amazon bedrock rag
1.0.0
检索增强生成(RAG)是优化大型语言模型输出的过程,因此它在生成响应之前引用训练数据源之外的权威知识库。大型语言模型 (LLM) 经过大量数据的训练,并使用数十亿个参数为回答问题、翻译语言和完成句子等任务生成原始输出。 RAG 将法学硕士本已强大的功能扩展到特定领域或组织的内部知识库,而无需重新训练模型。这是一种提高 LLM 输出的经济有效的方法,因此它在各种情况下都保持相关性、准确性和有用性。在此了解有关 RAG 的更多信息。
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先 AI 公司的高性能基础模型 (FM) 以及广泛的一组构建具有安全性、隐私性和负责任的人工智能的生成式人工智能应用程序所需的功能。使用 Amazon Bedrock,您可以轻松地针对您的使用案例试验和评估顶级 FM,使用微调和 RAG 等技术使用您的数据私下自定义它们,并构建使用您的企业系统和数据源执行任务的代理。由于 Amazon Bedrock 是无服务器的,因此您无需管理任何基础设施,并且可以使用您已经熟悉的 AWS 服务将生成式 AI 功能安全地集成和部署到您的应用程序中。
Amazon Bedrock 知识库是一项完全托管的功能,可帮助您实施从摄取到检索和提示增强的整个 RAG 工作流程,而无需构建与数据源的自定义集成和管理数据流。内置会话上下文管理,因此您的应用程序可以轻松支持多轮对话。
作为创建知识库的一部分,您可以配置您选择的数据源和矢量存储。数据源连接器允许您将专有数据连接到知识库。配置数据源连接器后,您可以将数据与知识库同步或保持最新,并使数据可供查询。 Amazon Bedrock 首先将您的文档或内容拆分为可管理的块,以实现高效的数据检索。然后将块转换为嵌入并写入向量索引(数据的向量表示),同时维护到原始文档的映射。向量嵌入允许在数学上比较文本的相似性。
该项目使用两个数据源实施;一个数据源用于存储在 Amazon S3 中的文档,另一个数据源用于存储在网站上发布的内容。在 Amazon OpenSearch Serverless 中创建矢量搜索集合以进行矢量存储。
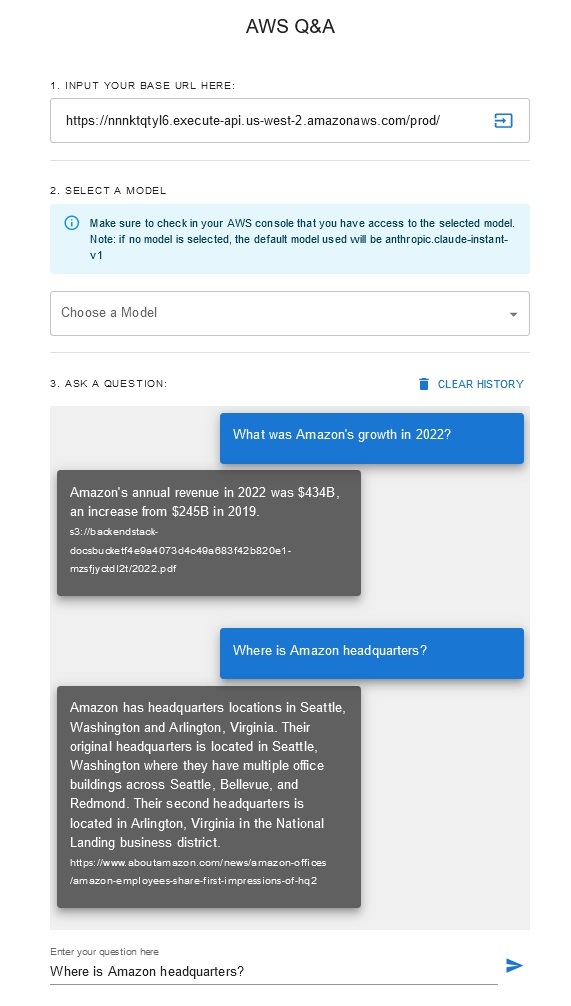
问答聊天机器人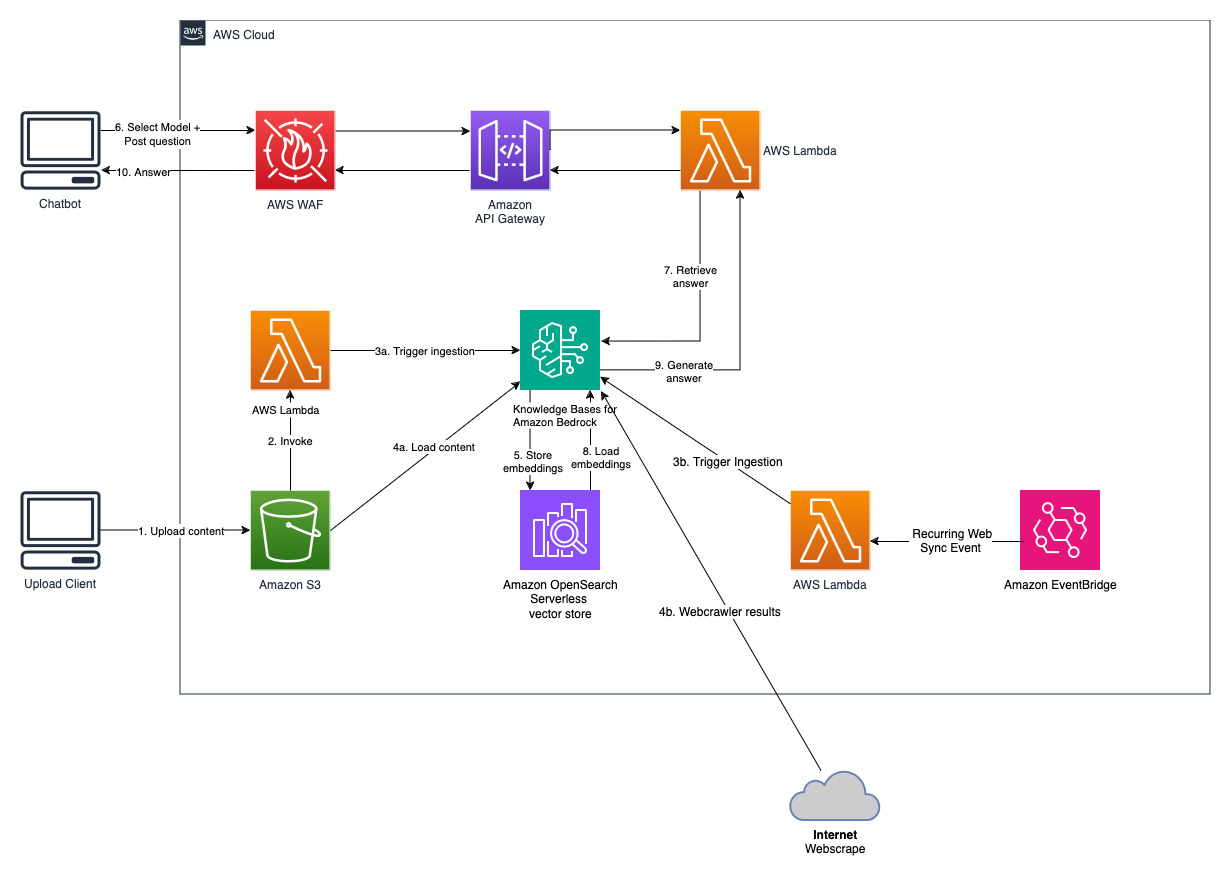
为 Web 数据源添加新网站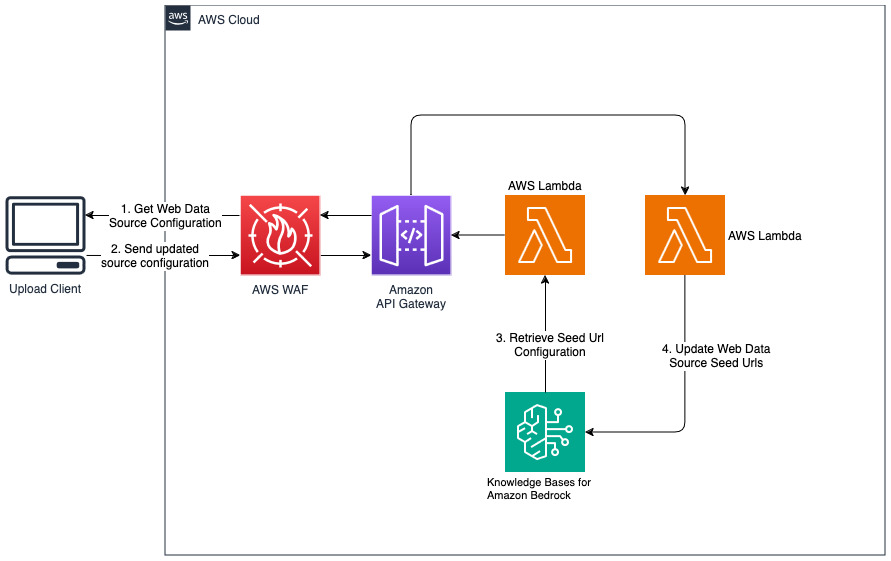
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
提供允许以 CIDR 格式访问 API 网关的客户端 IP 地址,作为“allowedip”上下文变量的一部分。
当部署完成后,
该解决方案允许用户在检索和生成阶段选择他们想要使用的基础模型。默认模型是Anthropic Claude Instant 。对于知识库嵌入模型,此解决方案使用Amazon Titan Embeddings G1 - 文本模型。确保您有权访问这些基础模型。
获取最近公开发布的 Amazon 年度报告,并将其复制到前面提到的 S3 存储桶名称中。为了进行快速测试,您可以使用 AWS S3 控制台复制 Amazon 2022 年年度报告。 S3 存储桶中的内容将自动与知识库同步,因为解决方案部署会监视 S3 存储桶中的新内容并触发摄取工作流程。
部署的解决方案使用 URL https://www.aboutamazon.com/news/amazon-offices初始化名为“WebCrawlerDataSource”的 Web 数据源。您需要将此 Web 爬网程序数据源与 AWS 控制台中的知识库手动同步,以搜索网站内容,因为网站提取计划在将来进行。从基于 Amazon Bedrock 的知识控制台中选择此数据源并启动“同步”操作。有关详细信息,请参阅将您的数据源与 Amazon Bedrock 知识库同步。请注意,只有同步完成后,问答聊天机器人才可以使用网站内容。将网站设置为数据源时,请使用本指南。
使用“cdk destroy”删除在此解决方案部署中创建的云资源堆栈。


