gutenberg dialog
1.0.0
用于下载和构建您自己的古腾堡对话数据集版本的代码。可以使用新语言轻松扩展。在这里尝试训练有素的各种语言的聊天机器人:https://ricsinaruto.github.io/chatbot.html。
| 下载链接 | 话语数 | 平均话语长度 | 对话数量 | 平均对话长度 |
|---|---|---|---|---|
| 英语 | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| 德语 | 226 015 | 24.44 | 43 440 | 5.20 |
| 荷兰语 | 129 471 | 24.26 | 23 541 | 5.50 |
| 西班牙语 | 58 174 | 18.62 | 6 912 | 8.42 |
| 意大利语 | 41 388 | 19.47 | 6664 | 6.21 |
| 匈牙利 | 18816 | 14.68 | 2 826 | 6.66 |
| 葡萄牙语 | 16228 | 21.40 | 2233 | 7.27 |
? 通过调整影响数据集大小与质量权衡的参数来生成您自己的数据集
模块化接口可以轻松地将数据集扩展到其他语言
? 您可以在构建数据集时轻松手动排除书籍
运行 setup.py 安装所需的包。
python setup.py
应从存储库的根目录调用主文件。下面的命令为作为参数给出的逗号分隔语言运行数据集构建管道。目前支持英语、德语、荷兰语、西班牙语、葡萄牙语、意大利语和匈牙利语。
python code/main.py -l=en,de,nl,es,pt,it,hu -a
所有可设置的参数如下所示: 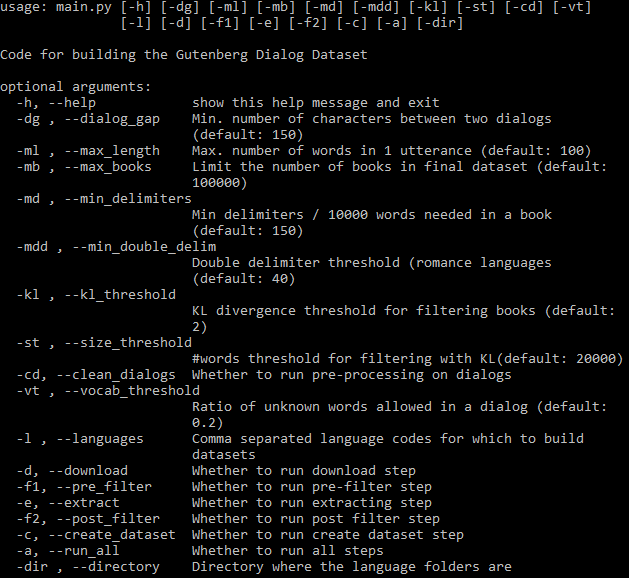
-a标志控制是否自动运行整个管道。如果省略-a,则必须使用标志指定步骤子集(请参阅上面的帮助)。步骤完成后,其输出可在后续步骤中使用,并且仅当与该步骤相关的参数或代码发生更改时,它才会再次运行。所有步骤针对每种语言单独运行。
下载给定语言的书籍。
注意:如果所有书籍都无法下载,并出现错误“无法下载书籍”,可能的原因是gutenberg包使用的默认镜像无法访问。如果发生这种情况,可以通过GUTENBERG_MIRROR环境变量使用 https://www.gutenberg.org/MIRRORS.ALL 中列出的任何备用镜像。例如:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
预过滤去除一些旧书和噪音。
对话是从书中摘录的。将数据集扩展到新语言时(请参阅下面的部分),这是可以修改的步骤,因此完成后可以跳过前面的步骤。
第二个过滤步骤是根据词汇删除一些对话。
将最终数据集放在一起并分成训练/开发/测试数据。最后一步在输出目录中创建author_and_title.txt文件,其中包含用于提取最终数据集的所有书籍(加上标题和作者)。用户可以手动将此文件中的行复制到与数据集中不应允许的书籍相对应的banned_books.txt 。在任何步骤的后续运行中,将不会考虑此文件中的书籍。
该代码可以轻松扩展以处理其他语言。必须在 languages 文件夹中创建名为 <语言代码>.py 的文件。这里应该定义一个类,命名为大写语言代码(例如En代表英语),以 LANG 或任何其他子类作为父类。通过self.cfg可以访问配置参数。在这个类中必须定义以下 3 个函数。请参阅 it.py 作为示例。
语言统计
此函数应返回一个字典,其中键是潜在的分隔符。对于每个分隔符,应该定义一个函数(字典中的值),该函数将一行作为输入并返回一个数字。该数字可以是例如分隔符的计数、行中是否有分隔符的标志等。通常建议加权计数,具体取决于不同分隔符的重要性。这些值将用于确定应在相应书籍中使用的分隔符(传递给下面的函数),并用于过滤包含少量分隔符的书籍。 en.py 包含多个分隔符的示例。
该函数应该从书中提取对话并将其附加到self.dialogs中,这是一个对话列表,每个对话都是连续话语的列表。 paragraph_list将书籍包含为连续段落的列表。分隔符是此文件中最常见的分隔符,应用于提取对话框。
该函数用于后处理对话框(例如删除某些字符)。它以话语作为输入。请注意,nltk 单词标记化是自动运行的。
该项目根据 MIT 许可证获得许可 - 有关详细信息,请参阅许可证文件。
如果您在工作中使用任何数据集或代码,请包含此存储库的链接,并考虑引用以下论文:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


