Sound Content Music Recommendation System
1.0.0

如果你像我一样,你就会热爱音乐。我热爱音乐,也喜欢寻找新音乐。 Spotify 是互联网上顶级的音乐流媒体服务之一,它已经包含了一些令人惊叹的工具,可以帮助您根据所听的内容发现新音乐。它通过不同算法的组合来实现这一点,包括协作过滤,其中跟踪用户之间的相似使用情况并用于生成推荐或基于内容的推荐,这些推荐基于链接到歌曲的信息之间的相似信息推荐新歌曲。就像一首歌一样?在 Spotify 上,您可以收听该歌曲的“广播”,它会以某种方式或多种方式的组合收集与该歌曲相似的一组歌曲。如果您喜欢一首歌,但除了其中的声音之外不关心任何信息怎么办?有时,这就是我想听到的一切。
我创建这个项目是为了制作一个仅基于音乐声音中的信息的音乐推荐系统。它将帮助用户通过听起来相似的歌曲找到新的音乐。为此,它还将探索所有音乐之间的相似性,并尝试以数学方式捕捉歌曲的音色、节奏和风格。
声音始终就在我们身边。在我们的一生中,我们逐渐能够辨别他人的不同声音。音乐也不例外——音乐有很多种类型,而且音乐通常是许多不同种类的声音和节奏的组合,我们也可以将它们与其他声音和节奏区分开来。但我们可以自己量化这些信息吗?有时,音乐被分为流派,这意味着流派是一群具有相似风格、形式、节奏、音色、乐器或文化品质的音乐家。但并非每个音乐艺术家都以同一流派创作声音,也并非每种流派都包含相同类型的音乐。那么什么是声音,我们如何辨别不同类型的声音?
声音是声波的振动,当声波振动我们的耳膜时,我们可以通过耳朵感知到声音。声波是一种信号,该信号振动的速度称为频率。如果声音频率较高,我们会感觉到该声音的音调较高。在音乐中,低音或低音鼓等乐器会产生较低频率振动的声音,而高音则具有较高频率。听起来像是铙钹或高帽的撞击声是不同频率的许多波的组合,并由“嘈杂”、几乎随机的波表示。
声音看起来像什么?我们可视化声音的一种方法是绘制随时间变化的信号:
当我们缩短每个子图上的时间窗口时,我们可以更近距离地看到音频信号。请注意,在信号的最放大图像中,波是不同频率的集合。可能存在一种低频信号与较小的高频信号组合。
因此,我们可以随着时间的推移可视化信号,但我们已经可以看出,仅通过查看此可视化效果很难理解该声波。 0.01 秒的窗口中存在哪些频率?为了回答这个问题,我们将使用傅立叶变换来计算频谱图。
傅里叶变换是一种计算音频信号部分中存在的频率幅度的方法。正如您在上图中看到的,波可能很复杂,信号的每种变化代表不同的频率(振动速度)。傅里叶变换本质上会提取每个时间段的频率,并生成频率幅度与时间的二维数组。傅里叶变换的产物是频谱图。根据频谱图,我们将产生的频率转换为梅尔标度以创建梅尔频谱图。梅尔频谱图更好地代表了我们听到频率时所感知到的频率之间的距离。
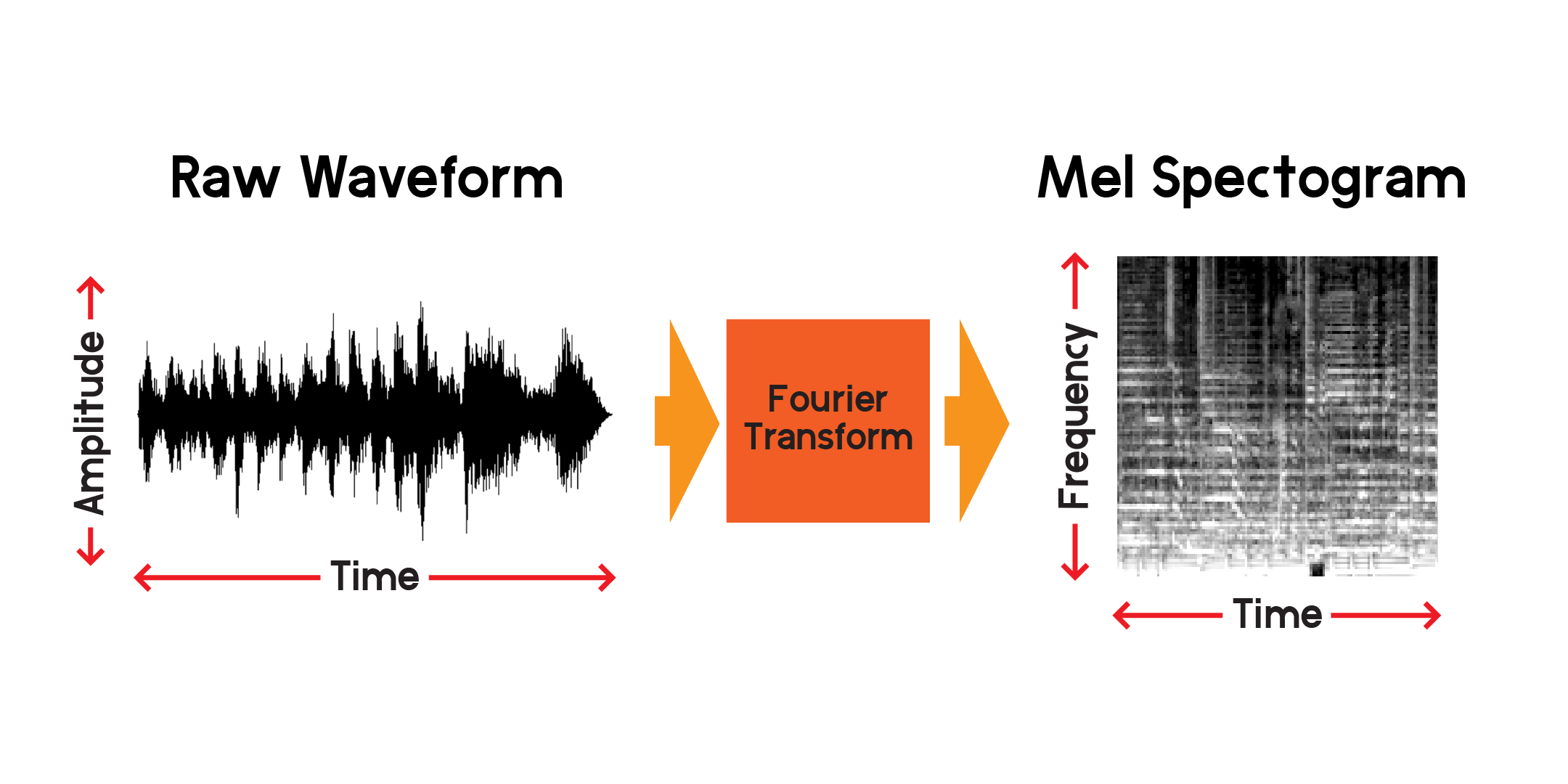
让我们根据上面绘制的同一音频样本绘制梅尔频谱图的示例:
使用 Spotify 的公共 API,我在以前的笔记本中抓取了歌曲信息。从那里我可以下载每首歌曲的 30 秒 mp3 预览,并将其转换为梅尔频谱图,以便在训练图像的神经网络中使用。首先,让我们看一下数据框,我们将使用它来收集 mp3 预览。
在另一台笔记本中,我从 Spotify API 获取了预览链接,下载了 mp3,并将声音文件转换为包含梅尔频谱图、梅尔频率倒谱系数和色谱图的合成图像。我创建这个合成图像的目的是为了可以使用这些其他转换,但对于这个项目,我将仅在梅尔谱图上训练神经网络。
为了仅根据声音内容推荐类似的歌曲,我需要创建以某种方式解释歌曲内容的功能。此外,为了快速完成此操作,我需要将每首歌曲的信息压缩为比梅尔频谱图输入更小的数字集。
每个歌曲预览文件都有超过 600,000 个样本。在每个梅尔谱图中,有 512 x 128 像素,总计 65,536 像素。即使 128x128 的图像也包含 16,384 个像素。该自动编码器模型会将歌曲的内容压缩为仅 256 个数字。一旦自动编码器经过充分训练,网络将能够以最小的损失从长度为 256 的向量重建歌曲。
自动编码器是一种神经网络,由编码器和解码器组成。首先,编码器将输入的信息压缩为更少量的数据,而解码器将重建数据以尽可能接近原始输出。
自动编码器也是一种特殊类型的神经网络,因为它不受监督,尽管它并非完全无监督。它是自我监督的,因为它使用其输入来训练模型的输出。
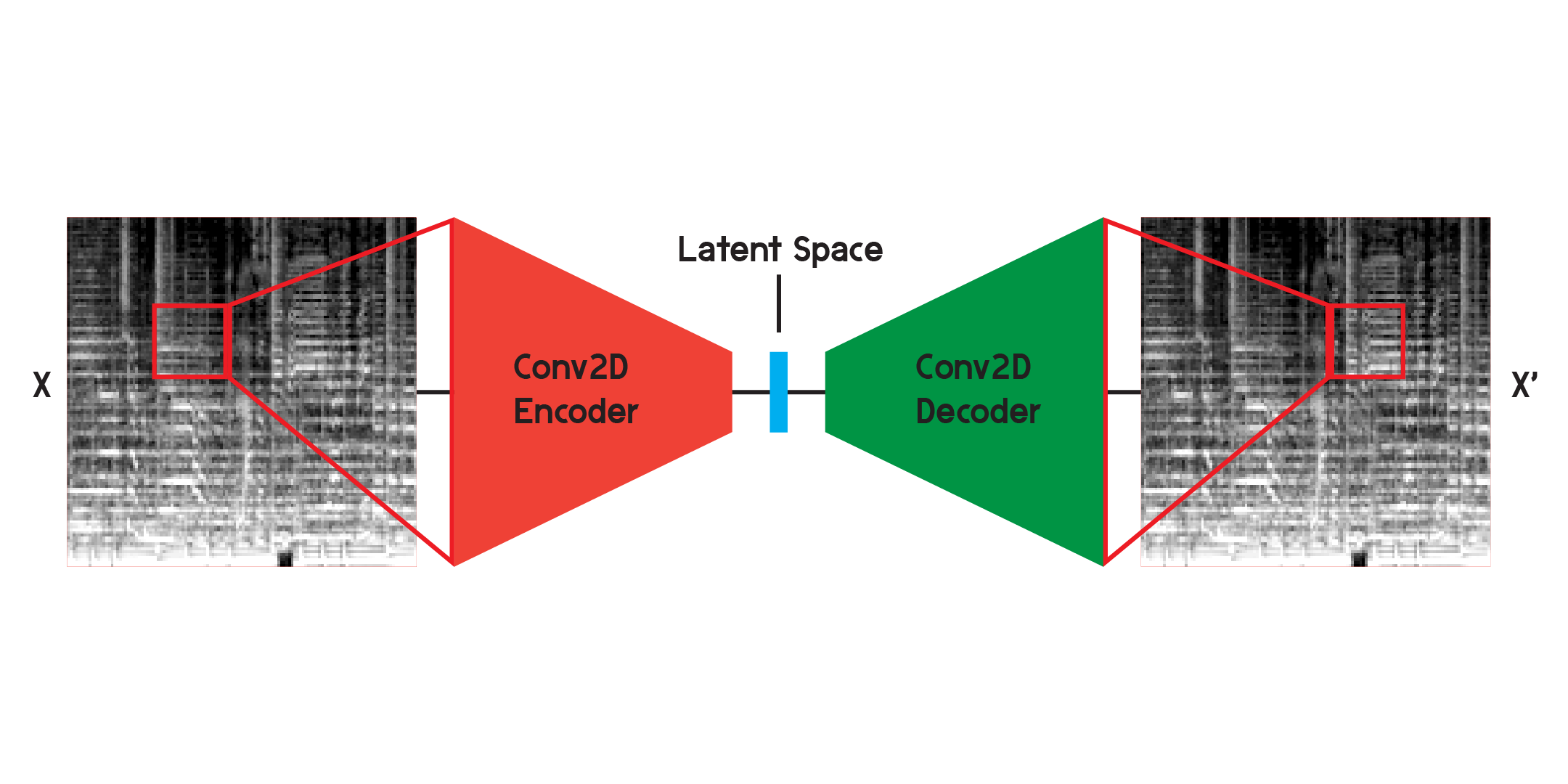
在处理图像时,编码器是一系列二维卷积层,它创建加权滤波器来提取图像中的模式,同时还将图像压缩为越来越小的形状。解码器是编码器中过程的镜像,将少量数据重塑和扩展为更大的数据。该模型最小化原始和重建之间的均方误差。一旦经过充分训练,模型的原始输出和输出之间的均方误差将非常小。尽管均方误差很小,但重建图像与原始图像之间仍然存在视觉差异,尤其是在最小的细节上。自动编码器是一种降噪器。我们希望提取尽可能多的细节,但最终,自动编码器也会混合一些细节。
我最初使用上面所示的结构来训练网络,但发现重建中缺少许多细节。卷积层搜索只是整个图像的一小部分的模式。但在训练和观察过滤器之后,很难直观地了解提取的模式。
像这样的自动编码器可以用于解决几个不同的问题,并且通过卷积层,图像识别和生成有许多应用。但由于梅尔声谱图不仅是图像,而且是声音内容随时间变化的频率图,我相信可以实现稍微不同的结构以最小化重建中的损失,同时也最小化二维卷积产生的不确定性层。
在模型最终结果所使用的模型中,我将编码器拆分为两个独立的编码器。每个编码器使用一维卷积层来压缩图像的空间。一个编码器在 X 上进行训练,而另一个编码器在 X 转置或输入的 90 度旋转版本上进行训练。这样,一个编码器从图像的时间轴学习信息,另一个编码器从频率轴学习。
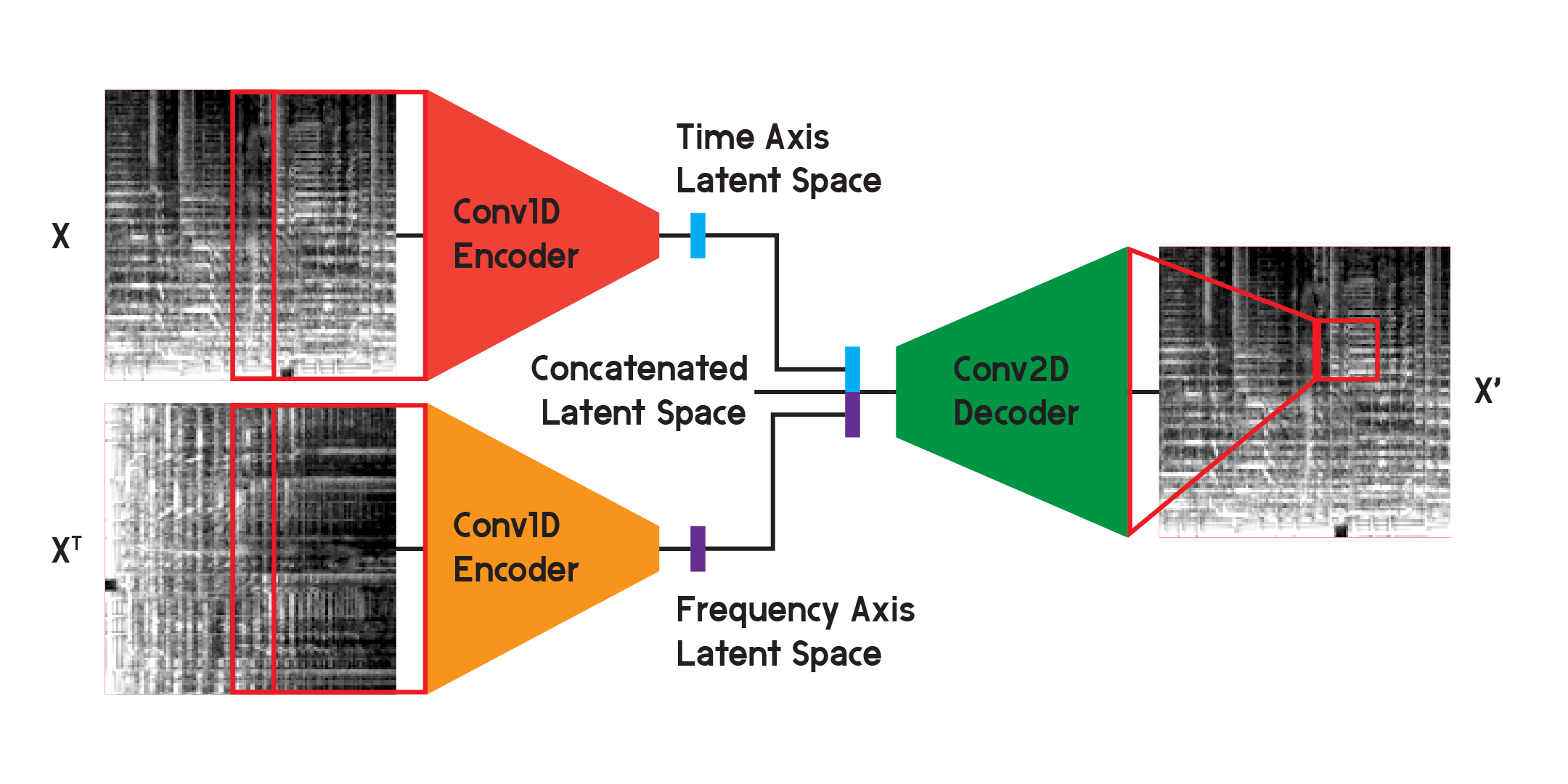
输入经过每个编码器后,得到的编码向量被连接成一个向量,并输入到二维卷积解码器中,如前所述。像以前一样,对输出进行训练以最小化输入之间的损失。
最终,最终模型的损失远低于基本结构,20个epoch后均方误差达到0.0037(训练)和0.0037(验证),训练集中有125,440张图像,训练集中有2560张图像。验证集。
我们将在这里构建模型仅用于演示目的,因为我在另一个笔记本中训练了该模型,并且在构建后将从训练的模型中加载权重。
使用自定义类通过网络运行推理并保存结果,我们可以为我们拥有的每个梅尔谱图构建潜在空间。我们可以通过仅通过编码器运行数据并接收我们初始化模型时大小的向量(在本例中为 256 维)来实现此目的。
为了通过模型探索数据潜在空间创建的抽象景观,我们可以使用降维。 UMAP 与 T-SNE 一样,可以将多维空间缩减为二维,以便在绘图中可视化。
自定义 LatentSpace 类将使用每个向量的余弦相似度来搜索推荐。
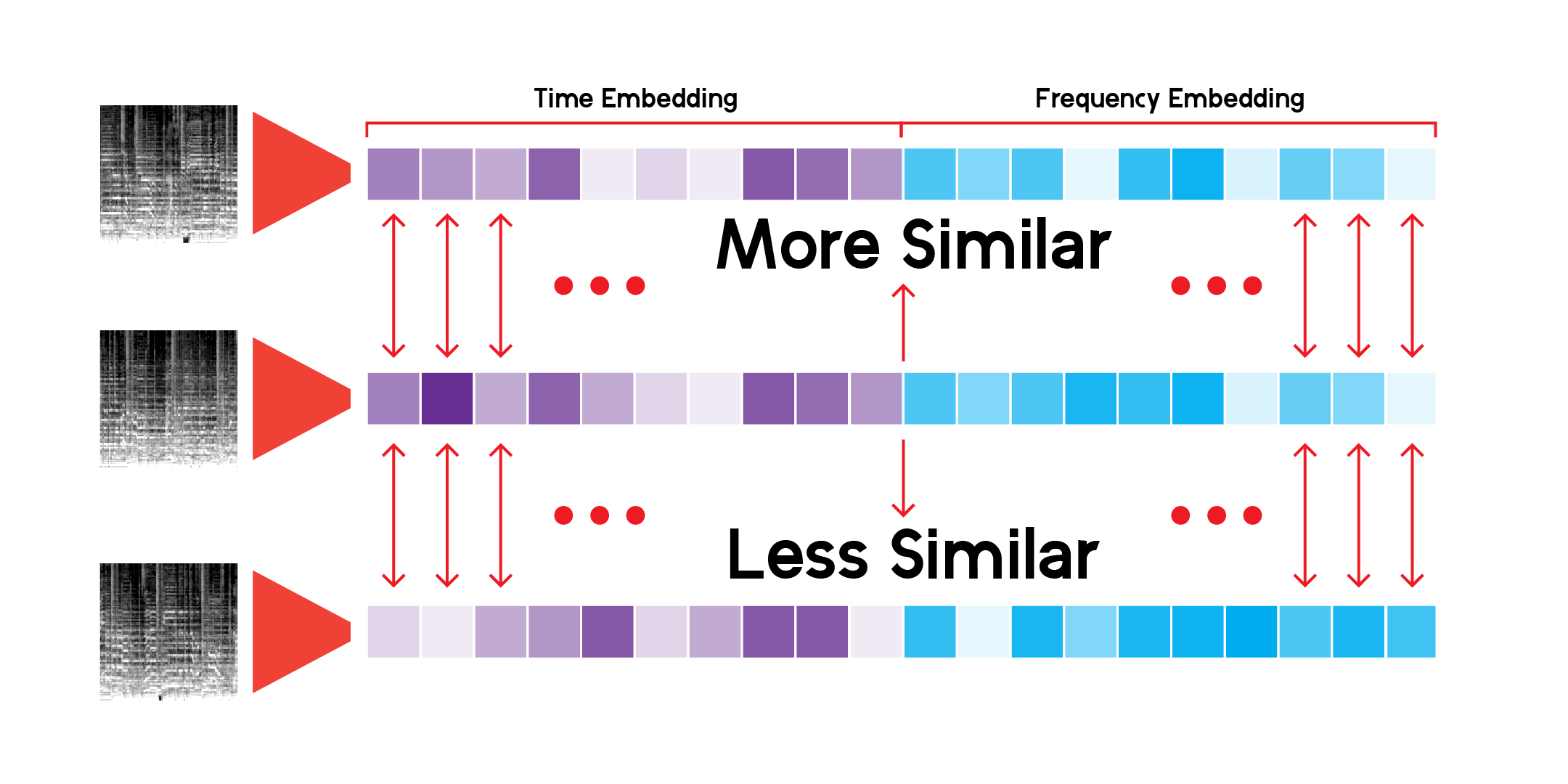
我一直在无休止地搜索这个推荐系统,我很满意该模型可以在不同但相似的音乐声音之间找出非常有趣的联系。以下是我的一些结论:
我的意思是,该模型是根据每首歌曲的声音内容进行推荐,但它并不是在听歌曲。它创建梅尔谱图并进行数学比较。
有时系统会根据歌曲的年龄推荐歌曲。如果一首歌曲是很久以前录制的,那么录制材料或设备的那些特定频率将被模型拾取,并显示结果。
此外,该模型非常擅长拾取声音或特定乐器。因此,如果一首歌有很多说唱或说唱,它可能只会推荐口语歌曲。此外,如果歌曲中有很多失真,它可能会推荐雨声或鸟鸣声。
正如我最初的 EDA 中所指出的,某些曲目预览在 Spotify API 中不可用。因此,他们对模型的贡献也缺失,并且当他们可能非常适合时也不会被推荐。例如,没有詹姆斯·布朗、披头士乐队或普林斯的歌曲。需要更多数据。
该系统使用超过 278,000 个预览来提供推荐,但这仍然不够。查看所有轨道的 UMAP 投影,数据有很多连续性,但也存在一些漏洞。理想情况下,系统可以使用更多的数据来利用。
像 Spotify 这样的推荐系统/服务之所以如此擅长提出推荐,是因为它结合了许多不同类型的推荐系统和像这样的功能来提供推荐。从跟踪您经常收听的内容,到使用协作过滤根据相似的用户使用情况查找推荐,Spotify 可以对某人会喜欢和收听的内容做出更加平衡的预测。我确实发现这个模型对于进行预测很有趣,但是可以通过添加更多功能(例如类似的类型、发行年份和类似的用户数据)来增强它,以做出更好的预测。
总而言之,除了做出预测和建议之外,我觉得这个模型的真正重要性在于解释音乐语言和声音的连续性和频谱。流派是人们给艺术家或声音贴上的标签,但流派混合在一起,每种声音都存在于这个连续的空间中,至少在数学上是这样。
而且,音乐没有障碍。大多数时候,当在推荐系统中查询歌曲时,结果将来自各个不同的时代和不同的地方。由于歌曲的任何元数据都不是自动编码器的输入,因此结果基于其声音相似性,仅此而已。


