EasyNLU
1.0.0
EasyNLU 是一个用 Java 编写的用于移动应用程序的自然语言理解 (NLU) 库。基于语法,它非常适合狭窄但需要严格控制的领域。
该项目有一个示例 Android 应用程序,可以通过自然语言输入安排提醒:
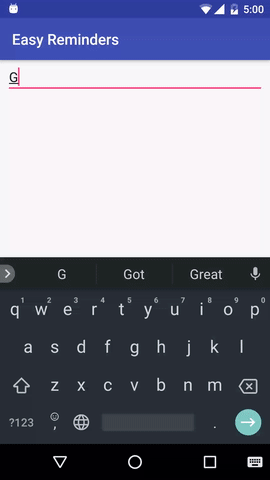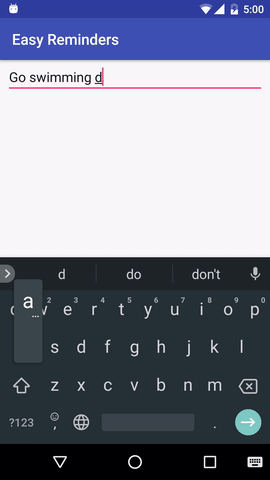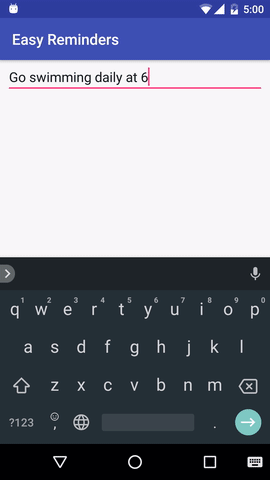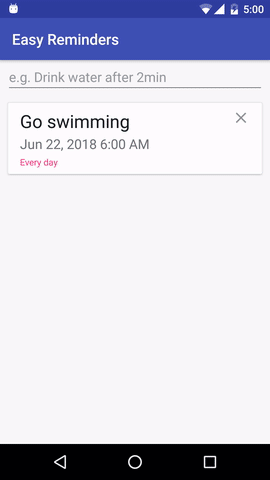
EasyNLU 在 Apache 2.0 下获得许可。
EasyNLU 的核心是一个基于 CCG 的语义解析器。可以在这里找到关于语义解析的很好的介绍。语义解析器可以解析输入,如下所示:
明天下午5点去看牙医
转化为结构化形式:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU 提供结构化形式作为递归 Java 映射。然后可以将该结构化形式解析为“执行”的任务特定对象。例如,在示例项目中,结构化表单被解析为Reminder对象,该对象具有task 、 startTime和repeat等字段,并用于通过 AlarmManager 服务设置警报。
一般来说,以下是设置 NLU 功能的高级步骤:
在编写任何规则之前,我们应该定义任务的范围和结构化表单的参数。作为一个玩具示例,假设我们的任务是打开和关闭蓝牙、Wifi 和 GPS 等手机功能。所以这些字段是:
一个示例结构化形式是:
{feature: "bluetooth", action: "enable" }
此外,使用一些示例输入来理解差异也很有帮助:
继续这个玩具示例,我们可以说在顶层我们有一个设置操作,它必须具有一个功能和一个操作。然后我们使用规则来捕获这些信息:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" );规则至少包含 LHS 和 RHS。按照惯例,我们在单词前面添加“$”来指示类别。类别代表单词或其他类别的集合。在上面的规则中, $Feature代表诸如蓝牙、bt、wifi 等我们使用“词汇”规则捕获的单词:
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
);为了标准化特征名称的变化,我们将$Features构造为子特征:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); $Action的相似之处:
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);注意“?”在第三条规则中;这意味着类别$Switch是可选的。为了确定解析是否成功,解析器会查找称为根类别的特殊类别。按照惯例,它表示为$ROOT 。我们需要添加一条规则来达到此类别:
Rule root = new Rule ( "$ROOT" , "$Setting" );有了这些规则集,我们的解析器应该能够解析上面的示例,将它们转换成所谓的语法树。
如果我们无法提取句子的含义,那么解析就没有用。这种含义由结构化形式(NLP 术语中的逻辑形式)捕获。在 EasyNLU 中,我们在规则定义中传递第三个参数来定义如何提取语义。我们使用带有特殊标记的 JSON 语法来执行此操作:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first告诉解析器选择规则 RHS 第一个类别的值。在这种情况下,它将根据句子“启用”或“禁用”。其他标记包括:
@identity :身份函数@last :选择最后一个 RHS 类别的值@N : 选择第 N 个RHS 类别的值,例如@3将选择第 3 个@merge :合并所有类别的值。仅命名值(例如{action: enable} )将被合并@append :将所有类别的值追加到列表中。必须命名结果列表。只允许命名值添加语义标记后,我们的规则变为:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);如果未提供语义参数,解析器将创建等于 RHS 的默认值。
要运行解析器,请克隆此存储库并将解析器模块导入到您的 Android Studio/IntelliJ 项目中。 EasyNLU 解析器采用一个保存规则的Grammar对象、一个用于将输入句子转换为单词的Tokenizer对象以及一个可选的Annotator对象列表来注释数字、日期、地点等实体。定义规则后运行以下代码:
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));您应该得到以下输出:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
尝试其他变化。如果示例变体的解析失败,您将不会得到任何输出。然后,您可以添加或修改规则并重复语法工程过程。
EasyNLU 现在支持结构化形式的列表。对于上述域,它可以处理类似的输入
禁用 bt gps 定位
将这 3 个额外规则添加到上面的语法中:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
运行一个新查询,例如:
System.out.println(parser.parse("disable location bt gps"));
你应该得到这个输出:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
请注意,仅当查询中存在多个要素时才会触发这些规则
注释器使特定类型的标记变得更容易,否则这些标记将很麻烦或完全不可能通过规则处理。以NumberAnnotator类为例。它将检测所有数字并将其注释为$NUMBER 。然后您可以直接在规则中引用该类别,例如:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
EasyNLU 目前附带了一些注释器:
NumberAnnotator :注释数字DateTimeAnnotator :注释一些日期格式。还提供了您使用DateTimeAnnotator.rules()添加的自己的规则TokenAnnotator :将输入的每个标记注释为$TOKENPhraseAnnotator :将输入的每个连续短语注释为$PHRASE要使用您自己的自定义注释器,请实现Annotator接口并将其传递给解析器。请参阅内置注释器以了解如何实现注释器。
EasyNLU 支持从文本文件加载规则。每条规则必须位于单独的行中。左、右和语义必须用制表符分隔:
$EnableDisable ?$Switch $OnOff @last
注意不要使用自动将制表符转换为空格的 IDE
随着更多规则添加到解析器,您会发现解析器会为某些输入找到多个解析。这是由于人类语言普遍存在歧义。要确定解析器对您的任务的准确性,您需要通过带标签的示例来运行它。
与前面的规则一样,EasyNLU 采用纯文本定义的示例。每一行应该是一个单独的示例,并且应包含由制表符分隔的原始文本和结构化形式:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
重要的是您的输入要涵盖可接受的数量或变化。如果让不同的人来完成这项任务,你会得到更多的多样性。示例的数量取决于领域的复杂性。该项目提供的示例数据集有 100 多个示例。
获得数据后,您可以将其放入数据集。学习部分由trainer模块处理;将其导入到您的项目中。像这样加载数据集:
Dataset dataset = Dataset . fromText ( 'filename.txt' )我们评估解析器以确定两种类型的准确性
为了运行评估,我们使用Model类:
Model model = new Model(parser);
model.evaluate(dataset, 2);
评估函数的第二个参数是详细级别。数字越大,输出越详细。 evaluate()函数通过每个示例运行解析器并显示不正确的解析,最终显示准确性。如果您获得的准确率都在 90 左右,那么就不需要训练,您可能可以通过后处理来处理那些少数错误的解析。如果预言机准确率高但预测准确率低,那么训练系统将会有所帮助。如果预言机准确率本身就很低,那么你需要做更多的语法工程。
为了获得正确的解析,我们对它们进行评分并选择得分最高的一个。 EasyNLU 使用简单的线性模型来计算分数。使用带有铰链损失函数的随机梯度下降 (SGD) 进行训练。输入特征基于结构化表单中的规则计数和字段。然后将训练后的权重保存到文本文件中。
您可以调整一些模型/训练参数以获得更好的准确性。对于提醒模型,使用了以下参数:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );运行训练代码如下:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );这将训练模型 100 个 epoch,训练-测试分割为 0.8。它将显示测试集的准确性并将模型权重保存到提供的文件路径中。要在整个数据集上进行训练,请将部署参数设置为 true。您可以运行交互模式从控制台获取输入:
experiement.interactive();
注意:即使有大量示例,也不能保证训练能够产生高精度。对于某些场景,所提供的功能可能不够具有区分性。如果您遇到这种情况,请记录问题,我们可以找到其他功能。
模型权重是纯文本文件。对于 Android 项目,您可以将其放置在assets文件夹中并使用 AssetManager 加载它。请参阅 ReminderNlu.java 了解更多详细信息。您甚至可以将权重和规则存储在云中并通过无线方式更新您的模型(Firebase 有人吗?)。
一旦解析器很好地将自然语言输入转换为结构化形式,您可能会希望该数据位于任务特定对象中。对于某些领域(例如上面的玩具示例),它可能非常简单。对于其他人,您可能必须解析对日期、地点、联系人等内容的引用。在提醒示例中,日期通常是相对的(例如“明天”、“2 小时后”等),需要将其转换为绝对值。请参考 ArgumentResolver.java 查看解析是如何完成的。
提示:定义规则时尽量减少解析逻辑,并在后处理中完成大部分工作。这将使规则更加简单。


