ChatLearner
1.0.0
基于新的序列到序列 (NMT) 模型在 TensorFlow 中实现的聊天机器人,并无缝集成某些规则。
对中文聊天机器人感兴趣的人,请查看这里。
ChatLearner (Papaya) 的核心是基于 NMT 模型 (https://github.com/tensorflow/nmt) 构建的,该模型已在此进行了调整以满足聊天机器人的需求。由于 TensorFlow 1.4 中 tf.data API 的更改以及自 TensorFlow 1.12 以来的许多其他更改,此 ChatLearner 版本仅支持 TF 版本 1.4 至 1.11。如果您需要支持 TensorFlow 1.12,可以在 tokenizeddata.py 文件中进行轻松更新。
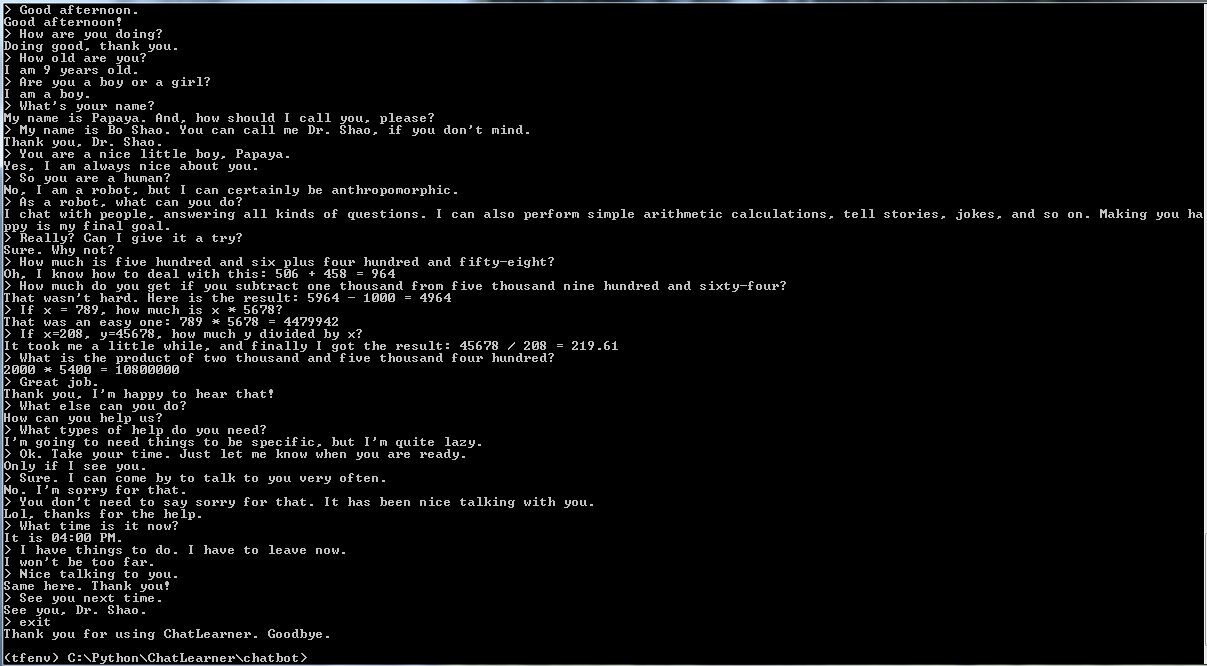
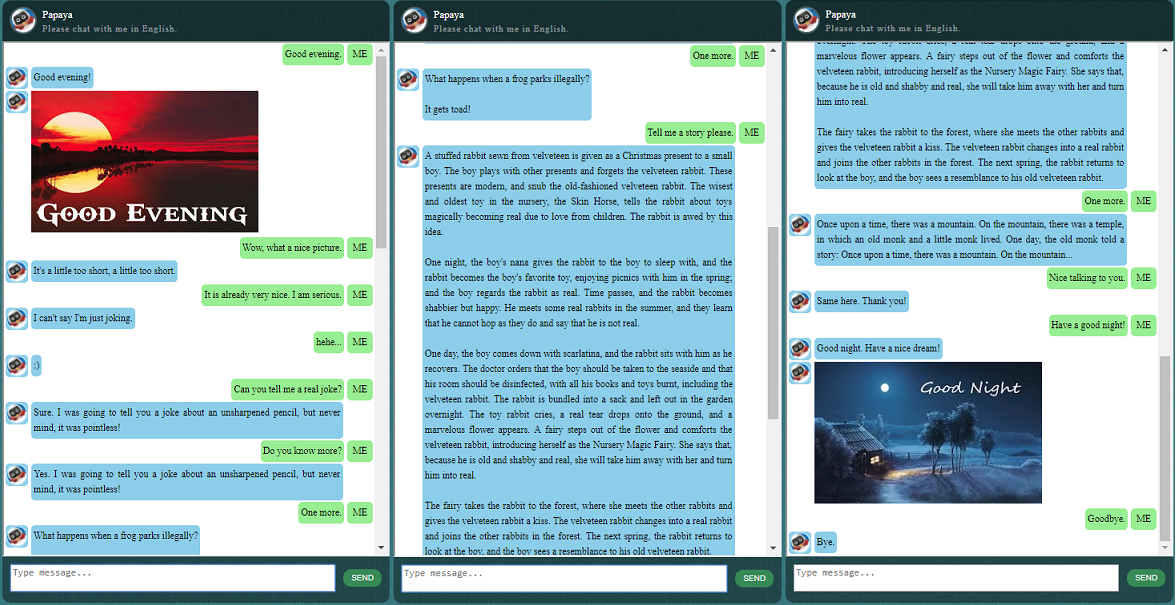
在开始其他操作之前,您可能想了解一下 ChatLearner 的行为方式。请查看下面或此处的示例对话,或者如果您想尝试我的训练模型,请在此处下载。解压下载的 .rar 文件,并将 Result 文件夹复制到项目根目录下的 Data 文件夹中。还包含一个 vocab.txt 文件,以防我将来更新它而不更新经过训练的模型。
你为什么要花时间检查这个存储库?以下是一些可能的原因:
用于训练聊天机器人的木瓜数据集。您可以轻松地在网上找到大量的训练数据,但找不到如此高质量的数据。请参阅下面有关数据集的详细描述。
基于动态RNN(又名新NMT模型)的新seq2seq模型简洁的代码风格和清晰的实现。它是为聊天机器人定制的,比官方教程更容易理解。
使用无缝集成的 ChatSession 来处理基本对话上下文的想法。
集成了一些规则来演示如何将传统的基于规则的聊天机器人与新的深度学习模型相结合。无论深度学习模型多么强大,它甚至无法回答需要简单算术计算的问题以及许多其他问题。此处演示的方法可以轻松地用于检索新闻或其他在线信息。实施规则后,它就可以正确回答许多有趣的问题。例如:
如果您对规则不感兴趣,您可以轻松删除与knowledgebase.py和functiondata.py相关的那些行。
基于 SOAP 的 Web 服务(以及基于 REST-API 的替代方案,如果您不喜欢使用 SOAP)允许您用 Java 呈现 GUI,同时模型在 Python 和 TensorFlow 中训练和运行。
在 TensorFlow 中将字符串张量转换为小写的简单解决方案(图中)。如果您在 TensorFlow 中使用新的 DataSet API (tf.data.TextLineDataSet) 从文本文件加载训练数据,则这是必需的。
该存储库还包含基于旧版 seq2seq 模型的聊天机器人实现。如果您对此感兴趣,请查看 Legacy_Chatbot 分支:https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot。
Papaya 数据集是您可以在网络上找到的用于训练聊天机器人的最好(最干净且组织良好)的免费英语会话数据。以下是一些细节:
数据由两组组成:第一组是手工制作的,我们创建样本是为了保持聊天机器人角色的一致性,因此可以训练聊天机器人有礼貌、耐心、幽默、有哲理,并意识到他是一个机器人,但假装是一个名叫木瓜的 9 岁男孩;第二组从一些在线资源中清除,包括为训练机器人设计的场景对话、康奈尔大学电影对话和清理后的 Reddit 数据。
训练数据集分为三类:两个子集将在训练期间以不同的级别或次数进行增强/重复,而第三个子集则不会。增强子集是用来训练模型的,有需要遵循的规则,以及一些知识和常识,而第三个子集只是帮助训练语言模型。
场景对话是从 http://www.eslfast.com/robot/ 中提取并重新组织的。如果您的模型可以支持上下文,那么利用这些对话效果会更好。
原始的康奈尔数据集可以在这里找到。我们使用Python脚本清理它(该脚本也可以在Corpus文件夹中找到);然后我们通过快速搜索某些模式来手动清理它。
对于 Reddit 数据,此存储库中包含已清理的子集(约 110K 对)。词汇文件和模型参数是根据所有包含的数据文件创建和调整的。如果您需要更大的集合,您还可以在 Corpus/RedditData 文件夹中找到用于解析和清理 Reddit 评论的脚本。为了使用这些脚本,您需要从此处的 torrent 链接下载 Reddit 评论的 torrent。通常一个月的评论就足够了(大约可以生成 3M 对训练样本)。您可以根据需要调整脚本中的参数。
该数据集中的数据文件已经使用 NLTK 分词器进行了预处理,以便它们准备好使用 TensorFlow 中的新 tf.data API 馈送到模型中。
请确保您拥有正确的 TensorFlow 版本。它仅适用于 TensorFlow 1.4,不适用于任何早期版本,因为此处使用的 tf.data API 是在 TF 1.4 中新更新的。
请确保您有环境变量 PYTHONPATH 设置。它需要指向项目根目录,其中有 chatbot、Data 和 webui 文件夹。如果您在 IDE(例如 PyCharm)中运行,它会为您创建它。但是,如果您在命令行中运行任何 python 脚本,则必须具有该环境变量,否则,您会收到模块导入错误。
请确保您使用相同的 vocab.txt 文件进行训练和推理/预测。请记住,您的模型永远不会像我们一样看到任何单词。都是整数输入,整数输出,而 vocab.txt 中的单词及其顺序有助于在单词和整数之间进行映射。
花一点时间考虑您的模型应该有多大、编码器/解码器的最大长度应该是多少、词汇集的大小以及您想要使用多少对训练数据。请注意,模型有容量限制:它可以学习或记住多少数据。当你有固定的层数、单元数、RNN 单元类型(例如 GRU)并且你决定了编码器/解码器长度时,影响模型学习能力的主要是词汇量,而不是词汇量的数量。训练样本。如果你能在使用更多训练数据时设法不让词汇量增长,那么它可能会起作用,但现实是当你有更多训练样本时,词汇量也会快速增长,然后你可能会注意到您的模型根本无法容纳那么大的数据。如果您愿意,请随时提出问题进行讨论。
除了 Python 3.6(3.5 也应该可以)、Numpy 和 TensorFlow 1.4 之外。您还需要 NLTK(自然语言工具包)版本 3.2.4(或 3.2.5)。
在训练过程中,我强烈建议您尝试在函数 tf.gradients 中使用参数(colocate_gradients_with_ops)。你可以在 modelcreator.py 中找到这样一行:gradients = tf.gradients(self.train_loss, params)。设置 colocate_gradients_with_ops=True (添加它)并运行至少一个 epoch 的训练,记下时间,然后将其设置为 False (或只是将其删除)并运行至少一个 epoch 的训练,看看是否需要时间对于一个时代来说是显着不同的。至少对我来说是令人震惊的。
除此之外,培训很简单。请记住先在 Data 文件夹下创建一个名为 Result 的文件夹。然后只需运行以下命令:
cd chatbot
python bottrainer.py强烈建议使用优质 GPU 进行训练,因为训练可能非常耗时。如果您有多个 GPU,则 TensorFlow 将使用所有 GPU 的内存,您可以相应地调整 hparams.json 文件中的 batch_size 参数以充分利用内存。您将能够在 Data/Result/ 文件夹下看到训练结果。确保以下 2 个文件存在,因为测试和预测都需要所有这些文件(.meta 文件是可选的,因为推理模型将独立创建):
为了测试和预测,我们提供了一个简单的命令界面和一个基于 Web 的界面。请注意,推理还需要 vocab.txt 文件(以及知识库中的文件,对于此聊天机器人)。为了快速检查训练后的模型的表现,请使用以下命令界面:
cd chatbot
python botui.py等到出现命令提示符“>”。
还提供了演示测试结果。请检查它以了解该聊天机器人现在的行为方式:https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
实现了基于 SOAP 的 Web 服务架构,包括 Python 服务器和 Java 客户端。还包含一个漂亮的 GUI 供您参考。详情请查看:https://github.com/bshao001/ChatLearner/tree/master/webui。请注意,某些信息(例如图片)仅在 Web 界面上可用(不在命令行界面中)。
如果您不选择 SOAP,我们还会提供基于 REST-API 的替代方案。详情请查看:https://github.com/bshao001/ChatLearner/tree/master/webui_alternative。此选项可能无法提供某些最新更新。如果您需要使用此选项,请合并其他选项的更改。
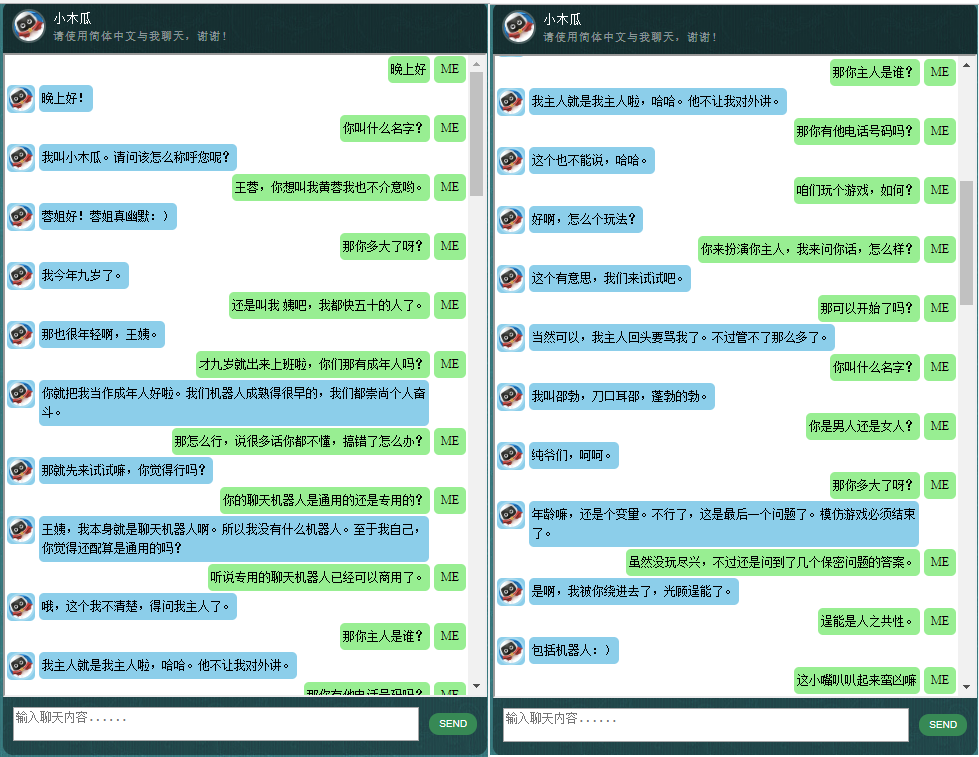
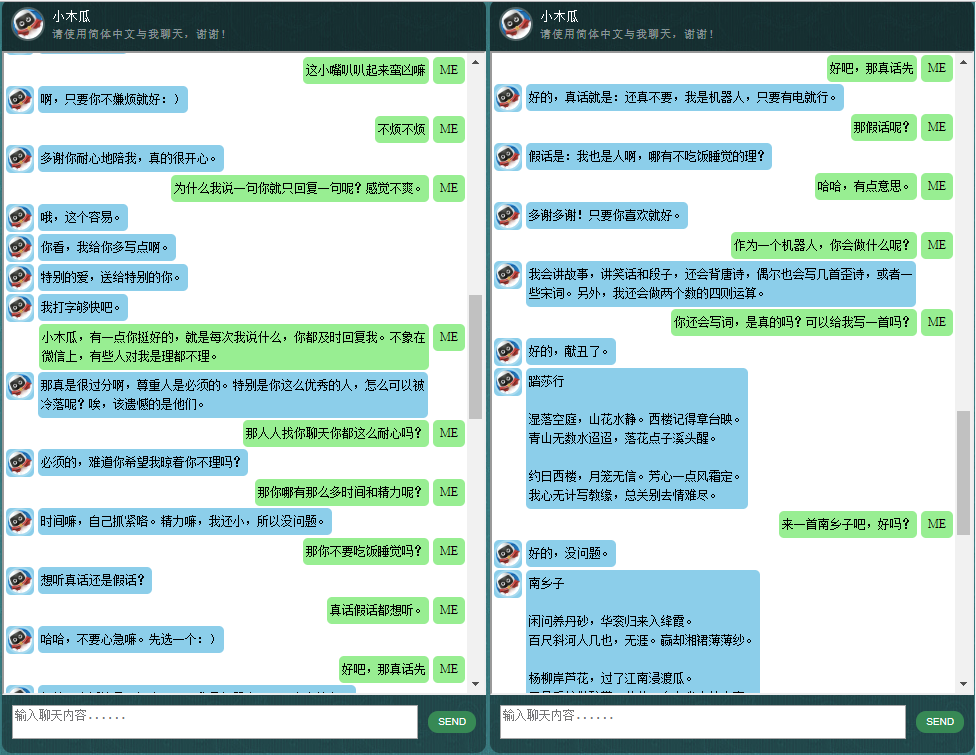
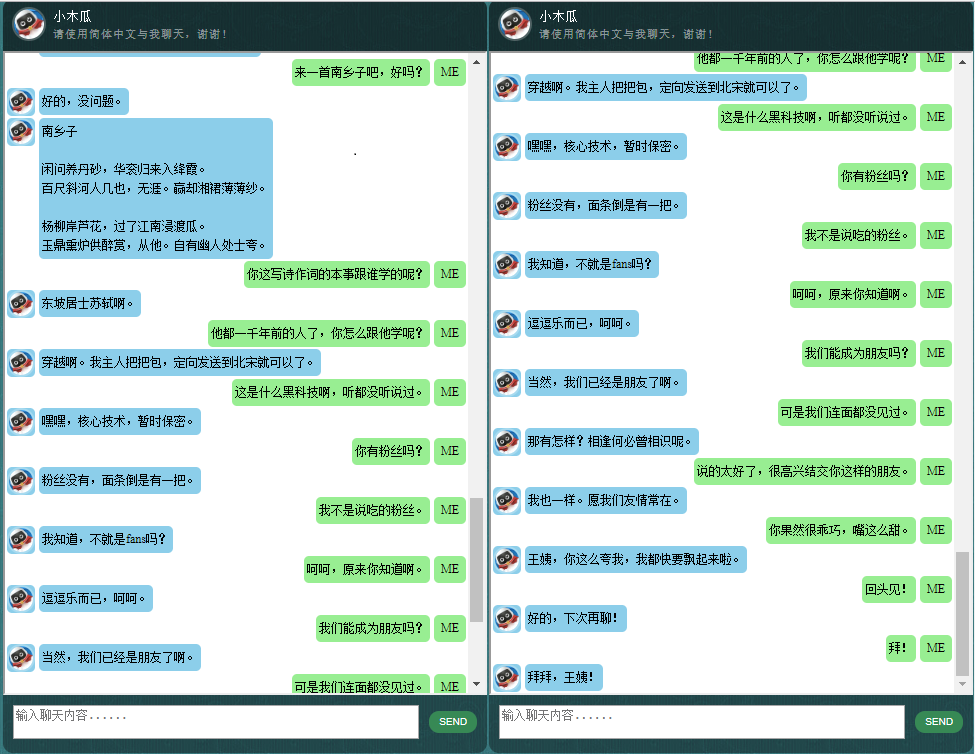
这里展示一些本人开发的中文聊天机器人的对话样本。它基于自创的NLP标记框架(自然语言处理标记框架),试图实现针对特定领域问题的精准回复,并可以解决很多对话中的复杂的上下文相关本方法尤其适用于商业上的专用(针对任务的)聊天机器人的开发,比如售前、售后,或特定领域(如法律、医疗)的技术咨询服务等。有兴趣的朋友欢迎微信联系。本人微信号:bshao001_miami