stumpy
v1.13.0

STUMPY 是一个强大且可扩展的 Python 库,它可以有效地计算称为矩阵轮廓的东西,这只是一种学术说法,即“对于时间序列中的每个(绿色)子序列,自动识别其相应的最近邻居(灰色)”:
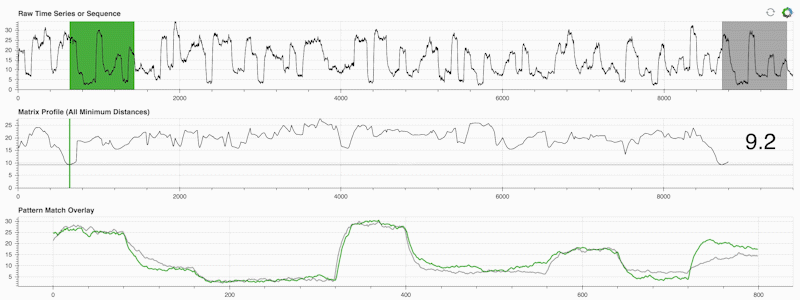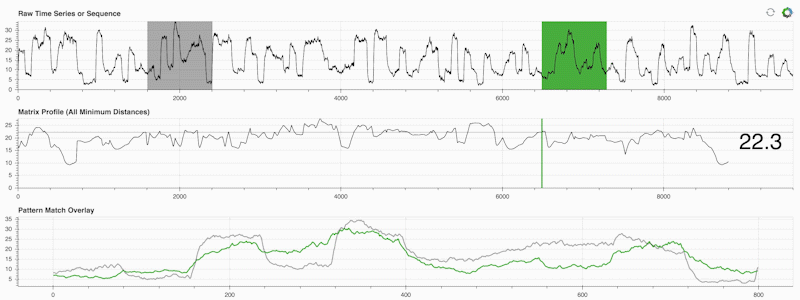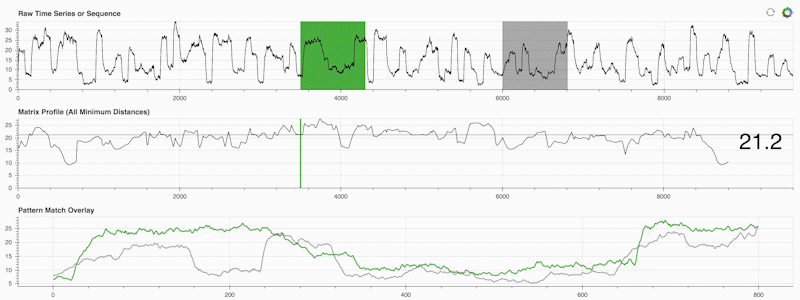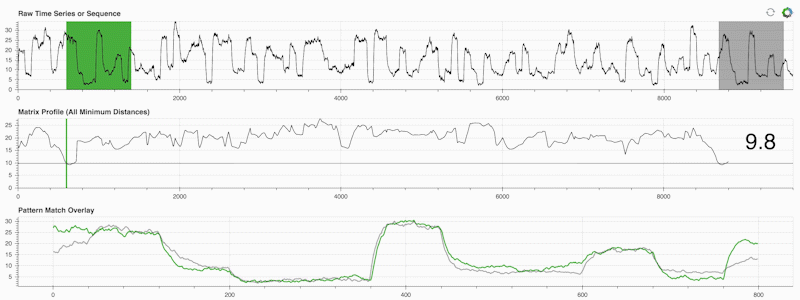
重要的是,一旦计算出矩阵轮廓(上面的中间面板),它就可以用于各种时间序列数据挖掘任务,例如:
无论您是学者、数据科学家、软件开发人员还是时间序列爱好者,STUMPY 的安装都很简单,我们的目标是让您更快地获得时间序列见解。请参阅文档以获取更多信息。
请参阅我们的 API 文档以获取可用函数的完整列表,并参阅我们的信息教程以获取更全面的示例用例。下面,您将找到快速演示如何使用 STUMPY 的代码片段。
STUMP 的典型用法(一维时间序列数据):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )通过 STUMPED 使用 Dask 分布式使用一维时间序列数据:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stumped ( dask_client , your_time_series , m = window_size )使用 GPU-STUMP 处理一维时间序列数据的 GPU 使用情况:
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [ device . id for device in cuda . list_devices ()] # Get a list of all available GPU devices
matrix_profile = stumpy . gpu_stump ( your_time_series , m = window_size , device_id = all_gpu_devices )使用MSTUMP的多维时间序列数据:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstump ( your_time_series , m = window_size )使用Dask Distributed MSTUMPED进行分布式多维时间序列数据分析:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstumped ( dask_client , your_time_series , m = window_size )具有锚定时间序列链 (ATSC) 的时间序列链:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
left_matrix_profile_index = matrix_profile [:, 2 ]
right_matrix_profile_index = matrix_profile [:, 3 ]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy . atsc ( left_matrix_profile_index , right_matrix_profile_index , idx )
all_chain_set , longest_unanchored_chain = stumpy . allc ( left_matrix_profile_index , right_matrix_profile_index )使用快速低成本单能语义分割 (FLUSS) 进行语义分割:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
subseq_len = 50
correct_arc_curve , regime_locations = stumpy . fluss ( matrix_profile [:, 1 ],
L = subseq_len ,
n_regimes = 2 ,
excl_factor = 1
)支持的 Python 和 NumPy 版本根据 NEP 29 弃用政策确定。
Conda 安装(首选):
conda install -c conda-forge stumpyPyPI 安装,假设您安装了 numpy、scipy 和 numba:
python -m pip install stumpy要从源安装 Stumpy,请参阅文档中的说明。
为了充分理解和欣赏底层算法和应用程序,您必须阅读原始出版物。有关如何使用 STUMPY 的更详细示例,请查阅最新文档或浏览我们的实践教程。
我们测试了使用 Numba JIT 编译版本的代码对随机生成的不同长度的时间序列数据(即np.random.rand(n) )以及不同的 CPU 和 GPU 硬件资源计算精确矩阵配置文件的性能。
原始结果在下表中显示为小时:分钟:秒.毫秒,窗口大小恒定为 m = 50。请注意,这些报告的运行时间包括将数据从主机移动到所有主机所需的时间。 GPU 设备。您可能需要滚动到表的右侧才能查看所有运行时。
| 我 | n = 2我 | GPU-STOMP | 树桩.2 | 树桩.16 | 难住了.128 | 难住了.256 | GPU-STUMP.1 | GPU-STUMP.2 | GPU-STUMP.DGX1 | GPU-STUMP.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 64 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.77 | 00:00:06.08 | 00:00:00.03 | 00:00:01.63 | 南 | 南 |
| 7 | 128 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.93 | 00:00:07.29 | 00:00:00.04 | 00:00:01.66 | 南 | 南 |
| 8 | 256 | 00:00:10.00 | 00:00:00.00 | 00:00:00.01 | 00:00:05.95 | 00:00:07.59 | 00:00:00.08 | 00:00:01.69 | 00:00:06.68 | 00:00:25.68 |
| 9 | 第512章 | 00:00:10.00 | 00:00:00.00 | 00:00:00.02 | 00:00:05.97 | 00:00:07.47 | 00:00:00.13 | 00:00:01.66 | 00:00:06.59 | 00:00:27.66 |
| 10 | 1024 | 00:00:10.00 | 00:00:00.02 | 00:00:00.04 | 00:00:05.69 | 00:00:07.64 | 00:00:00.24 | 00:00:01.72 | 00:00:06.70 | 00:00:30.49 |
| 11 | 2048 | 南 | 00:00:00.05 | 00:00:00.09 | 00:00:05.60 | 00:00:07.83 | 00:00:00.53 | 00:00:01.88 | 00:00:06.87 | 00:00:31.09 |
| 12 | 4096 | 南 | 00:00:00.22 | 00:00:00.19 | 00:00:06.26 | 00:00:07.90 | 00:00:01.04 | 00:00:02.19 | 00:00:06.91 | 00:00:33.93 |
| 13 | 8192 | 南 | 00:00:00.50 | 00:00:00.41 | 00:00:06.29 | 00:00:07.73 | 00:00:01.97 | 00:00:02.49 | 00:00:06.61 | 00:00:33.81 |
| 14 | 16384 | 南 | 00:00:01.79 | 00:00:00.99 | 00:00:06.24 | 00:00:08.18 | 00:00:03.69 | 00:00:03.29 | 00:00:07.36 | 00:00:35.23 |
| 15 | 32768 | 南 | 00:00:06.17 | 00:00:02.39 | 00:00:06.48 | 00:00:08.29 | 00:00:07.45 | 00:00:04.93 | 00:00:07.02 | 00:00:36.09 |
| 16 | 65536 | 南 | 00:00:22.94 | 00:00:06.42 | 00:00:07.33 | 00:00:09.01 | 00:00:14.89 | 00:00:08.12 | 00:00:08.10 | 00:00:36.54 |
| 17 号 | 131072 | 00:00:10.00 | 00:01:29.27 | 00:00:19.52 | 00:00:09.75 | 00:00:10.53 | 00:00:29.97 | 00:00:15.42 | 00:00:09.45 | 00:00:37.33 |
| 18 | 262144 | 00:00:18.00 | 00:05:56.50 | 00:01:08.44 | 00:00:33.38 | 00:00:24.07 | 00:00:59.62 | 00:00:27.41 | 00:00:13.18 | 00:00:39.30 |
| 19 | 524288 | 00:00:46.00 | 00:25:34.58 | 00:03:56.82 | 00:01:35.27 | 00:03:43.66 | 00:01:56.67 | 00:00:54.05 | 00:00:19.65 | 00:00:41.45 |
| 20 | 1048576 | 00:02:30.00 | 01:51:13.43 | 00:19:54.75 | 00:04:37.15 | 00:03:01.16 | 00:05:06.48 | 00:02:24.73 | 00:00:32.95 | 00:00:46.14 |
| 21 | 2097152 | 00:09:15.00 | 09:25:47.64 | 03:05:07.64 | 00:13:36.51 | 00:08:47.47 | 00:20:27.94 | 00:09:41.43 | 00:01:06.51 | 00:01:02.67 |
| 22 | 4194304 | 南 | 36:12:23.74 | 10:37:51.21 | 00:55:44.43 | 00:32:06.70 | 01:21:12.33 | 00:38:30.86 | 00:04:03.26 | 00:02:23.47 |
| 23 | 8388608 | 南 | 143:16:09.94 | 38:42:51.42 | 03:33:30.53 | 02:00:49.37 | 05:11:44.45 | 02:33:14.60 | 00:15:46.26 | 00:08:03.76 |
| 24 | 16777216 | 南 | 南 | 南 | 14:39:11.99 | 07:13:47.12 | 20:43:03.80 | 09:48:43.42 | 01:00:24.06 | 00:29:07.84 |
| 南 | 17729800 | 09:16:12.00 | 南 | 南 | 15:31:31.75 | 07:18:42.54 | 23:09:22.43 | 10:54:08.64 | 01:07:35.39 | 00:32:51.55 |
| 25 | 33554432 | 南 | 南 | 南 | 56:03:46.81 | 26:27:41.29 | 83:29:21.06 | 39:17:43.82 | 03:59:32.79 | 01:54:56.52 |
| 26 | 67108864 | 南 | 南 | 南 | 211:17:37.60 | 106:40:17.17 | 328:58:04.68 | 157:18:30.50 | 15:42:15.94 | 07:18:52.91 |
| 南 | 100000000 | 291:07:12.00 | 南 | 南 | 南 | 234:51:35.39 | 南 | 南 | 35:03:44.61 | 16:22:40.81 |
| 27 | 134217728 | 南 | 南 | 南 | 南 | 南 | 南 | 南 | 64:41:55.09 | 29:13:48.12 |
GPU-STOMP:这些结果来自原始 Matrix Profile II 论文 - NVIDIA Tesla K80(包含 2 个 GPU),并作为性能基准进行比较。
STUMP.2:stumpy.stump 总共使用 2 个 CPU 执行 - 2 个 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 处理器,在没有 Dask 的单个服务器上与 Numba 并行。
STUMP.16:stumpy.stump 总共使用 16 个 CPU 执行 - 16 个 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 处理器,在没有 Dask 的单个服务器上与 Numba 并行。
STUMPED.128:stumpy.stumped 总共使用 128 个 CPU 执行 - 8 个 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 处理器 x 16 个服务器,与 Numba 并行,并使用 Dask Distributed 进行分发。
STUMPED.256:stumpy.stumped 总共使用 256 个 CPU 执行 - 8 个 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 处理器 x 32 个服务器,与 Numba 并行,并使用 Dask Distributed 进行分发。
GPU-STUMP.1:stumpy.gpu_stump 使用 1x NVIDIA GeForce GTX 1080 Ti GPU 执行,每块 512 个线程,200W 功率限制,使用 Numba 编译为 CUDA,并使用 Python 多处理并行化
GPU-STUMP.2:stumpy.gpu_stump 使用 2 个 NVIDIA GeForce GTX 1080 Ti GPU 执行,每块 512 个线程,200W 功率限制,使用 Numba 编译为 CUDA,并使用 Python 多处理并行化
GPU-STUMP.DGX1:stumpy.gpu_stump 使用 8x NVIDIA Tesla V100 执行,每块 512 个线程,使用 Numba 编译为 CUDA,并使用 Python 多处理并行化
GPU-STUMP.DGX2:stumpy.gpu_stump 使用 16x NVIDIA Tesla V100 执行,每块 512 个线程,使用 Numba 编译为 CUDA,并使用 Python 多处理并行化
测试编写在tests目录中并使用 PyTest 进行处理,并且需要coverage.py进行代码覆盖率分析。可以通过以下方式执行测试:
./test.shSTUMPY 支持 Python 3.9+,并且由于使用 unicode 变量名称/标识符,与 Python 2.x 不兼容。鉴于依赖性较小,STUMPY 可能可以在旧版本的 Python 上运行,但这超出了我们的支持范围,我们强烈建议您升级到最新版本的 Python。
首先,请检查 Github 上的讨论和问题,看看您的问题是否已经得到解答。如果没有可用的解决方案,请随时提出新的讨论或问题,作者将尝试以合理及时的方式做出回应。
我们欢迎任何形式的贡献!始终欢迎文档方面的帮助,特别是扩展教程。要做出贡献,请分叉该项目,进行更改并提交拉取请求。我们将尽力与您解决任何问题,并将您的代码合并到主分支中。
如果您已在科学出版物中使用此代码库并希望引用它,请使用开源软件杂志文章。
SM 法,(2019)。 STUMPY:用于时间序列数据挖掘的强大且可扩展的 Python 库。开源软件杂志,4(39), 1504。
@article { law2019stumpy ,
author = { Law, Sean M. } ,
title = { {STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining} } ,
journal = { {The Journal of Open Source Software} } ,
volume = { 4 } ,
number = { 39 } ,
pages = { 1504 } ,
year = { 2019 }
}是的,Chin-Chia Michael 等人。 (2016) 矩阵配置文件 I:时间序列的所有对相似性连接:包括 Motifs、Discords 和 Shapelet 的统一视图。 ICDM:1317-1322。关联
朱彦等人。 (2016) Matrix Profile II:利用新颖的算法和 GPU 突破时间序列主题和连接的一亿个障碍。 ICDM:739-748。关联
是的,Chin-Chia Michael 等人。 (2017) 矩阵剖面 VI:有意义的多维主题发现。 ICDM:565-574。关联
朱彦等人。 (2017) 矩阵简介 VII:时间序列链:时间序列数据挖掘的新原语。 ICDM:695-704。关联
加尔加比、沙加耶格等人。 (2017) 矩阵简介 VIII:超人性能水平的领域不可知在线语义分割。 ICDM:117-126。关联
朱彦等人。 (2017) 利用新颖的算法和 GPU 打破时间序列主题和连接的 10 个千万亿的成对比较障碍。凯斯:203-236。关联
朱彦等人。 (2018) 矩阵概要 XI:SCRIMP++:交互式速度的时间序列基序发现。 ICDM:837-846。关联
是的,Chin-Chia Michael 等人。 (2018) 时间序列连接、主题、不和谐和 Shapelet:利用矩阵轮廓的统一视图。数据最小知识光盘:83-123。关联
加尔加比、沙加耶格等人。 (2018)“矩阵概要 XII:MPdist:一种新颖的时间序列距离测量,可在更具挑战性的场景中进行数据挖掘。” ICDM:965-970。关联
齐默尔曼、扎卡里等人。 (2019) Matrix Profile XIV:使用 GPU 扩展时间序列基序发现,每天突破数十亿次配对比较。 SoCC '19:74-86。关联
阿克巴里尼亚、礼萨和贝特兰德·克洛兹。 (2019) 使用不同距离函数的高效矩阵轮廓计算。 arXiv:1901.05708。关联
卡姆加尔、卡维等人。 (2019) 矩阵剖面 XV:利用时间序列共识模式来查找时间序列集中的结构。 ICDM:1156-1161。关联


