context search engine
1.0.0

该项目的主要目标是通过提供用户友好的界面来展示矢量搜索功能,使用户能够在文本文档语料库中执行上下文搜索。通过利用 Hugging Face 的 BERT 和 Facebook 的 FAISS 的强大功能,我们根据用户查询的语义而不是单纯的关键字匹配返回高度相关的文本段落。该项目是希望更深入地了解上下文文本搜索世界并通过最先进的 NLP 技术增强其应用程序的开发人员、研究人员和爱好者的起点。
我的目标是确保我们从头开始了解幕后的矢量数据库。
应用程序屏幕截图:
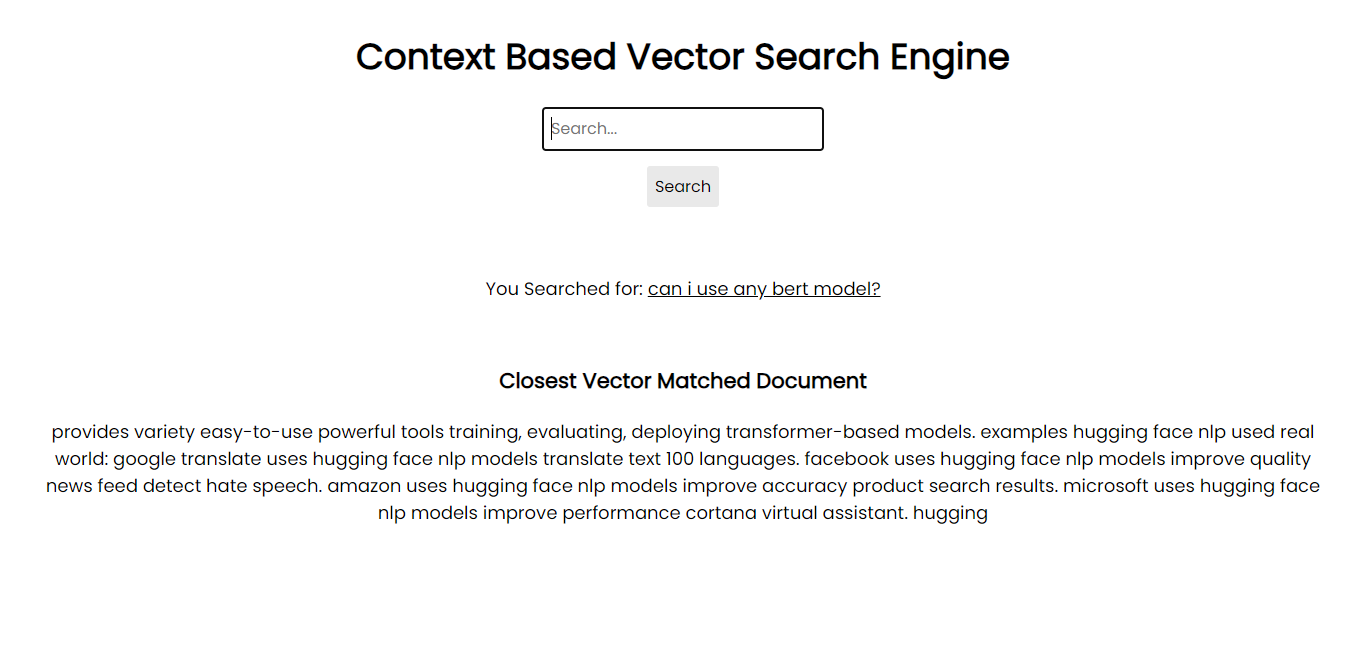
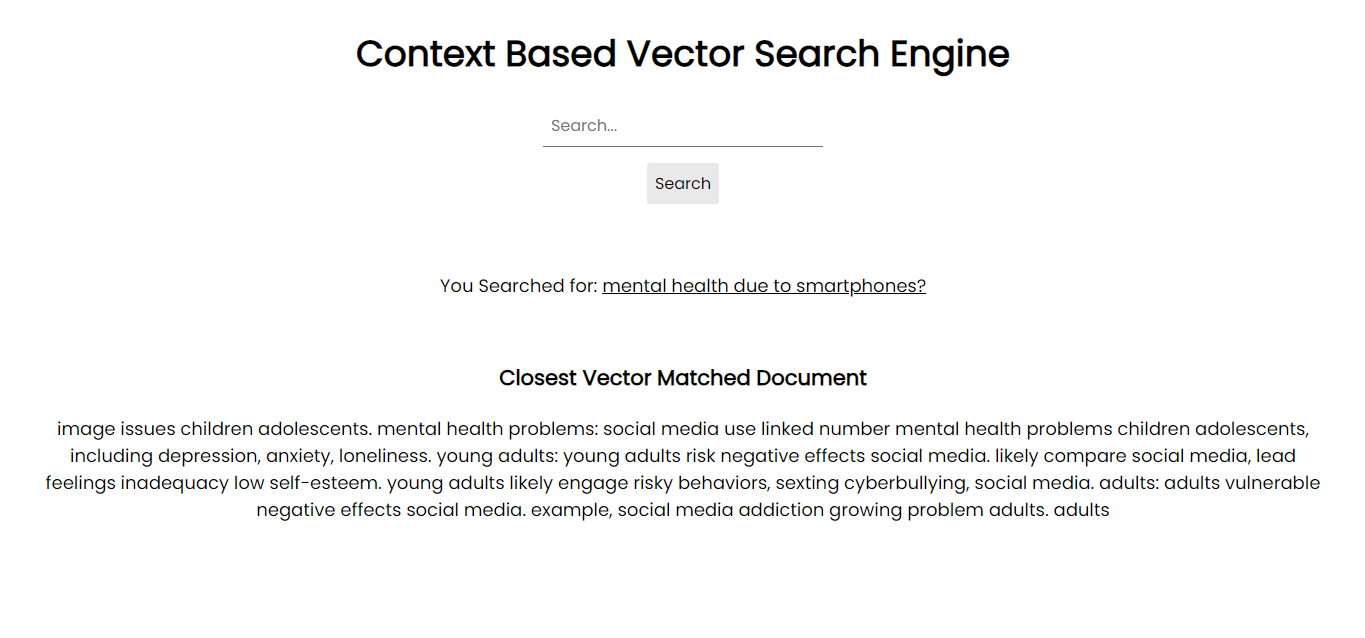
为了在您的系统上运行,您可以使用需求文件通过 pip 安装所有必需的软件包:
pip install -r requirements.txt供您参考,我使用的是 Python 3.10.1。
但是,如果您有 GPU,则需要安装 FAISS GPU 以实现更快、更大的数据库集成。
该项目的当前版本包括:
虽然该项目提供了一个功能性上下文搜索系统,但它被设计为模块化,允许潜在的扩展和集成到更大的系统或应用程序中。
该项目的基础在于相信与传统的基于关键词的方法相比,现代 NLP 技术可以提供更准确且上下文相关的搜索结果。以下是我们方法的细分:
根据该方法,我将该项目分为两个部分:
第 1 部分:生成可搜索向量数据
在本节中,我们首先从文档中读取输入,将其分解为更小的块,使用基于 BERT 的模型创建向量,然后使用 FAISS 有效地存储它。这是说明相同内容的流程图。
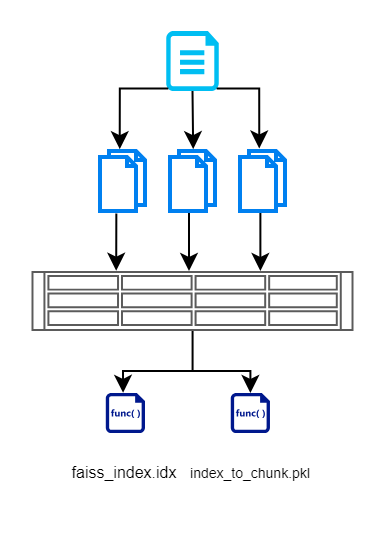
我们创建 FAISS 索引文件,其中包含分块文档的向量表示。我们还存储每个块的索引。这是维护,以便我们不必再次查询数据库/文档。这有助于我们删除冗余的读取操作。
我们使用 create_index.py 执行此部分。它将生成上述2个文件。如果您需要使用其他模型,您愿意从 HuggingFace hub 进行操作吗?
注意:如果您在设置维度超参数时发现问题,请检查模型 config.json 文件以查找有关您尝试使用的模型维度的详细信息。
第 2 部分:构建可搜索的应用程序界面
在本节中,我的目标是构建一个允许用户与文档交互的界面。我优先考虑简约设计,不会造成额外的障碍。
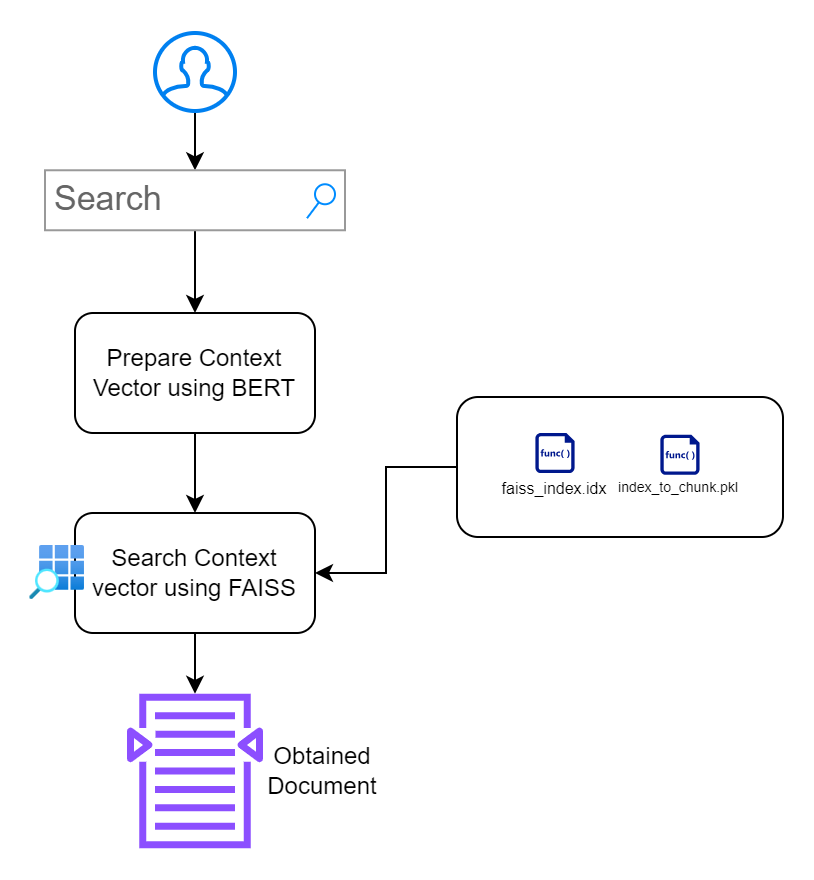
index.html :用于输入搜索查询的前端 HTML 页面。app.py :为前端提供服务并处理搜索查询的 Flask 应用程序。search_engine.py :包含嵌入生成、FAISS 搜索和关键字突出显示的逻辑。 /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) 以及从索引到文本块的随附映射 ( index_to_chunk.pkl )。 python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000 。总是有改进的空间。以下是一些潜在的改进和可以集成的附加功能:
该项目已获得 MIT 许可。请随意引用、修改、分发和贡献。阅读更多。
如果您有兴趣改进这个项目,欢迎您做出贡献!请在此存储库上打开拉取请求或问题。我基本上优先考虑上述事情来进行改进。其他拉取请求也会被考虑,但优先级较低。
预先感谢您的关注。 :快乐的: 。


