MELD
1.0.0
如果您对智商测试法学硕士感兴趣,请查看我们的新作品:AlgoPuzzleVQA
我们发布了使用 Resnet 提取的视觉特征 - https://github.com/declare-lab/MM-Align
有关更新的基线,请访问此链接:conv-emotion
要下载数据,请使用 wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
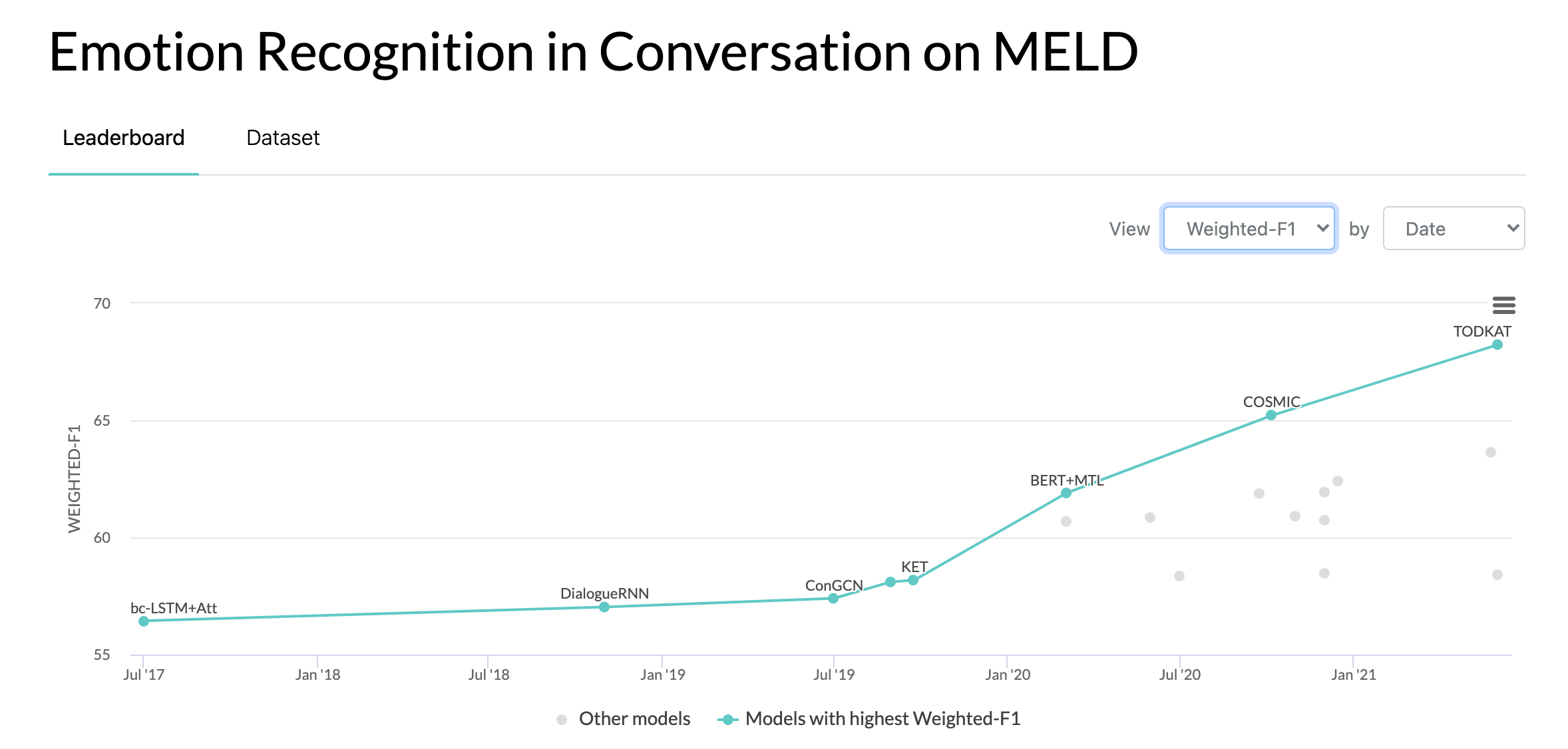
2020 年 10 月 10 日:MELD 数据集对话中情绪识别的新论文和 SOTA。代码请参见 COSMIC 目录。阅读论文 - COSMIC:对话中情绪识别的 COMmonSense 知识。
2019 年 5 月 22 日:MELD:对话中情绪识别的多模式多方数据集已被 ACL 2019 接受为全文。更新后的论文可在此处找到 - https://arxiv.org/pdf/1810.02508。 pdf
2019 年 5 月 22 日:二元 MELD 已发布。它可用于测试二元对话模型。
2018 年 11 月 15 日:train.tar.gz 中的问题已修复。
张亚洲、李秋池、宋大伟、张鹏、王盼盼。 “用于对话情感分析的量子启发交互式网络。”国际JCAI 2019。
张、董、吴良庆、孙长龙、李寿山、朱巧明和周国栋。 “对上下文和说话人敏感依赖性进行建模,以实现多说话人对话中的情绪检测。”国际JCAI 2019。
Ghosal、Deepanway、Navonil Majumder、Soujanya Poria、Niyati Chhaya 和 Alexander Gelbukh。 “DialogueGCN:用于对话中情绪识别的图卷积神经网络。” EMNLP 2019。
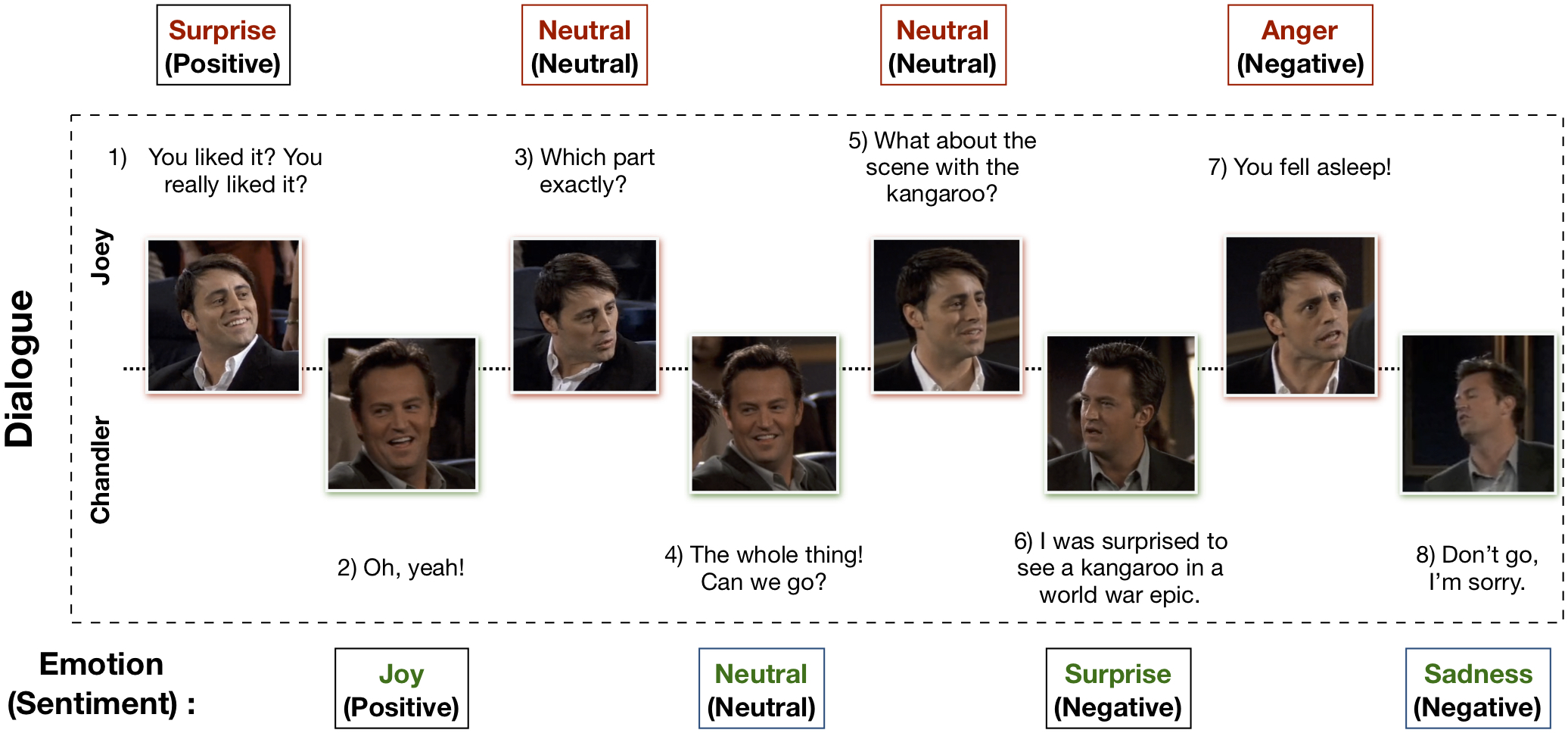
多模态 EmotionLines 数据集 (MELD) 是通过增强和扩展 EmotionLines 数据集创建的。 MELD 包含与 EmotionLines 中相同的对话实例,但它还包含音频和视觉模式以及文本。 MELD 拥有《老友记》电视剧中的 1400 多个对话和 13000 多个话语。多位发言者参与了对话。对话中的每句话都被标记为这七种情绪中的任何一种:愤怒、厌恶、悲伤、喜悦、中性、惊讶和恐惧。 MELD 还为每个话语提供情绪(积极、消极和中立)注释。
| 统计数据 | 火车 | 开发者 | 测试 |
|---|---|---|---|
| 模态# | {a,v,t} | {a,v,t} | {a,v,t} |
| # 独特的单词 | 10,643 | 2,384 | 4,361 |
| 平均。话语长度 | 8.03 | 7.99 | 8.28 |
| 最大限度。话语长度 | 69 | 37 | 45 |
| 平均。每个对话的情绪数量 | 3.30 | 3.35 | 3.24 |
| 对话数量 | 1039 | 114 | 280 |
| # 话语数 | 9989 | 1109 | 2610 |
| 发言者数量 | 260 | 47 | 100 |
| # 情绪转变 | 4003 | 第427章 | 1003 |
| 平均。话语的持续时间 | 3.59秒 | 3.59秒 | 3.58秒 |
请访问 https://affective-meld.github.io 了解更多详情。
| 火车 | 开发者 | 测试 | |
|---|---|---|---|
| 愤怒 | 1109 | 153 | 第345章 |
| 厌恶 | 第271章 | 22 | 68 |
| 害怕 | 268 | 40 | 50 |
| 喜悦 | 第1743章 | 163 | 第402章 |
| 中性的 | 4710 | 第470章 | 第1256章 |
| 悲伤 | 第683章 | 111 | 208 |
| 惊喜 | 1205 | 150 | 第281章 |
多模态数据分析利用来自多个并行数据通道的信息进行决策。随着人工智能的快速发展,多模态情感识别引起了人们的主要研究兴趣,这主要是由于它在许多具有挑战性的任务中的潜在应用,例如对话生成、多模态交互等。会话情感识别系统可用于通过以下方式生成适当的响应:分析用户情绪。尽管关于多模态情感识别的工作有很多,但真正关注于理解对话中的情感的研究却很少。然而,他们的工作仅限于二元对话理解,因此无法扩展到具有两个以上参与者的多方对话中的情绪识别。 EmotionLines 只能用作文本情感识别的资源,因为它不包括来自其他形式(例如视觉和音频)的数据。同时,应该指出的是,目前还没有可用于情感识别研究的多模态多方会话数据集。在这项工作中,我们针对多模式场景扩展、改进和进一步开发了 EmotionLines 数据集。连续轮流中的情绪识别面临一些挑战,上下文理解就是其中之一。对话中的情绪变化和情绪流动使得准确的上下文建模成为一项艰巨的任务。在此数据集中,由于我们可以访问每个对话的多模式数据源,我们假设它将改进上下文建模,从而有利于整体情绪识别性能。该数据集还可用于开发多模式情感对话系统。 IEMOCAP、SEMAINE 是多模式会话数据集,其中包含每个话语的情感标签。然而,这些数据集本质上是二元的,这证明了我们的 Multimodal-EmotionLines 数据集的重要性。其他公开可用的多模态情感和情绪识别数据集是 MOSEI、MOSI、MOUD。然而,这些数据集都不是对话性的。
第一步涉及查找 EmotionLines 数据集中每个对话中每个话语的时间戳。为了实现这一目标,我们爬取了所有剧集的字幕文件,其中包含话语的开始和结束时间戳。这个过程使我们能够获取剧集 ID、剧集 ID 和剧集中每个话语的时间戳。我们在获取时间戳时设置了两个约束:(a)对话中话语的时间戳必须按升序排列,(b)对话中的所有话语必须属于同一情节和场景。通过这两个条件的约束发现,在 EmotionLines 中,少数对话由多个自然对话组成。我们从数据集中过滤掉了这些案例。由于这个纠错步骤,在我们的例子中,与 EmotionLine 相比,我们有不同数量的对话。获得每个话语的时间戳后,我们从源剧集中提取其相应的视听片段。另外,我们还从这些视频片段中取出了音频内容。最后,数据集包含每个对话的视觉、音频和文本模式。
解释该数据集的论文可以找到 - https://arxiv.org/pdf/1810.02508.pdf
请访问 - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz 下载原始数据。数据以 .mp4 格式存储,可以在 XXX.tar.gz 文件中找到。注释可以在 https://github.com/declare-lab/MELD/tree/master/data/MELD 中找到。
| 列名 | 描述 |
|---|---|
| 先生号 | 话语序号主要用于不同版本或多副本不同子集时引用话语 |
| 发声 | 来自 EmotionLines 的个人话语作为字符串。 |
| 扬声器 | 与话语相关的说话者的姓名。 |
| 情感 | 说话者在言语中表达的情绪(中性、喜悦、悲伤、愤怒、惊讶、恐惧、厌恶)。 |
| 情绪 | 说话者在话语中表达的情绪(积极、中立、消极)。 |
| 对话ID | 对话索引从0开始。 |
| 话语ID | 对话中特定话语的索引,从 0 开始。 |
| 季节 | 季节号。特定话语所属的《老友记》电视节目。 |
| 插曲 | 剧集号。该话语所属特定季节的《老友记》电视节目。 |
| 开始时间 | 给定剧集中话语的开始时间,格式为“hh:mm:ss,ms”。 |
| 结束时间 | 给定剧集中话语的结束时间,格式为“hh:mm:ss,ms”。 |
有 13 个 pickle 文件,其中包含用于训练基线模型的数据和特征。以下是每个 pickle 文件的简要说明。
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))'./utils/' 中提供了 2 个 python 脚本:
为了进行实验,所有标签都表示为 one-hot 编码,其索引如下:
对于情绪分类的基线,使用了以下类别权重。索引与上面提到的相同。类别权重:[4.0、15.0、15.0、3.0、1.0、6.0、3.0]。
请按照以下步骤运行基线 -
./data/pickles/baseline/baseline.py如下所示:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h获取参数的帮助文本。./data/models/中。 如果您发现该数据集对您的研究有用,请引用以下论文
S. Poria、D. Hazarika、N. Majumder、G. Naik、E. Cambria、R. Mihalcea。 MELD:用于对话中情绪识别的多模式多方数据集。 2019年亚冠。
Chen, SY, Hsu, CC, Kuo, CC 和 Ku, LW EmotionLines:多方对话的情感语料库。 arXiv 预印本 arXiv:1802.08379 (2018)。
多模态 EmoryNLP 情绪检测数据集是通过增强和扩展 EmoryNLP 情绪检测数据集而创建的。它包含与 EmoryNLP 情绪检测数据集中相同的对话实例,但它还包含音频和视觉模式以及文本。多模态 EmoryNLP 数据集中存在《老友记》电视剧中的 800 多个对话和 9000 多个话语。多位发言者参与了对话。对话中的每句话都被标记为这七种情绪中的任何一种:中性、快乐、和平、强大、害怕、疯狂和悲伤。注释是从原始数据集中借用的。
| 统计数据 | 火车 | 开发者 | 测试 |
|---|---|---|---|
| 模态# | {a,v,t} | {a,v,t} | {a,v,t} |
| # 独特的单词 | 9,744 | 2,123 | 2,345 |
| 平均。话语长度 | 7.86 | 6.97 | 7.79 |
| 最大限度。话语长度 | 78 | 60 | 61 |
| 平均。每个场景的情绪数量 | 4.10 | 4.00 | 4.40 |
| 对话数量 | 第659章 | 89 | 79 |
| # 话语数 | 7551 | 第954章 | 第984章 |
| 发言者数量 | 250 | 46 | 48 |
| # 情绪转变 | 4596 | 第575章 | 第653章 |
| 平均。话语的持续时间 | 5.55秒 | 5.46秒 | 5.27秒 |
| 火车 | 开发者 | 测试 | |
|---|---|---|---|
| 快乐 | 第1677章 | 205 | 217 |
| 疯狂的 | 第785章 | 97 | 86 |
| 中性的 | 2485 | 第322章 | 288 |
| 和平 | 638 | 82 | 111 |
| 强大的 | 第551章 | 70 | 96 |
| 伤心 | 第474章 | 51 | 70 |
| 害怕的 | 第941章 | 127 | 116 |
该数据集的视频剪辑可以从此链接下载。注释文件可以在 https://github.com/SenticNet/MELD/tree/master/data/emorynlp 中找到。有 3 个 .csv 文件。这些 csv 文件第一列中的每个条目都包含一个话语,可以在此处找到其相应的视频剪辑。每个话语及其视频剪辑均按季号、集号、场景 ID 和话语 ID 进行索引。例如, sea1_ep2_sc6_utt3.mp4表示该剪辑对应于第 1 季的话语。 1,剧集编号。 2、scene_id 6和utterance_id 3。场景简单来说就是一段对话。该索引与原始数据集一致。 .csv文件和视频文件根据原始数据集分为训练集、验证集和测试集。注释直接借用自原始 EmoryNLP 数据集(Zahiri 等人(2018))。
| 列名 | 描述 |
|---|---|
| 发声 | 来自 EmoryNLP 的单个话语作为字符串。 |
| 扬声器 | 与话语相关的说话者的姓名。 |
| 情感 | 说话者在话语中表达的情绪(中性、快乐、平和、强大、害怕、疯狂和悲伤)。 |
| 场景ID | 对话索引从0开始。 |
| 话语ID | 对话中特定话语的索引,从 0 开始。 |
| 季节 | 季节号。特定话语所属的《老友记》电视节目。 |
| 插曲 | 剧集号。该话语所属特定季节的《老友记》电视节目。 |
| 开始时间 | 给定剧集中话语的开始时间,格式为“hh:mm:ss,ms”。 |
| 结束时间 | 给定剧集中话语的结束时间,格式为“hh:mm:ss,ms”。 |
注意:由于字幕不一致,有一些话语我们无法找到开始和结束时间。此类言论已从数据集中删除。然而,我们鼓励用户从原始数据集中找到相应的话语并为其生成视频剪辑。
如果您发现该数据集对您的研究有用,请引用以下论文
S.扎希里和JD Choi。使用基于序列的卷积神经网络对电视节目脚本进行情绪检测。 AAAI 情感内容分析研讨会,AFFCON'18,2018。
S. Poria、D. Hazarika、N. Majumder、G. Naik、E. Cambria、R. Mihalcea。 MELD:用于对话中情绪识别的多模式多方数据集。 2019年亚冠。


