹“glove.6B”并将该文件夹包含在聊天机器人的目录中(您可以在此处找到该文件夹)。该算法通过使用预训练的词嵌入来应用迁移学习,该词嵌入在训练过程中进行微调;
运行 split_qa.py 将训练数据的内容拆分为两个文件:“context”和“answers”,并运行 get_train_data.py 将填充的句子存储到文件“Plated_context”和“Plated_answers”中;
运行 train_bot.py 来训练聊天机器人(建议使用 GPU,为此输入:THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,exception_verbosity=high python train_bot.py);
将您的训练数据命名为“data.txt”。该文件每行必须包含一个对话话语。如果您的数据集很大,请将变量 num_subsets (在 train_bot.py 的第 29 行中)设置为更大的数字。
权重文件 = 'my_model_weights20.h5' 权重文件_GAN = 'my_model_weights.h5' 权重文件_discrim = 'my_model_weights_discriminator.h5'
可以在这里找到不同框架的神经对话模型的当前实现(以及一些结果)的很好的概述。
我们的模型可以应用于其他 NLP 任务,例如文本摘要,请参见示例 2:递归模型 A。我们鼓励我们的模型在其他任务中的应用,在这种情况下,我们恳请您尽可能引用我们的工作可以在这份 2017 年 7 月注册的文件中看到。
这些代码可以在 Ubuntu 14.04.3 LTS、Python 2.7.6、Theano 0.9.0 和 Keras 2.0.4 中运行。使用其他配置可能需要一些小的调整。


