Seq2seqChatbots
1.0.0
tensor2tensor 的包装器,用于灵活地训练、交互和生成神经聊天机器人的数据。
该 wiki 包含我对 150 多篇与神经对话建模相关的最新出版物的笔记和摘要。
? 运行您自己的训练或使用预先训练的模型进行实验
✅ 与tensor2tensor集成的4个不同的对话数据集
? 与tensor2tensor中设置的任何模型或超参数无缝配合
可轻松扩展对话框问题的基类
运行 setup.py,它会安装所需的软件包并引导您下载其他数据:
python setup.py
您可以从此处下载本文中使用的所有经过训练的模型。每次训练包含两个检查点,一个用于验证损失最小值,另一个在 150 个时期之后。数据和训练文件夹结构彼此完全匹配。
python t2t_csaky/main.py --mode=train
mode 参数可以是以下四种之一: {generate_data, train,decode,experiment} 。在实验模式下,您可以指定运行文件的实验函数内要执行的操作。下面详细解释了每种模式的作用。
您可以直接在此文件中控制每种模式的标志和参数。对于您启动的每次运行,此文件都将被复制到相应的目录,以便您可以快速访问任何运行的参数。您必须为每种模式设置一些标志(配置文件中的FLAGS字典):
t2t_usr_dir :我的代码所在目录的路径。您不必更改此设置,除非您重命名该目录。
data_dir :要在其中生成源和目标对以及其他数据的目录的路径。数据集将从该目录更高一级下载到raw_data文件夹中。
Problem :这是tensor2tensor需要的已注册问题的名称。详细信息请参见下面的generate_data部分。所有路径都应来自存储库的根目录。
此模式将下载并预处理数据并生成源和目标对。目前,除了tensor2tensor给出的问题之外,还有6个已注册的问题可以使用:
persona_chat_chatbot :此问题实现了 Persona-Chat 数据集(不使用角色)。
daily_dialog_chatbot :此问题实现了 DailyDialog 数据集(不使用主题、对话行为或情感)。
opensubtitles_chatbot :此问题可用于处理 OpenSubtitles 数据集。
cornell_chatbot_basic :此问题实现了康奈尔电影对话语料库。
cornell_chatbot_separate_names :此问题使用相同的康奈尔语料库,但是附加了每个话语的说话者和收件人的姓名,从而产生如下所示的源话语。
BIANCA_m0 有什么好东西? 卡梅伦_m0
character_chatbot :这是一个基于字符的通用问题,适用于任何数据集。在使用此问题之前,必须将上述任何问题生成的.txt文件放置在数据目录中,之后可以使用此问题生成tensor2tensor基于字符的数据文件。
配置文件中的PROBLEM_HPARAMS字典包含您可以在生成数据之前设置的问题特定参数:
num_train_shards / num_dev_shards :如果您希望将生成的训练或开发数据分片到多个文件中。
vocabulary_size :我们要用于解决问题的词汇量的大小。该词汇表之外的单词将被替换为标记。
dataset_size :话语对的数量,如果我们不想使用完整的数据集(由 0 定义)。
dataset_split :指定问题的训练-验证-测试分割。
dataset_version :这仅与 opensubtitles 数据集相关,因为该数据集有多个版本,您可以指定要下载的数据集的年份。
name_vocab_size :这仅与具有单独名称的康奈尔问题相关。您可以设置仅包含角色的词汇表的大小。
此模式允许您使用指定的问题和超参数训练模型。该代码仅调用tensor2tensor训练脚本,因此可以使用tensor2tensor中的任何模型。除此之外,还有一个经过小修改的子类模型:
gradient_checkpointed_seq2seq :对基于 lstm 的 seq2seq 模型进行小修改,以便可以完全使用自己的 hparams。在计算 softmax 之前,LSTM 隐藏单元被投影为 2048 个线性单元,如下所示。最后,我尝试对此模型实现梯度检查点,但目前它已被删除,因为它没有给出良好的结果。
您可以在配置文件的FLAGS字典中为训练运行指定几个附加标志,其中一些是:
train_dir :保存训练检查点文件的目录名称。
model :模型名称:以上之一或tensor2tensor定义的模型。
hparams :指定已注册的 hparams_set,或者如果要在配置文件中定义 hparams,则保留为空。为了为seq2seq或Transformer模型指定 hparams,您可以在配置文件中使用SEQ2SEQ_HPARAMS和TRANSFORMER_HPARAMS字典(查看更多详细信息)。
使用此模式,您可以从经过训练的模型中进行解码。以下参数影响解码(在配置文件的FLAGS字典中):
解码模式:可以是交互式的,您可以使用命令行与模型聊天。文件模式允许您指定一个包含要生成响应的源话语的文件,数据集模式将对提供的验证数据进行随机采样并输出响应。
decode_dir :您可以提供要解码的文件的目录,输出的响应将保存在此处。
input_file_name :您必须在文件模式下提供的文件的名称(放置在decode_dir中)。
output_file_name : decode_dir内的文件名,输出响应将保存在其中。
beam_size :使用波束搜索时波束的大小。
return_beams :如果为 False,则仅返回顶部梁,否则返回beam_size梁数。
以下结果来自这两篇论文。
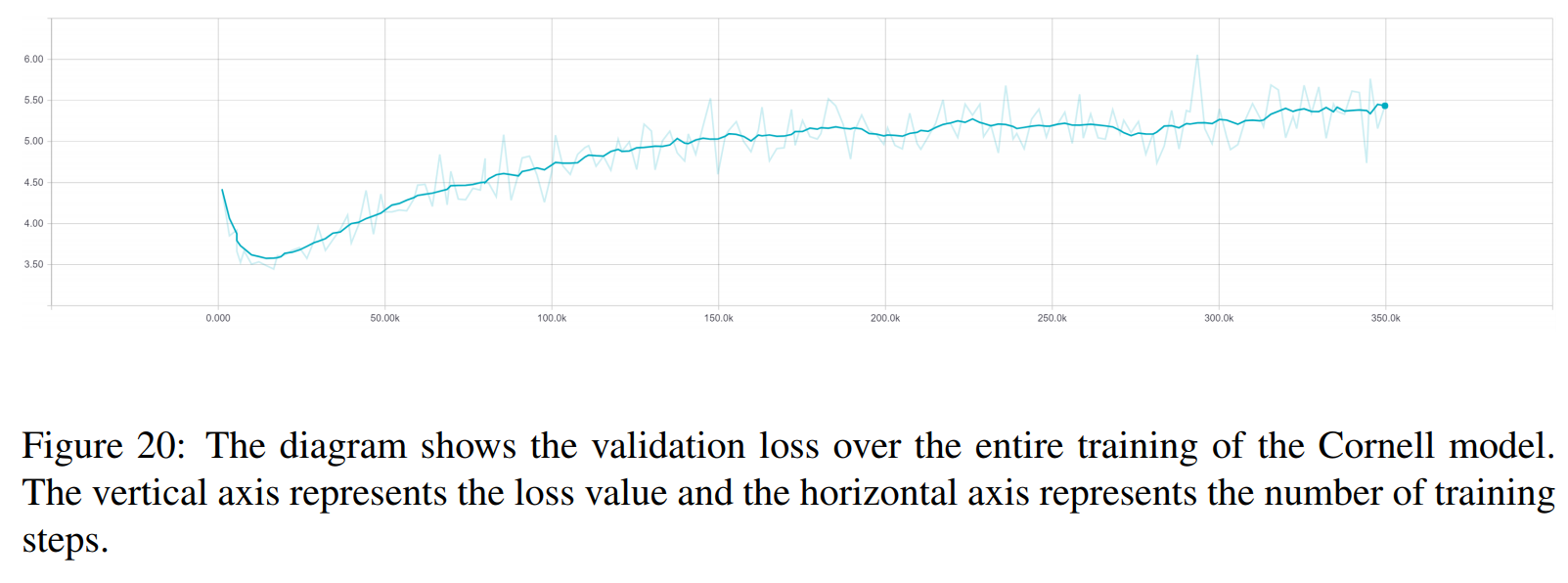

TRF 是 Transformer 模型,RT 是指从训练集中随机选择的响应,GT 是指真实响应。有关指标的说明,请参阅论文。
S2S 是一个简单的 seq2seq 模型,其中 LSTM 在 Cornell 上训练,其他是 Transformer 模型。 Opensubtitles F 在 Opensubtitles 上进行了预训练,并在 Cornell 上进行了微调。 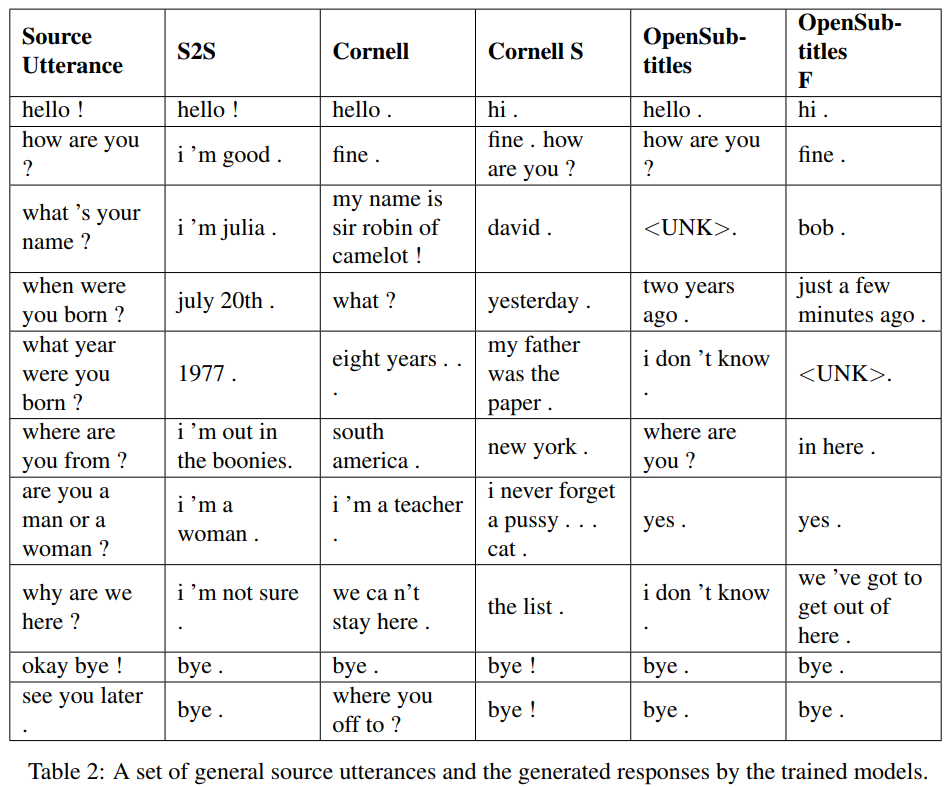
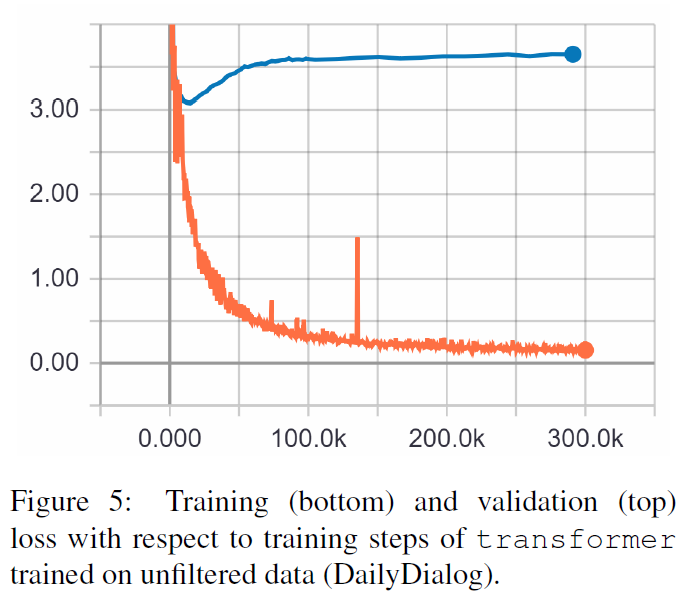

TRF 是 Transformer 模型,RT 是指从训练集中随机选择的响应,GT 是指真实响应。有关指标的说明,请参阅论文。
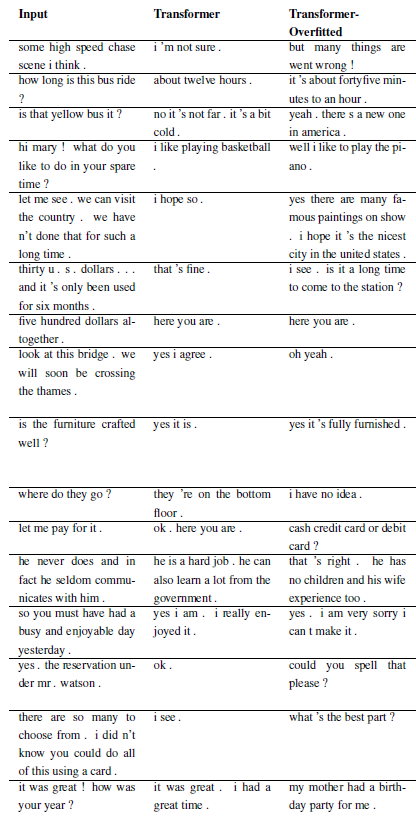
新问题可以通过子类化 WordChatbot 来注册,或者甚至更好地子类化 CornellChatbotBasic 或 OpensubtitleChatbot,因为它们实现了一些附加功能。通常覆盖preprocess和create_data函数就足够了。检查文档以获取更多详细信息,并参阅 daily_dialog_chatbot 以获取示例。
可以按照tensor2tensor教程添加新模型和超参数。
Richard Csaky (如果您在运行代码时需要任何帮助:[email protected])
该项目根据 MIT 许可证获得许可 - 有关详细信息,请参阅许可证文件。
如果您在工作中使用该存储库,请包含该存储库的链接,并考虑引用以下论文:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

