turing
v0.3.8
Viglet Turing ES(https://openviglet.github.io/turing/)是一个开源解决方案(https://github.com/openturing),其主要功能是语义导航和聊天机器人。您可以从多个 NLP 中进行选择来丰富数据。所有内容都在 Solr 作为搜索引擎中建立索引。
有关 Turing ES 的技术文档可在 https://openviglet.github.io/docs/turing/ 获取。
要运行 Turing ES,只需执行以下几行:
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# 使用 Angular 18 和 Primer CSS 的新 Turing ES UI.cd turing-ui## 欢迎登录## Consoleng 服务 console## Searchng 服务 sn## 聊天 botng 服务 converse
您可以使用 MariaDB、Solr 和 Nginx 启动 Turing ES。
docker-compose up
管理控制台:http://localhost:2700。 (管理员/管理员)
语义导航示例:http://localhost:2700/sn/Sample。
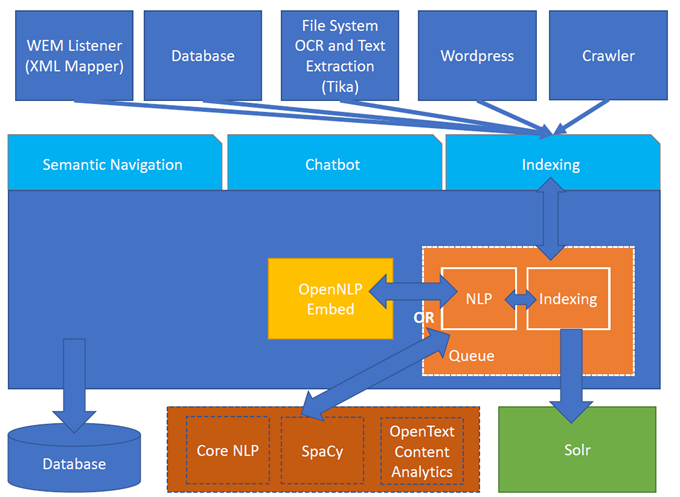
图 1. Turing ES 架构
图灵支持以下提供商:
Apache OpenNLP 是一个基于机器学习的工具包,用于处理自然语言文本。
网站:https://opennlp.apache.org/
它将数据转化为见解,以实现更好的决策和信息管理,同时释放资源和时间。
网站:https://www.opentext.com/
CoreNLP 是您使用 Java 进行自然语言处理的一站式商店! CoreNLP 使用户能够导出文本的语言注释,包括标记和句子边界、词性、命名实体、数字和时间值、依赖和选区解析、共指、情感、引用归因和关系。 CoreNLP目前支持6种语言:阿拉伯语、中文、英语、法语、德语和西班牙语。
网站:https://stanfordnlp.github.io/CoreNLP/,
它是一个用于 Python 自然语言处理的免费开源库。它具有 NER、POS 标记、依存分析、词向量等功能。
网站:https://spacy.io
Polyglot 是一种支持大规模多语言应用程序的自然语言管道。
网站:https://polyglot.readthedocs.io
它可以读取 PDF 和文档并转换为纯文本,还可以使用 OCR 检测图像中的文本以及将图像转换为文档。
语义导航使用连接器对来自多个来源的内容进行索引。
Apache Nutch 的插件,用于使用爬虫索引内容。
了解更多信息,请访问 https://docs.viglet.com/turing/connectors/#nutch
使用与 sqoop (https://sqoop.apache.org/) 相同概念的命令行来创建复杂查询并根据结果将属性映射到索引。
了解更多信息,请访问 https://docs.viglet.com/turing/connectors/#database
命令行索引文件,通过 OCR 从 Word、Excel、PDF(包括图像)等文件中提取文本。
了解更多信息,请访问 https://docs.viglet.com/turing/connectors/#file-system
OpenText WEM Listener,用于将内容发布到 Viglet Turing。
了解更多信息,请访问 https://docs.viglet.com/turing/connectors/#wem
WordPress 插件允许您为帖子建立索引。
了解更多信息,请访问 https://docs.viglet.com/turing/connectors/#wordpress
通过 NLP,可以检测以下实体:
人们
地点
组织机构
钱
时间
百分比
定义将用作导航过滤器的属性,整合显示中的全部内容
通过内容中定义的属性,可以使用它们根据用户的配置文件限制其显示。
Java API (https://github.com/openturing/turing-java-sdk) 方便了 Viglet Turing ES 的使用和访问,无需消费者通过复杂的查询来搜索内容。
与您的客户沟通并阐述复杂的意图,获取报告并逐步发展您的互动。
其组成部分:
处理与最终用户的对话。它是一个自然语言处理模块,可以理解人类语言的细微差别
意图对最终用户进行对话转移的意图进行分类。对于每个代理,您定义多个意图,其中组合的意图可以处理完整的对话。
操作字段是一个简单的方便字段,有助于执行服务中的逻辑。
每个意图参数都有一个类型,称为实体类型,它准确地指示如何提取最终用户表达式中的数据。
定义并纠正意图。
显示对话历史记录和报告。
Turing ES 使用 OCR 和 NLP 检测 OpenText Blazon 文档的实体,生成 Blazon XML 以将实体显示到文档中。
Turing ES 有很多组件:搜索引擎、NLP、Converse(聊天机器人)、语义导航
访问Turing ES时,会出现登录页面。默认情况下,登录名/密码是admin / admin
图 2. 登录页面
Turing 使用搜索引擎来存储和检索 Converse(聊天机器人)和语义导航站点的数据。
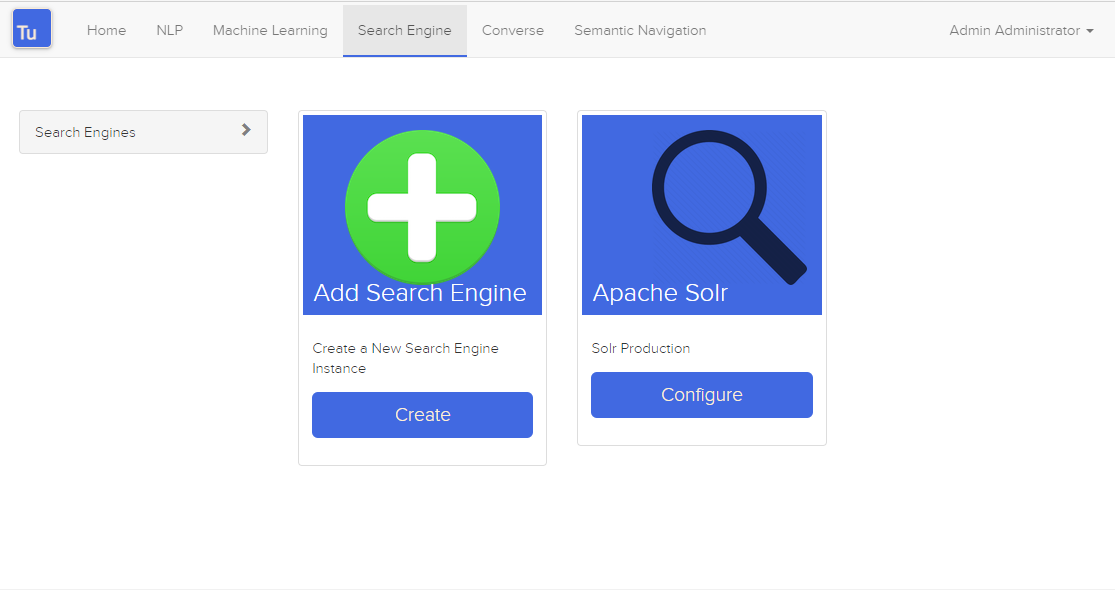
图 3. 搜索引擎页面
可以创建或编辑具有以下属性的搜索引擎:
| 属性 | 描述 |
|---|---|
姓名 | 搜索引擎名称 |
描述 | 搜索引擎说明 |
小贩 | 选择搜索引擎的供应商。目前,它仅支持 Solr。 |
主持人 | 安装搜索引擎服务的主机名 |
港口 | 搜索引擎服务端口 |
语言 | 搜索引擎服务的语言。 |
启用 | 如果搜索引擎已启用。 |
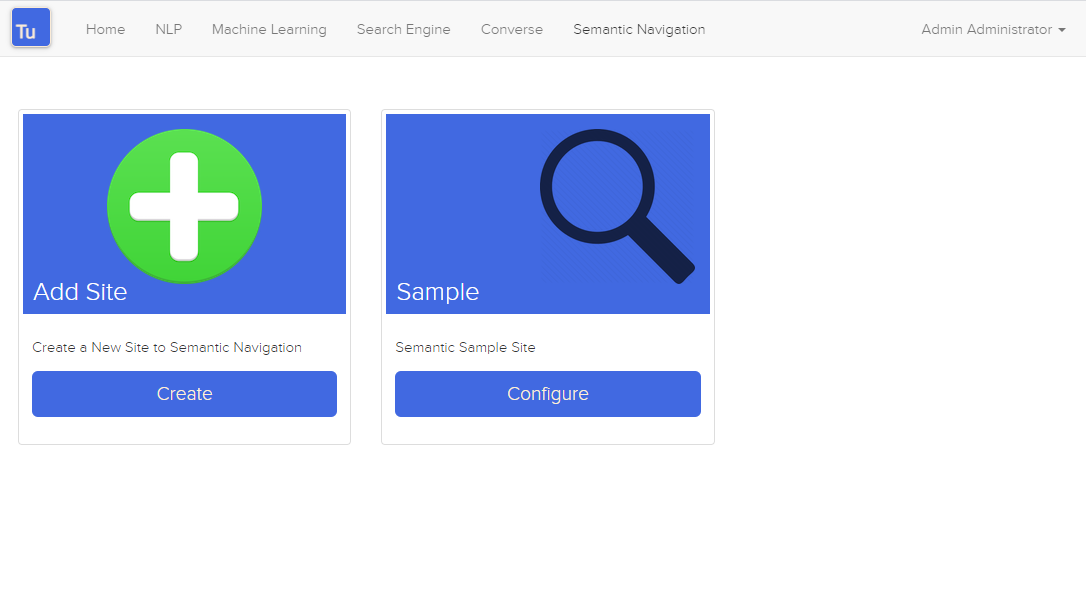
图 4. 语义导航页面
语义导航站点的详细信息包含以下属性:
| 属性 | 描述 |
|---|---|
姓名 | 语义导航站点的名称。 |
描述 | 语义导航站点的描述。 |
搜索引擎 | 选择在搜索引擎部分中创建的搜索引擎。语义导航站点将使用该搜索引擎来存储和检索数据。 |
自然语言处理 | 选择在 NLP 部分中创建的 NLP。语义导航站点将使用此 NLP 在索引期间检测实体。 |
同义词库 | 如果您使用同义词库。 |
语言 | 语义导航站点的语言。 |
核 | 将存储和检索数据的搜索引擎核心的名称。 |
字段选项卡包含一个包含以下列的表: .语义导航站点字段列
| 列名 | 描述 |
|---|---|
类型 | 字段类型。它可以是: - NLP 使用的 NER(命名实体识别)。 - Solr 使用的搜索引擎。 |
场地 | 字段名称。 |
启用 | 该字段是否启用。 |
MLT | 如果该字段将在 MLT 中使用。 |
刻面 | 将此字段用作构面(过滤器) |
突出显示 | 如果该字段将显示突出显示的行。 |
自然语言处理 | 该字段是否由 NLP 处理以检测实体 (NER),例如人员、组织和地点。 |
单击字段时,会出现一个新页面,其中包含具有以下属性的字段详细信息:
| 属性 | 描述 |
|---|---|
姓名 | 字段名称 |
描述 | 字段描述 |
类型 | 字段类型。它可以是: |
多值 | 如果是一个数组 |
构面名称 | 搜索页面上构面(过滤器)的标签名称。 |
刻面 | 将此字段用作构面(过滤器) |
突出显示 | 如果该字段将显示突出显示的行。 |
MLT | 如果该字段将在 MLT 中使用。 |
启用 | 如果该字段已启用。 |
必需的 | 如果需要该字段。 |
默认值 | 如果内容在没有这些字段的情况下被索引,那就是默认值。 |
自然语言处理 | 该字段是否由 NLP 处理以检测实体 (NER),例如人员、组织和地点。 |
包含以下属性:
| 部分 | 属性 | 描述 |
|---|---|---|
外貌 | 每页的项目数 | 将出现在搜索中的项目数。 |
刻面 | 启用方面? | 如果它将在搜索中显示 Facet(过滤器)。 |
每个方面的项目数 | 将出现在每个方面(过滤器)中的项目数。 | |
突出显示 | 突出显示已启用? | 定义是否显示突出显示的行。 |
预标签 | 将在学期开始时使用的 HTML 标签。例如:<标记> | |
发布标签 | 将在学期结束时使用的 HTML 标签。例如:</标记> | |
MLT | 启用更多类似功能? | 定义是否显示MLT |
默认字段 | 标题 | 将用作 Solr schema.xml 中定义的标题的字段 |
文本 | 将用作 Solr schema.xml 中定义的标题的字段 | |
描述 | 将用作 Solr schema.xml 中定义的描述的字段 | |
日期 | 将用作 Solr schema.xml 中定义的日期的字段 | |
图像 | 将用作 Solr schema.xml 中定义的图像 URL 的字段 | |
网址 | 将用作 Solr schema.xml 中定义的 URL 的字段 |
在Turing ES Console > Semantic Navigation > <SITE_NAME>中,单击Configure按钮,然后单击Search Page按钮。
它将打开一个使用以下模式的搜索页面:
获取 http://localhost:2700/sn/<SITE_NAME>
此页面通过 AJAX 请求 Turing Rest API。例如,以 JSON 格式返回语义导航站点的所有结果:
获取 http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| 属性 | 必需/可选 | 描述 | 例子 |
|---|---|---|---|
q | 必需的 | 搜索查询。 | q=foo |
p | 必需的 | 页码,第一页为 1。 | p=1 |
种类 | 必需的 | 排序值: | 排序=相关性 |
fq[] | 选修的 | 查询字段。使用以下模式按字段过滤: FIELD : VALUE 。 | fq[]=标题:栏 |
tr[] | 选修的 | 目标规则。限制搜索基于: FIELD : VALUE 。 | tr[]=部门:foobar |
行 | 选修的 | 查询将返回的行数。 | 行=10 |
在保险公司的内部网上,使用 OpenText WEM 和与动态门户模块集成的 OpenText Portal,使用连接器:WEM、带文件系统的数据库在 Viglet Turing ES 中创建综合搜索。通过这种方式,可以显示搜索内联网的所有内容和文件,并具有定向规则,只允许显示用户有权访问的内容。 OpenText Portal 访问 Viglet Turing ES Java API,因此无需创建复杂的查询来返回结果。
创建了一组 API Rest,以使所有政府公司内容可供合作伙伴使用。所有这些内容都在 OpenText WEM 中,并且使用 WEM 连接器在 Viglet Turing ES 上对内容进行索引。 Spring Boot 应用程序是使用 Rest API 集创建的,该应用程序通过 Viglet Turing ES Java API 使用 Turing ES 内容。
巴西大学网站是使用Viglet Shio CMS (https://viglet.com/shio)开发的,所有内容都在Viglet Turing ES中自动索引。此配置是在内容建模中进行的,搜索模板的开发是在 Viglet Shio CMS 中进行的。


