GenDataAttribution
1.0.0
项目|纸
王胜宇1 , Alexei A. Efros 2 , 朱俊彦1 , 张理查德3 .
卡内基梅隆大学1 , 加州大学伯克利分校2 , Adobe 研究中心2
在 ICCV,2023 年。
虽然大型文本到图像模型能够合成“新”图像,但这些图像必然是训练数据的反映。此类模型中的数据归因问题(训练集中的哪些图像对给定生成图像的外观负有最大责任)是一个困难但重要的问题。作为解决这个问题的第一步,我们通过“定制”方法评估归因,该方法将现有的大规模模型调整为给定的示例对象或风格。我们的主要见解是,这使我们能够有效地创建合成图像,这些图像在计算上受到构造示例的影响。利用此类受样本影响的图像的新数据集,我们能够评估各种数据归因算法和不同的可能特征空间。此外,通过对我们的数据集进行训练,我们可以针对归因问题调整标准模型,例如 DINO、CLIP 和 ViT。尽管该过程针对小型样本集进行了调整,但我们仍展示了对较大样本集的泛化。最后,通过考虑问题固有的不确定性,我们可以在一组训练图像上分配软归因分数。
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh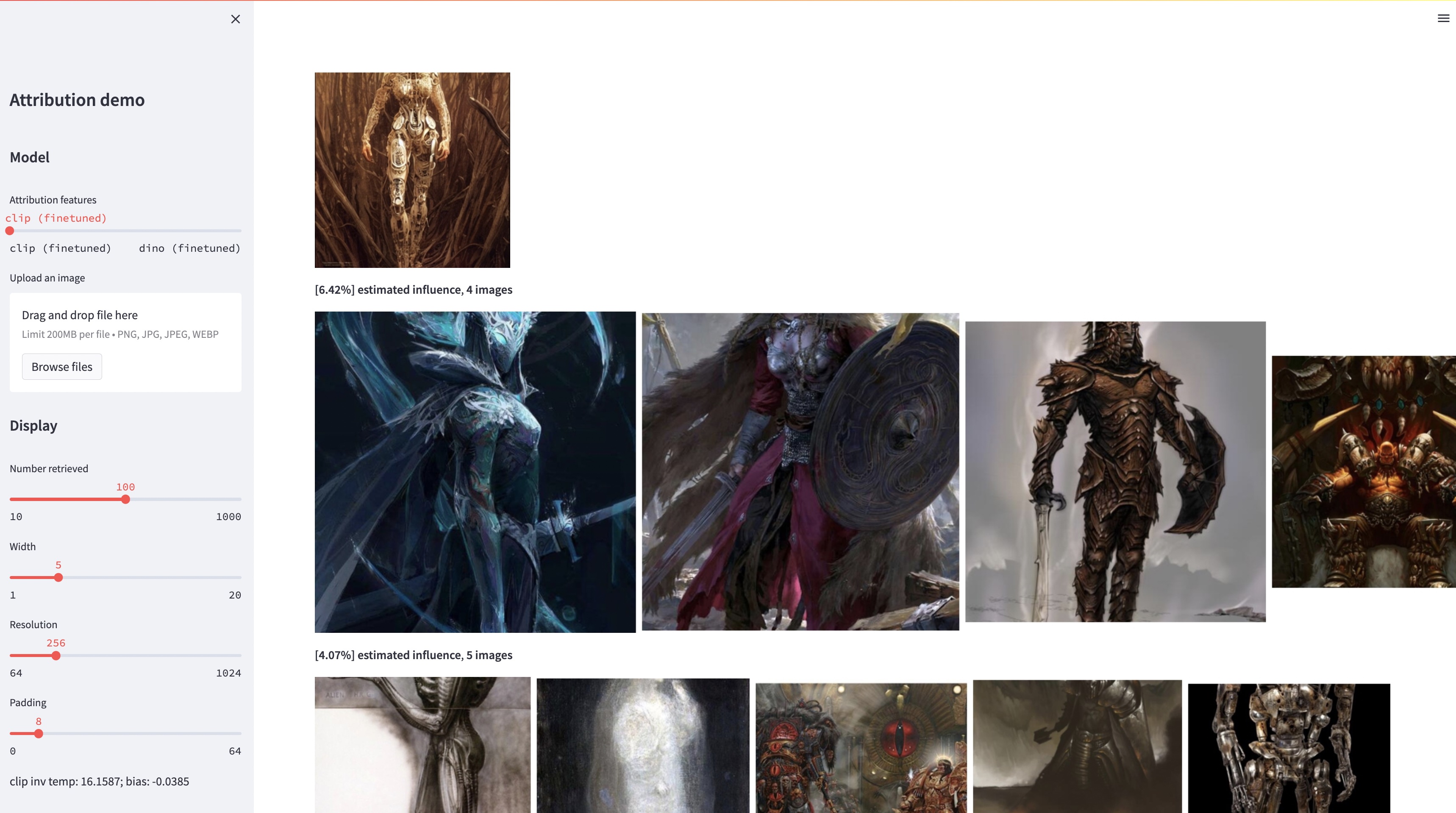
streamlit run streamlit_demo.py我们发布测试集进行评估。下载数据集:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laion数据集的结构如下:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
所有示例图像存储在dataset/exemplar中,所有合成图像存储在dataset/synth中,png 格式的 1M laion 图像存储在dataset/laion_subset中。 dataset/json中的 JSON 文件指定训练/验证/测试分割,包括不同的测试用例,并用作真实标签。 JSON 文件中的每个条目都是一个独特的微调模型。条目还记录用于微调的示例图像以及模型生成的合成图像。我们有四个测试用例: test_artchive.json 、 test_bamfg.json 、 test_observed_imagenet.json和test_unobserved_imagenet.json 。
下载测试集、预计算的 LAION 特征和预训练权重后,我们可以通过运行extract_feat.py来预计算测试集中的特征,然后通过运行eval.py评估性能。以下是批量运行评估的 bash 脚本:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh指标存储在results中的.pkl文件中。目前,该脚本按顺序运行每个命令。请随意修改它以并行运行命令。以下命令会将.pkl文件解析为存储为.csv文件的表:
python results_to_csv.py 12/18/2023 更新要下载仅在以对象为中心或以样式为中心的模型上训练的模型,请运行bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
我们感谢 Aaron Hertzmann 阅读早期草稿并提供富有洞察力的反馈。我们感谢 Adobe Research 的同事,包括 Eli Shechtman、Oliver Wang、Nick Kolkin、Taesung Park、John Collomosse 和 Sylvain Paris,以及 Alex Li 和 Yonglong Tian 进行的有益讨论。我们感谢 Nupur Kumari 对自定义扩散训练的指导,感谢 Ruihan Taka 校对草稿,感谢 Alex Li 提供提取稳定扩散特征的指导,感谢 Dan Ruta 在 BAM-FG 数据集方面提供帮助。我们感谢布莱恩·拉塞尔 (Bryan Russell) 进行流行病徒步旅行和集思广益。这项工作是在 SYW 担任 Adobe 实习生时开始的,并得到了 Adobe 捐赠和摩根大通教员研究奖的部分支持。


