textgenrnn
T
只需几行代码,即可在任何文本数据集上轻松训练您自己的任意大小和复杂程度的文本生成神经网络,或者使用预训练模型快速训练文本。
textgenrnn 是 Keras/TensorFlow 之上的一个 Python 3 模块,用于创建 char-rnn,具有许多很酷的功能:
您可以在此 Colaboratory Notebook 中免费使用 textgenrnn 并使用 GPU 训练任何文本文件!阅读此博文或观看此视频以获取更多信息!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
所包含的模型可以轻松地在新文本上进行训练,并且即使在单次输入数据之后也可以生成适当的文本。
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
模型权重相对较小(磁盘上为 2 MB),并且可以轻松保存并加载到新的 textgenrnn 实例中。因此,您可以使用经过数百次数据传递训练的模型。 (事实上,textgenrnn 学习得非常好,以至于您必须显着提高温度才能获得创意输出!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
您还可以通过向任何训练函数添加new_model=True来训练新模型,支持字级嵌入和双向 RNN 层。
也可以逐步参与输出的展开过程。交互模式将建议您下一个字符/单词的前 N 个选项,并允许您选择一个。
在终端中运行 textgenrnn 时,传递interactive=True和top=N来generate . N 默认为 3。
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
这可以为输出添加人情味;感觉你就是作家! (参考)
textgenrnn 可以通过pip从 pypi 安装:
pip3 install textgenrnn对于最新的 textgenrnn,您的 TensorFlow 版本必须至少为 2.1.0 。
您可以在此 Jupyter Notebook 中查看常见功能和模型配置选项的演示。
/datasets包含使用 Hacker News/Reddit 数据训练 textgenrnn 的示例数据集。
/weights包含在上述数据集上进一步预训练的模型,可以将其加载到 textgenrnn 中。
/outputs包含从上述预训练模型生成的文本示例。
textgenrnn 基于 Andrej Karpathy 的 char-rnn 项目,并进行了一些现代优化,例如处理非常小的文本序列的能力。
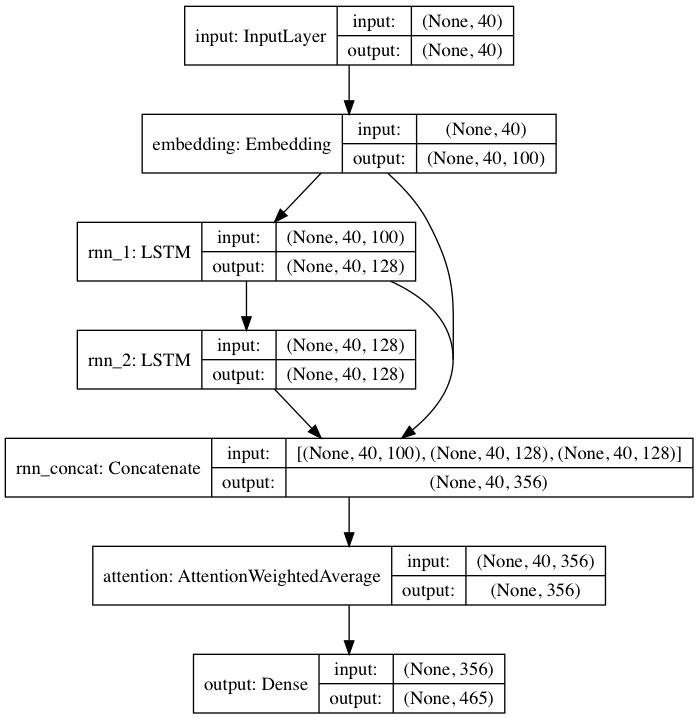
随附的预训练模型遵循受 DeepMoji 启发的神经网络架构。对于默认模型,textgenrnn 接受最多 40 个字符的输入,将每个字符转换为 100 维字符嵌入向量,并将其输入 128 单元长短期记忆 (LSTM) 循环层。然后将这些输出输入另一个128 单元 LSTM。然后将所有三层输入到注意力层中,对最重要的时间特征进行加权并将它们平均在一起(并且由于嵌入+第一个 LSTM 被跳跃连接到注意力层中,因此模型更新可以更轻松地反向传播到它们并防止消失梯度)。该输出被映射到最多 394 个不同字符的概率,这些字符是序列中的下一个字符,包括大写字符、小写字符、标点符号和表情符号。 (如果在新数据集上训练新模型,则可以配置上述所有数字参数)
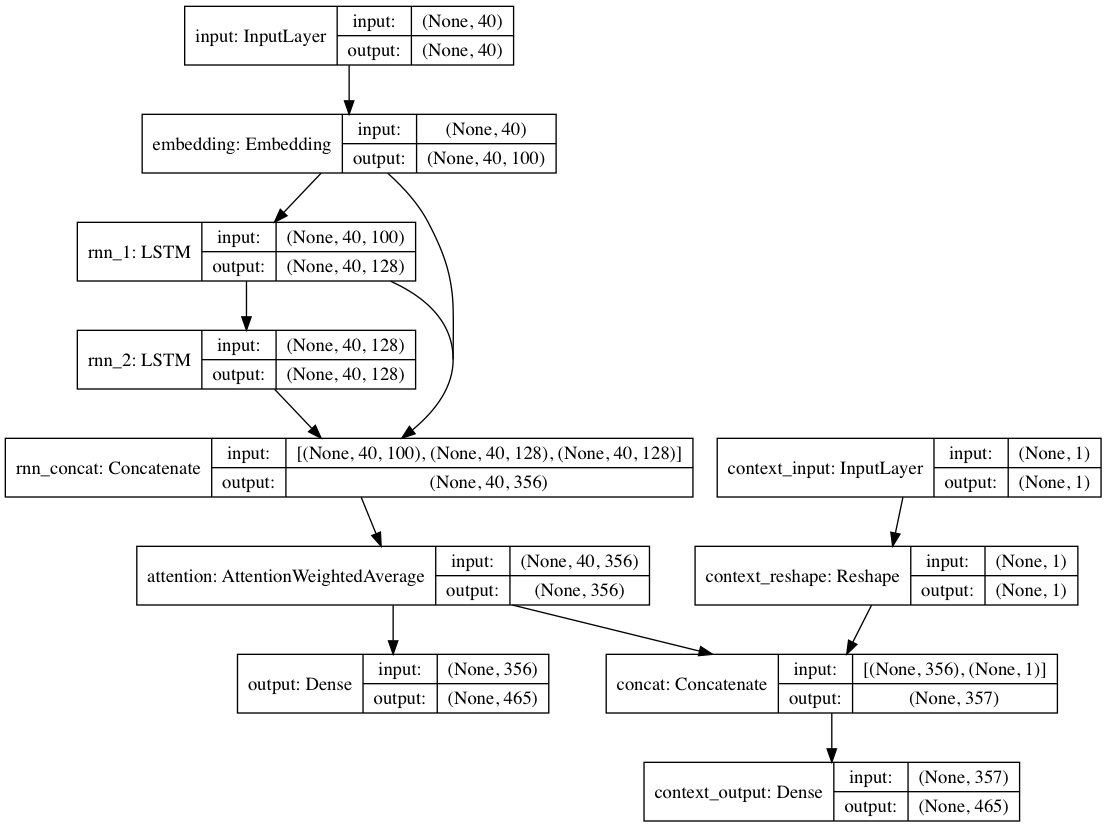
或者,如果每个文本文档都提供上下文标签,则可以在上下文模式下训练模型,其中模型学习给定上下文的文本,以便循环层学习去上下文化的语言。纯文本路径可以搭载脱离上下文的层;总之,与仅根据文本训练模型相比,这会带来更快的训练速度以及更好的定量和定性模型性能。
该包中包含的模型权重是根据来自 Reddit 提交(通过 BigQuery)的数十万个文本文档进行训练的,这些文本文档来自各种Reddit 子版块。该网络还使用上述去上下文方法进行了训练,以提高训练性能并减轻作者偏见。
当使用 textgenrnn 在新的文本数据集上微调模型时,所有图层都会重新训练。然而,由于原始的预训练网络最初具有更强大的“知识”,因此新的 textgenrnn 最终训练得更快、更准确,并且有可能学习原始数据集中不存在的新关系(例如,预训练的字符嵌入包括上下文)用于现代互联网语法所有可能类型的字符)。
此外,再训练是通过基于动量的优化器和线性衰减的学习率完成的,这两者都可以防止梯度爆炸,并使模型在长时间训练后发散的可能性大大降低。
即使使用经过严格训练的神经网络,您也不会 100% 获得高质量的生成文本。这是利用神经网络文本生成的病毒式博客文章/Twitter 推文通常会生成大量文本并随后策划/编辑最好的文本的主要原因。
不同数据集的结果会有很大差异。由于预训练的神经网络相对较小,因此它无法存储博客文章中通常标榜的 RNN 那么多的数据。为了获得最佳结果,请使用至少包含 2,000-5,000 个文档的数据集。如果数据集较小,则在调用训练方法和/或从头开始训练新模型时,您需要通过将num_epochs设置得更高来训练更长时间。即便如此,目前还没有好的启发法来确定“好”模型。
重新训练 textgenrnn 不需要 GPU,但在 CPU 上训练需要更长的时间。如果您确实使用 GPU,我建议增加batch_size参数以获得更好的硬件利用率。
更正式的文档
使用tensorflow.js的基于网络的实现(由于网络规模较小,效果特别好)
一种可视化注意力层输出以了解网络如何“学习”的方法。
允许模型架构用于聊天机器人对话的模式(可以作为单独的项目发布)
更深入地了解上下文(位置上下文+允许多个上下文标签)
更大的预训练网络,可以容纳更长的字符序列和对语言更深入的理解,从而创建更好的生成句子。
字级模型的分层 softmax 激活(一旦 Keras 对其有良好的支持)。
FP16 用于 Volta/TPU 上的超快速训练(一旦 Keras 对其有良好的支持)。
马克斯·伍尔夫 (@minimaxir)
Max 的开源项目得到了他的 Patreon 的支持。如果您发现这个项目有帮助,我们将不胜感激对 Patreon 的任何金钱贡献,并将用于良好的创造性用途。
Andrej Karpathy 通过博客文章《循环神经网络的不合理有效性》提出了 char-rnn 的原始提案。
Daniel Grijalva 贡献了交互模式。
麻省理工学院
使用 DeepMoji 的注意力层代码(MIT 许可)


