dstoolkit km solution accelerator
V1.6

知识挖掘解决方案加速器
此存储库包含用于部署基于 Azure 认知搜索的端到端知识挖掘解决方案的所有代码。
它构建在标准 Azure 服务之上,例如功能、Web 应用服务、认知服务和认知搜索。它提供了一个部署管道,允许为您的项目快速轻松地设置 CI/CD 管道。
有关详细文档,请参阅包含解决方案 wiki 的存储库的文档部分。
为了成功设置您的解决方案,您需要有权访问和/或配置以下内容:
在 Azure 订阅或目标资源组上假定所有者或贡献者角色。
请参阅自述文件来部署此解决方案加速器。
所有指南中提供的说明均假定你具备 Azure 门户、Azure Functions、Azure 认知搜索、函数、存储和 Azure 认知服务的基本工作知识。
如需其他培训和支持,请参阅:
知识挖掘(KM)是人工智能(AI)中的一门新兴学科,它利用智能服务的组合来快速从大量信息中学习。它使组织能够深入理解并轻松探索信息,发现隐藏的见解,并大规模发现关系和模式。
Azure 中的知识挖掘
该知识管理解决方案加速器旨在为您提供可行的端到端知识挖掘解决方案,其中包括:
借助这个基于云的加速器,您将获得带有部署、扩展、操作和监控工具的端到端解决方案。
在这方面,该解决方案提供了
该知识挖掘解决方案加速器的灵感来自另一个加速器知识挖掘解决方案加速器。
根据我们的现场经验,我们构建了功能/技能来解决常见的非结构化数据挑战,重点关注可用性和数据探索体验。
以下是主要亮点的非详尽列表:
嵌入图像索引
图像标准化:
元数据
HTML 转换
表格提取:表格信息在非结构化数据语料库中很常见。该解决方案将提取表、索引表并将其投影到专用知识存储(可选)。
Translation ": 该解决方案有两个翻译功能
文本分析:从任何文档和 OCR 图像文本中提取实体(命名、链接)。
导出到 Excel :探索非结构化数据时常见的问题。
可配置的 UI :构建 UI 非常耗时,我们希望提供出色的 UI 可配置性,以便您可以及时实现新的 KM 解决方案。
该解决方案加速器精神属于内容研究知识管理场景。
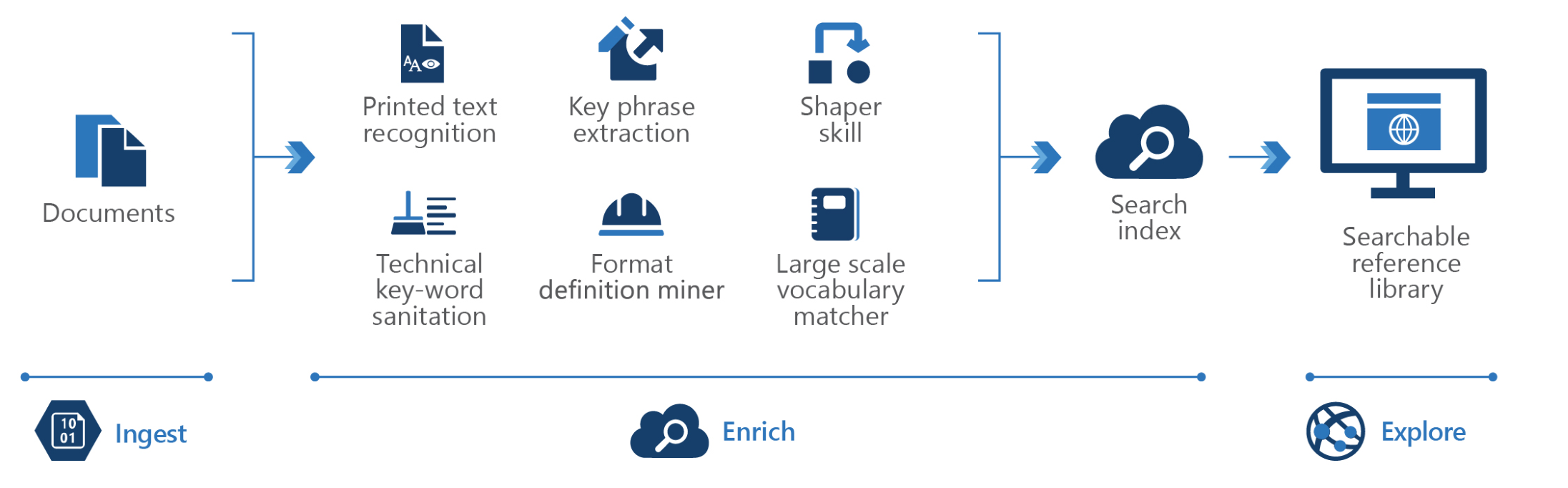
尽管如此,由于其架构是开放的,您可以将其用作更专业的知识管理场景的基础。
该解决方案加速器不针对任何域,尽管其可扩展性将为您提供使其特定于域的工具。
一些鼓舞人心的用例
您可能会认为产品化是您组织的加速器。
该解决方案加速器针对有需要的人
该解决方案加速器的目的还在于简化数据科学模块与知识挖掘解决方案的集成。
数据科学工具包团队为您的数据科学工作负载构建了加速器。
| 解决方案 | 描述 |
|---|---|
| 多才多艺 | Verseagility 是一个基于 Python 的工具包,可增强您的自定义自然语言处理 (NLP) 任务,使您能够引入自己的数据、使用您喜欢的框架并将模型投入生产。它是 Microsoft 数据科学工具包的核心组件。 |
| MLOps 基础 | 此存储库包含基于 Azure 技术(Azure ML 和 Azure DevOps)的机器学习项目的基本存储库结构。文件夹名称和文件是根据个人经验选择的。您可以找到该结构背后的原则和想法,我们建议您在定制自己的项目和 MLOps 流程时遵循这些原则和想法。此外,我们希望用户熟悉 Azure 机器学习概念以及如何使用该技术。 |
| DataBricks 的 MLOps | 该存储库包含 Databricks 开发框架,用于交付任何数据工程项目以及基于 Azure 技术的机器学习项目。 |
| 分类解决方案加速器 | 此存储库包含基本存储库结构,用于为基于 Azure 技术(Azure ML 和 Azure DevOps)的机器学习 (ML) 项目提供分类解决方案。 |
| 物体检测解决方案加速器 | 此存储库包含用于在 Azure 机器学习 (AML) 中训练 TensorFlow 对象检测模型的所有代码,以及用于在 Azure 计算、实验监控和作为 Web 服务的端点部署上进行训练的设置。它基于 MLOps 加速器构建,提供端到端培训和部署管道,允许快速轻松地为您的项目设置 CI/CD 管道。 |
您可以参考解决方案加速器文档如下:
| 话题 | 描述 | 文档链接 |
|---|---|---|
| 先决条件 | 部署和操作该解决方案需要什么 | 自述文件 |
| 建筑学 | 解决方案的架构如何 | 自述文件 |
| 部署 | 如何部署此解决方案加速器 | 自述文件 |
| 配置 | 您需要了解的有关解决方案加速器配置的所有信息 | 自述文件 |
| 数据科学 | 与数据科学集成 | 自述文件 |
| 部署 | Ho 开始部署解决方案 | 自述文件 |
| 监控 | 如何监控解决方案 | 自述文件 |
| 搜索 | 如何配置和管理搜索 | 自述文件 |
| 搜索和探索(UI) | 用于搜索和探索的用户界面 | 自述文件 |
该加速器的存储库结构如下
克隆或下载此存储库,然后导航到部署文件夹,按照部署指南中概述的步骤进行操作。
完成所有步骤后,你将拥有一个有效的端到端知识挖掘解决方案,该解决方案将数据源摄取与数据丰富技能以及由 Azure 认知搜索提供支持的 Web 应用程序相结合。
该解决方案的灵感来自于
该解决方案加速器的核心贡献者是
数据科学工具包赞助团队
关于知识挖掘和非结构化数据的精彩对话
该项目欢迎贡献和建议。大多数贡献都要求您同意贡献者许可协议 (CLA),声明您有权并且实际上授予我们使用您的贡献的权利。有关详细信息,请访问 https://cla.opensource.microsoft.com。
当您提交拉取请求时,CLA 机器人将自动确定您是否需要提供 CLA 并适当地装饰 PR(例如,状态检查、评论)。只需按照机器人提供的说明进行操作即可。您只需使用我们的 CLA 在所有存储库中执行一次此操作。
该项目采用了微软开源行为准则。有关详细信息,请参阅行为准则常见问题解答或联系 [email protected] 提出任何其他问题或意见。
该项目可能包含项目、产品或服务的商标或徽标。 Microsoft 商标或徽标的授权使用须遵守且必须遵循 Microsoft 的商标和品牌指南。在此项目的修改版本中使用 Microsoft 商标或徽标不得引起混淆或暗示 Microsoft 赞助。对第三方商标或徽标的任何使用均须遵守这些第三方的政策。


