nlp lt
1.0.0
这项研究的主要目的是研究和学习立陶宛语的自然语言处理(NLP)原理。分析经典的 NLP 方法并了解它们是如何工作的很有趣,因此在这项工作中我实现了文本分类、主题提取、搜索查询和聚类思想。实施细节和更多信息存储在paper/paper.pdf
没有文本数据就无法进行数据分析,因为我的工作是从最流行的新闻网站 www.delfi.lt 获取原始数据开始的。我决定抓取 5 个类别的文章(犯罪分子[227 篇文章]、音乐[120 篇文章]、电影[167 篇文章]、体育[136 篇文章]、科学[204 篇文章])。
分类性能是使用混淆矩阵来衡量的,其中行是真实类别,列是预测类别。此外,这种方法的召回率和准确率都达到 90% 以上。 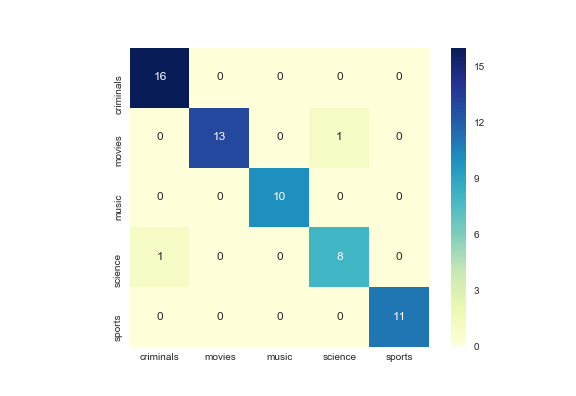
该图显示了 6 个组件,每个组件有 10 个令牌。从这些结果中,我们可以检测最重要的单词并直观地猜测每个主成分的主题。例如,4 个主成分存储有关体育和音乐的信息,而 6 个主成分存储有关犯罪分子的信息。
主要结果如下: 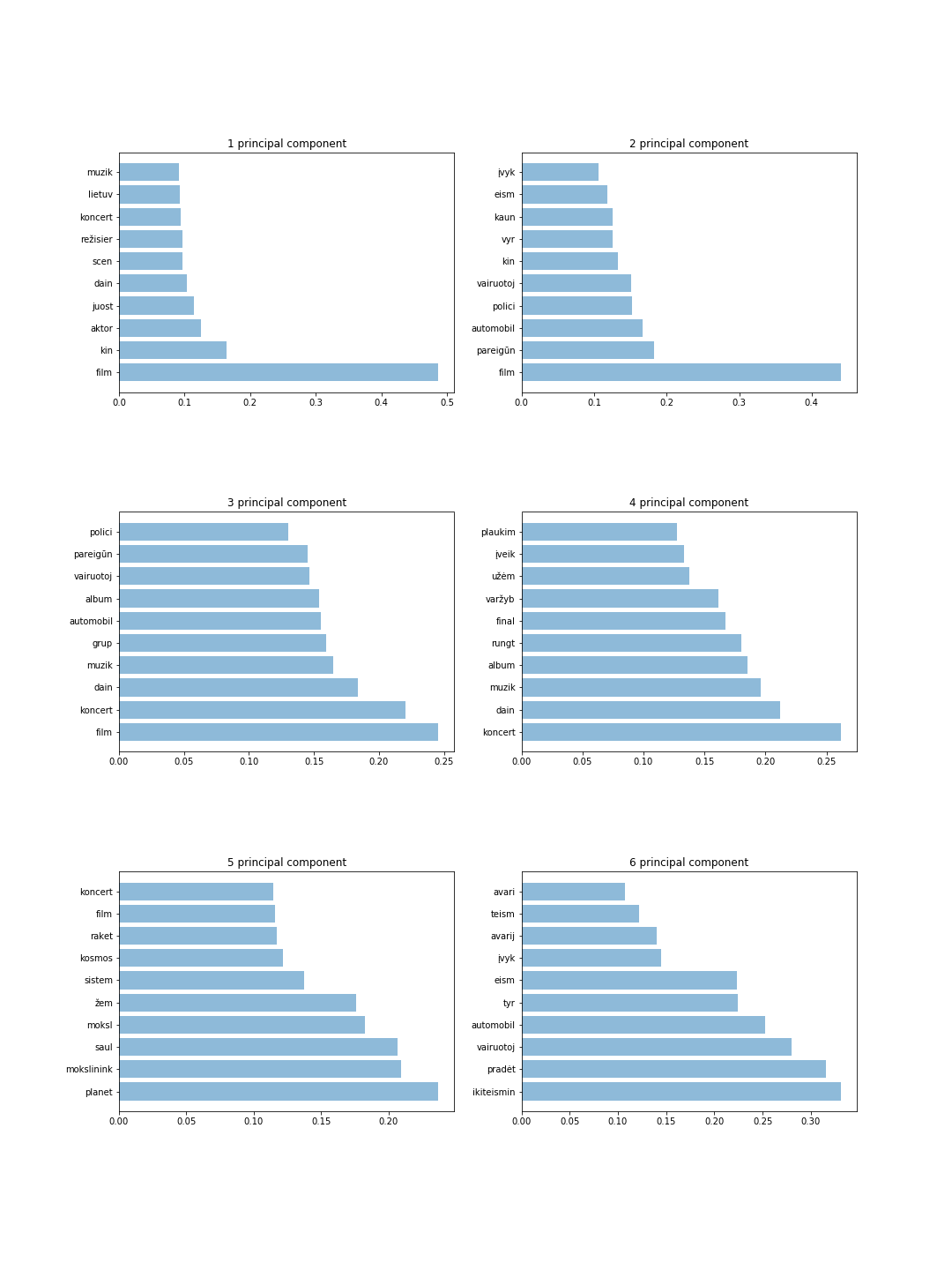
搜索基于 http://webhome.cs.uvic.ca/~thomo/svd.pdf 文章,其中 LSA 不仅使用精确的查询相似性,还使用文档之间更深层的关系来查找相关文档。 
查询=“švietim apdovanojam”
结果:
进行中


