rasa ptbr boilerplate
1.0.4
英文版:README-en
该样板是作为 Tais 项目的通用抽象而诞生的。如今,它的目标是让创建 Rasa 聊天机器人变得更容易。随着框架的发展,目前样板的重点是实时代码文档。
在这里您可以找到完全使用巴西葡萄牙语的聊天机器人,它将帮助您提供对话、代码和 Rasa 功能的使用示例。
样板架构可分为 2 个主要部分:
将.yml配置文件转换为包含聊天机器人智能的modelo treinado的过程。
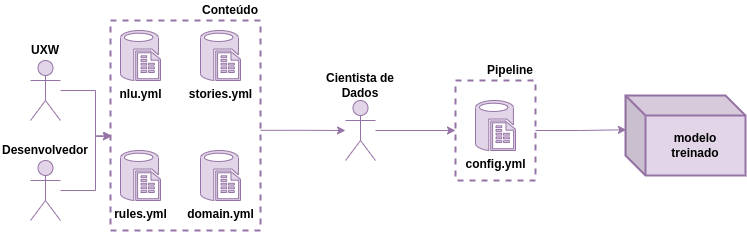
用户通过 Telegram 与 Boilerplate 进行交互,Telegram 通过连接器向 Rasa NLU 发送消息,在其中识别意图,并根据故事和操作通过 Rasa Core 进行响应。
用于对话的模型由训练器模块生成,然后传输到机器人。这些模型可以在机器人之间进行版本控制和演化。
首先,使用以下命令将存储库克隆到本地计算机:
git clone https://github.com/lappis-unb/rasa-ptbr-boilerplate.git要让 Rasa 聊天机器人正常工作,请确保您位于项目文件夹中,然后在终端中运行以下命令:
make init此命令将构建必要的基础设施(上传具有依赖项的容器、训练聊天机器人并在 shell 模式下启动聊天)以启用与聊天机器人的交互。
安装完所有内容后,您将看到以下消息并可以开始与机器人交互:
Bot loaded. Type a message and press enter (use ' /stop ' to exit):
Your input - >要关闭与机器人的交互,只需输入ctrl+c 。
make trainmake shell完成所有必要环境变量的导出教程后,您可以在 Telegram 上正确运行机器人。
在继续之前。重要提示:环境变量对于机器人正常运行是必要的,所以不要忘记导出它们。
然后在 Telegram 上运行机器人:
make telegram为了可视化用户和聊天机器人之间的交互数据,我们使用了 Elastic Stack 的一部分,由 ElasticSearch 和 Kibana 组成。因此,我们使用代理来管理消息。因此,无论我们使用哪种类型的信使,我们都可以向 ElasticSearch 添加消息。
make build-analytics等待ElasticSearch服务准备就绪,然后运行以下命令配置索引:
make config-elastic
等待Kibana服务准备就绪,然后运行以下命令来配置仪表板:
make config-kibana
上述命令只需执行一次,整个analytics基础设施就可供使用。
通过 URL locahost:5601访问kibana
如果您想了解分析堆栈配置过程,请参阅完整的分析说明。
Rasa 允许您将自定义模块添加到处理管道中,请在此处了解更多信息。
这里有一个实现情感分析的自定义组件的示例。
要使用它,只需将components.sentiment_analyzer.SentimentAnalyzer组件引入bot/config.yml文件即可。如示例所示:
language : "pt"
pipeline:
- name: WhitespaceTokenizer
- name: "components.sentiment_analyzer.SentimentAnalyzer" - name: RegexFeaturizer
然后,如bot/components/labels.yml文件示例中所示,添加与标签(评级或情绪)相对应的短语。
最后,再次训练机器人,如果组件识别出该实体的值,则信息将存储在sentiment实体中。
提起notebooks容器
make notebooks通过localhost:8888访问笔记本
项目文档可以使用 GitBook 在本地运行。要通过 npm 安装 gitbook,您需要在计算机上安装 Node.js 和 npm。
npm install -g gitbook gitbook-cligitbook build .gitbook serve . http://localhost:4000/
贡献:要为项目文档做出贡献,请阅读如何为文档做出贡献
Tais 框架的部分技术文档可在存储库的 wiki 上找到。如果您找不到答案,请使用duvida标签提出问题,我们将尽力尽快回复。
如果您对 Rasa 有任何疑问,请参阅 Rasa Stack Brasil Telegram 群组,我们也随时为您提供帮助。
请在我们的网站上查看更多联系信息:https://lappis.rocks。
整个样板框架是在 GPL3 许可证下开发的
请参阅此处的许可证依赖项列表


