clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
在多个用户之间共享高端 GPU 甚至产消者和消费者 GPU 是加速 AI 开发的最具成本效益的方式。不幸的是,到目前为止,唯一适用于 MIG/Slicing 高端 GPU (A100+) 和所需 Kubernetes 的现有解决方案,
?欢迎使用适用于任何 Nvidia 卡的基于容器的分数 GPU! ?
我们提供支持 CUDA 11.x 和 CUDA 12.x 的预打包容器,并具有预构建的硬内存限制!这意味着可以在同一 GPU 上启动多个容器,确保一个用户无法分配整个主机 GPU 内存! (不再有贪婪的进程抢占整个 GPU 内存!最后我们有一个驱动程序级别的硬限制内存选项)。
ClearML 提供了多种选项来通过对 GPU 进行分区来优化 GPU 资源利用率:
借助这些选项,ClearML 能够以优化的硬件利用率和工作负载性能来运行 AI 工作负载。该存储库涵盖基于容器的分数 GPU。有关 ClearML 的部分 GPU 产品的更多信息,请参阅 ClearML 文档。
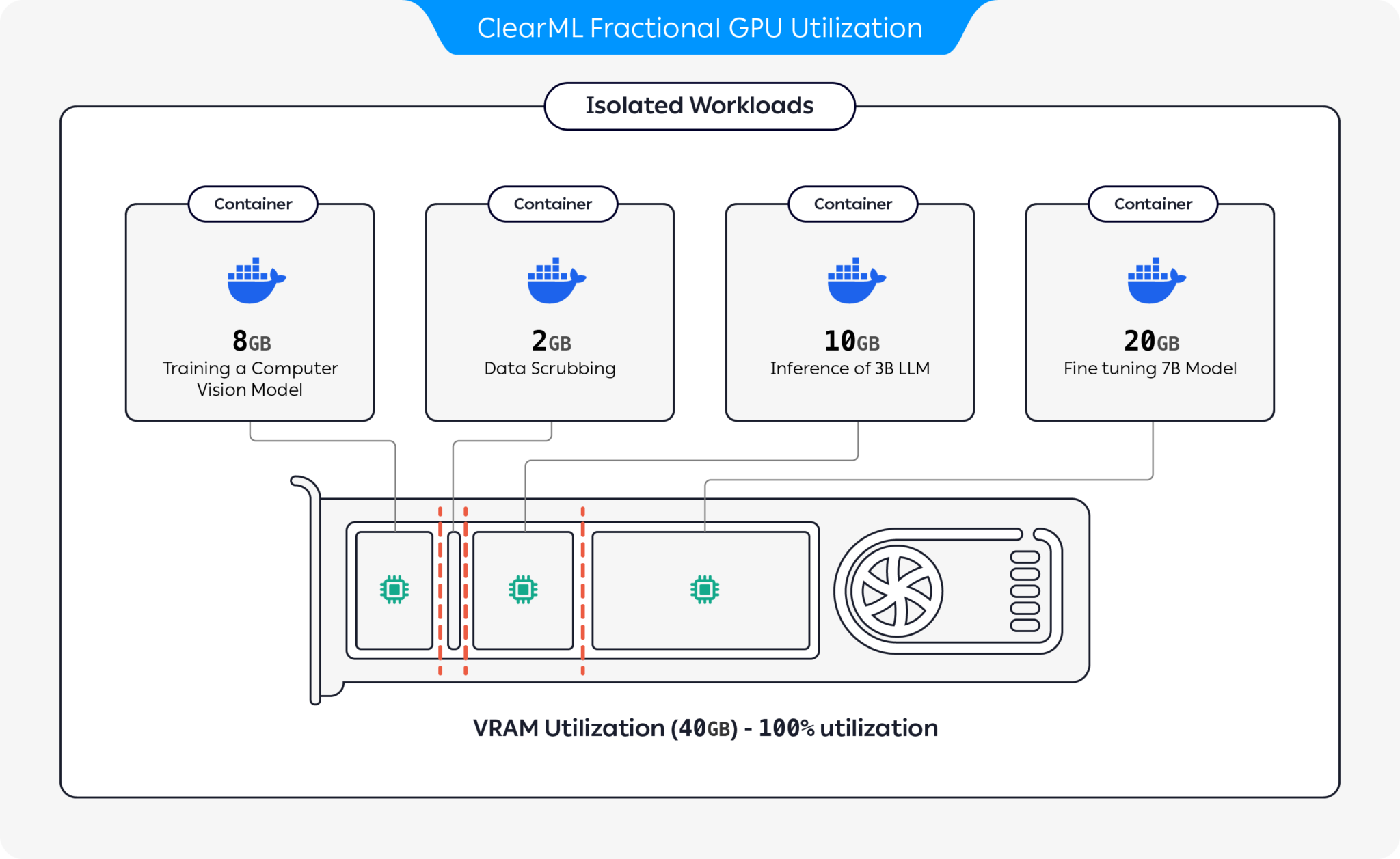
选择适合您的容器并启动它:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bash要验证分数 GPU 内存限制是否正常工作,请在容器内运行:
nvidia-smi以下是 A100 GPU 的输出示例:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| 内存限制 | CUDA版本 | Ubuntu版本 | Docker 镜像 |
|---|---|---|---|
| 12GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
重要的
您必须使用--pid=host执行容器!
笔记
--pid=host需要允许驱动程序在限制内存/利用率使用时区分容器进程和其他主机进程
提示
ClearML-Agent 用户将[--pid=host]添加到配置文件中的agent.extra_docker_arguments部分
构建您自己的容器并继承原始容器。
您可以在这里找到一些示例。
部分 GPU 容器可用于裸机执行以及 Kubernetes POD。是的!通过使用 Fractional GPU 容器之一,您可以限制 Job/Pod 的内存消耗,并轻松共享 GPU,而不必担心它们会互相内存崩溃!
这是一个简单的 Kubernetes POD 模板:
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] 重要的
您必须使用hostPID: true来执行 pod!
笔记
hostPID: true才能允许驱动程序在限制内存/利用率使用时区分 Pod 进程和其他主机进程
容器支持 Nvidia 驱动程序 <= 545.xx 。随着新驱动程序的不断发布,我们将不断更新和支持它们
支持的 GPU :RTX 系列 10、20、30、40、A 系列和数据中心 P100、A100、A10/A40、L40/s、H100
限制:当前不支持 Windows 主机。如果这对您很重要,请在问题部分留下请求
问:在容器内运行nvidia-smi会报告本地进程的 GPU 消耗吗?
答:是的, nvidia-smi直接与低级驱动程序通信,并报告准确的容器 GPU 内存以及容器本地内存限制。
请注意,GPU 利用率将是全局(即主机端)GPU 利用率,而不是特定的本地容器 GPU 利用率。
问:如何确保我的 Python / Pytorch / Tensorflow 实际上受到内存限制?
答:对于 PyTorch,您可以运行:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )努巴示例:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) Q : 用户可以突破这个限制吗?
答:我们确信恶意用户会找到方法。我们从来没有打算防范恶意用户。
如果您的恶意用户可以访问您的机器,那么分数 GPU 不是您的第一大问题吗?
问:如何以编程方式检测内存限制?
答:您可以检查操作系统环境变量GPU_MEM_LIMIT_GB 。
请注意,更改它不会消除或减少限制。
问:使用--pid=host运行容器是否安全?
答:它应该既安全又安全。从安全角度来看,主要的警告是容器进程可以看到主机系统上运行的任何命令行。如果进程命令行包含“秘密”,那么是的,这可能会成为潜在的数据泄漏。请注意,在命令行中传递“秘密”是不明智的,因此我们不认为这是安全风险。也就是说,如果安全性是关键,那么企业版(见下文)消除了使用pid-host运行的需要,从而完全安全。
问:您可以在没有--pid=host情况下运行容器吗?
答:可以!但是您必须使用企业版的clearml-fractional-gpu 容器(否则内存限制将应用于系统范围而不是容器范围)。如果此功能对您很重要,请联系 ClearML 销售和支持。
ClearML 的使用许可仅用于研究或开发目的。 ClearML 可用于教育、个人或内部商业用途。
可在产品或服务中使用的扩展商业许可证作为 ClearML Scale 或 Enterprise 解决方案的一部分提供。
ClearML 提供企业和商业许可证,在部分 GPU 之上添加许多附加功能,其中包括编排、优先级队列、配额管理、计算集群仪表板、数据集管理和实验管理,以及企业级安全性和支持。了解有关 ClearML Orchestration 的更多信息或直接与 ClearML 销售人员联系。
告诉大家吧! #ClearMLFractionalGPU
加入我们的 Slack 频道
当出现问题时告诉我们,并帮助我们在问题页面上进行调试
该产品由 ClearML 团队为您带来❤️


