T5Elasticsearch
1.0.0
下面是一个求职示例:
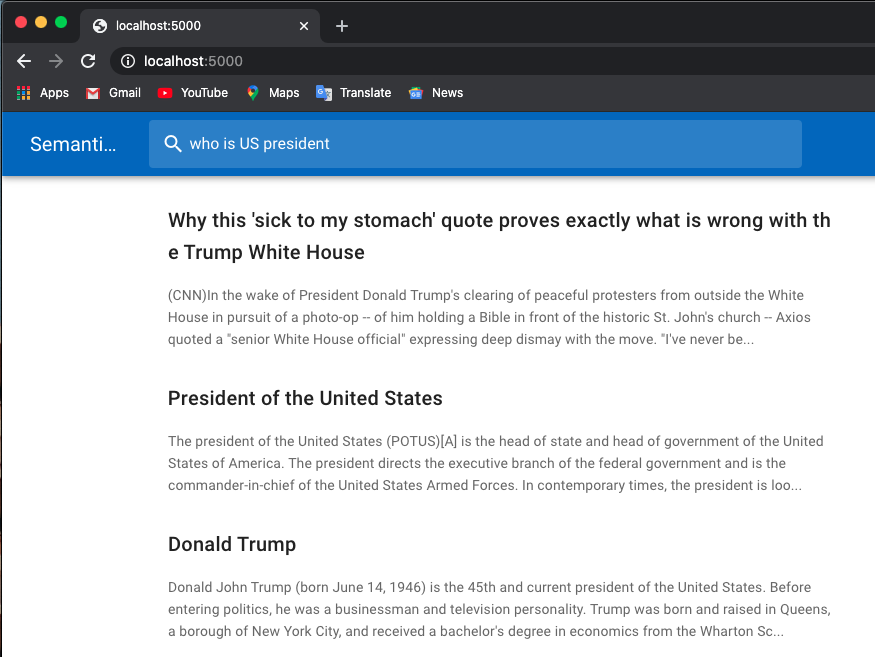
我使用来自 Huggingface Transformer 的预训练模型。
手动将预训练的分词器和 t5/bert 模型下载到本地目录中。您可以在此处检查模型。
我使用“t5-small”模型,检查此处并单击List all files in model以下载文件。 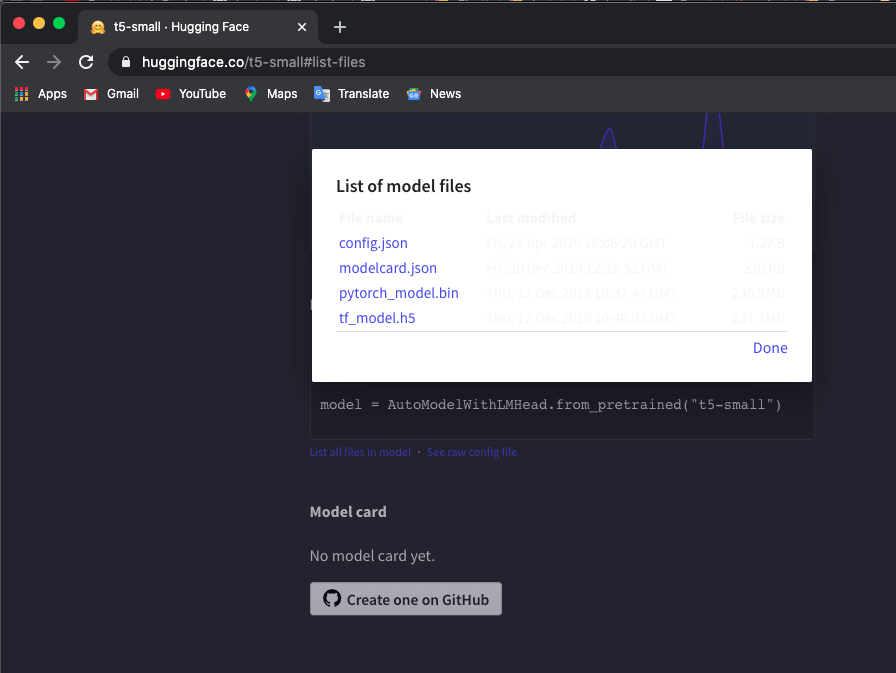
请注意手动下载的文件目录结构。
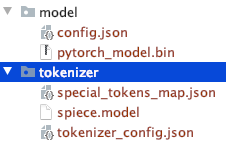
您可以使用其他 T5 或 Bert 模型。
如果您下载其他模型,请检查hugaface Transformers预训练模型列表以检查模型名称。
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build我还使用docker system prune删除所有未使用的容器、网络和图像以获得更多内存。如果您遇到Container exits with non-zero exit code 137错误,请增加您的 docker 内存(我使用8GB )。
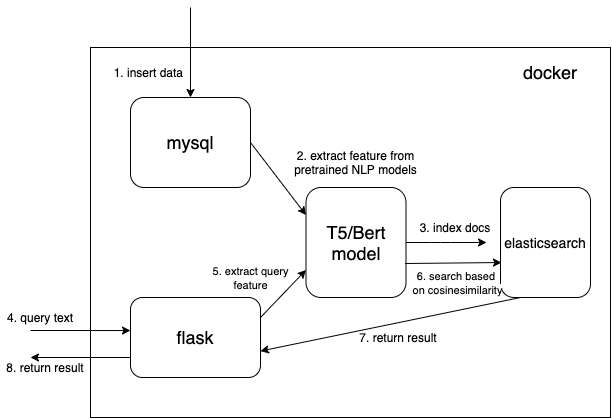
我们使用密集向量数据类型来保存从预训练 NLP 模型中提取的特征(这里是 t5 或 bert,但您可以自己添加您感兴趣的预训练模型)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
}尺寸尺寸dims:512适用于 T5 型号。如果您使用 Bert 模型,请将dims更改为 768。
从mysql读取doc并将文档转换为正确的json格式以批量导入elasticsearch。
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'访问http://127.0.0.1:5000。
使用预训练模型提取特征的关键代码是./index_files/indexing_files.py和./web/app.py文件中的get_emb函数。
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()您可以更改代码并使用您最喜欢的预训练模型。例如,您可以使用 GPT2 模型。
您还可以使用自己的分数函数而不是.webapp.py中的cosineSimilarity来自定义您的elasticsearch。
这个rep是基于Hironsan/bertsearch修改的,它使用bert-serving包来提取bert特征。它仅限于 TF1.x


