PubData
1.0.0

PubData是全球所有生物信息学数据库的搜索引擎和文件检索系统。 PubData以用户友好的方式搜索生物医学 FTP 数据,类似于 PubMed 搜索生物医学文献的方式。 PubData以 Web 应用程序和独立图形用户界面 (GUI) 软件程序的形式托管,而 PubMed 以在线 Web 服务器的形式托管。 PubData基于新颖的网络编程和自然语言处理算法构建,可以修补任何用户指定的生物信息学数据库的 FTP 服务器、查询其内容并检索文件以供下载。
PubData是用 Python 编程语言(特别是 Django 和 PyQt4)编写的。 PubData可以通过本地计算机网络从任何主要生物信息学数据库的深层嵌套目录树中远程搜索、访问、查看和检索文件。通过将所有主要生物信息学数据库集中在一个软件程序下, PubData使用户可以避免使用互联网浏览器逐一访问数据库所固有的不必要的麻烦和非标准化的复杂性。更重要的是,它允许用户同时查询多个数据库以查找用户指定的关键字(例如, human 、 cancer 、 transcriptome )。因此, PubData允许研究人员直接从一个集中位置搜索、访问、查看和下载任何主要生物信息学数据库的 FTP 服务器上的文件。通过仅使用 GUI 或 Web 应用程序, PubData允许用户直接从舒适的本地计算机同时浏览多个生物信息学 FTP 服务器。
请在使用受PubData启发的任何方法的任何来源中引用:“Khomtchouk 等人:‘PubData:全球生物信息学数据库搜索引擎’,2016:http://dx.doi.org/10.1101/069575”。
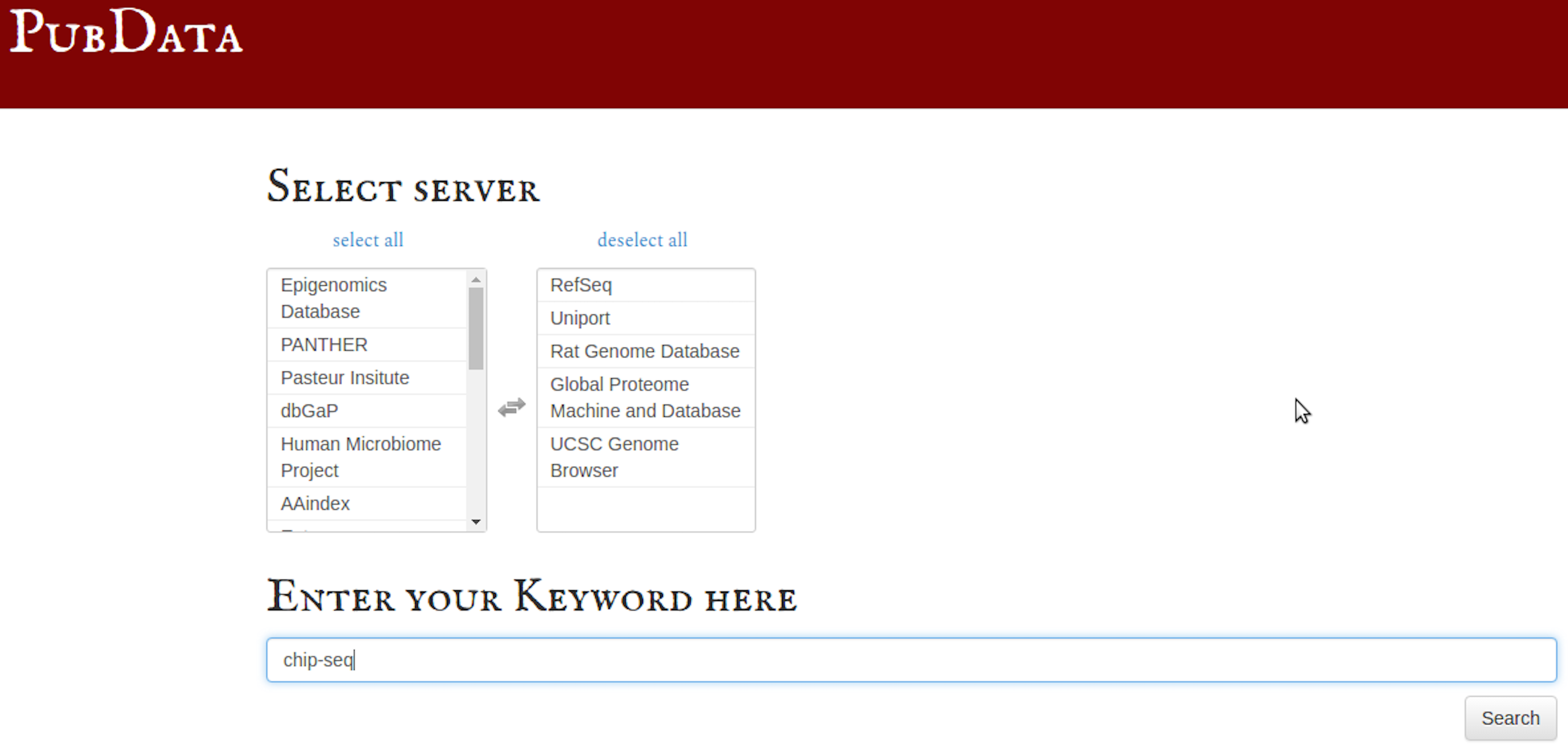
PubData目录。当您打开PubData时,首先选择要登录的生物信息学数据库:
登录 PANTHER(通过进化关系进行蛋白质分析)分类系统数据库:
如果列表中没有看到您喜欢的数据库,您可以自己手动插入(对于最近发布的数据库很方便):
假设您想同时“Google 搜索”多个数据库:
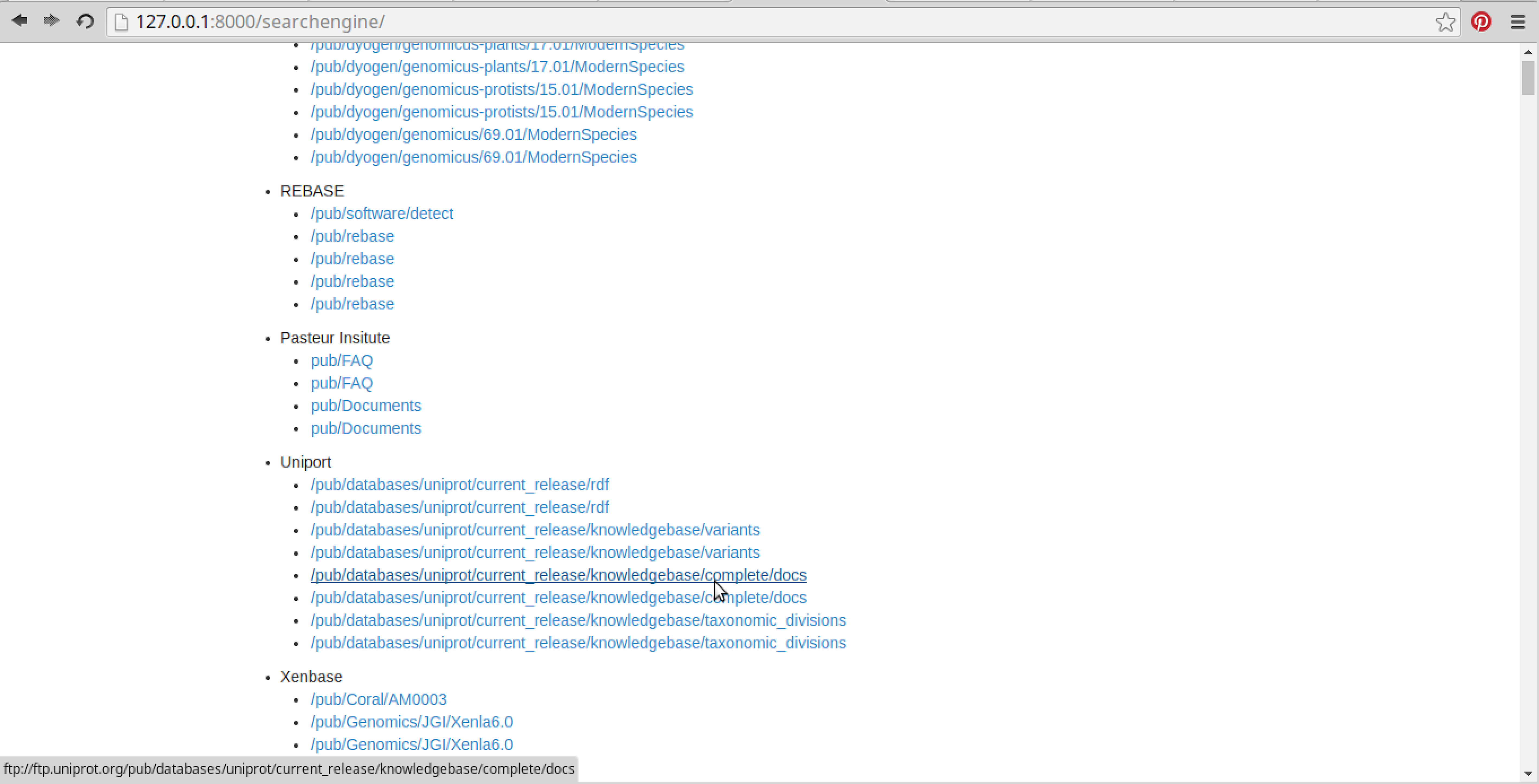
在这些选定的数据库中对 ChIP-seq 文件进行关键字搜索(也可以使用多个关键字):
显示所有选定数据库中与 ChIP-seq 文件相关的所有相关搜索结果:
在这些选定的数据库中对 RNA-seq 文件进行关键字搜索(也可以使用多个关键字):
显示与 RNA-seq 文件相关的所有相关搜索结果(来自所选数据库):


