genai_robotics
1.0.0
该存储库包含一个实验性的、具有隐私意识的设置,用于在机器人控制中利用生成式人工智能方法。通过这里提出的解决方案,用户可以通过语音自由定义动作,这些动作被转换成机器人吸尘器可以在摄像机观察到的开放世界环境中执行的计划。
这里介绍的方法的基本优点是:
该系统是在为期 3 天的黑客马拉松中开发的,作为学习练习和概念证明,现代人工智能工具可以显着缩短机器人控制解决方案的开发时间。
要使用此存储库的所有功能,您应该拥有以下内容:
首先,请按照以下步骤操作:
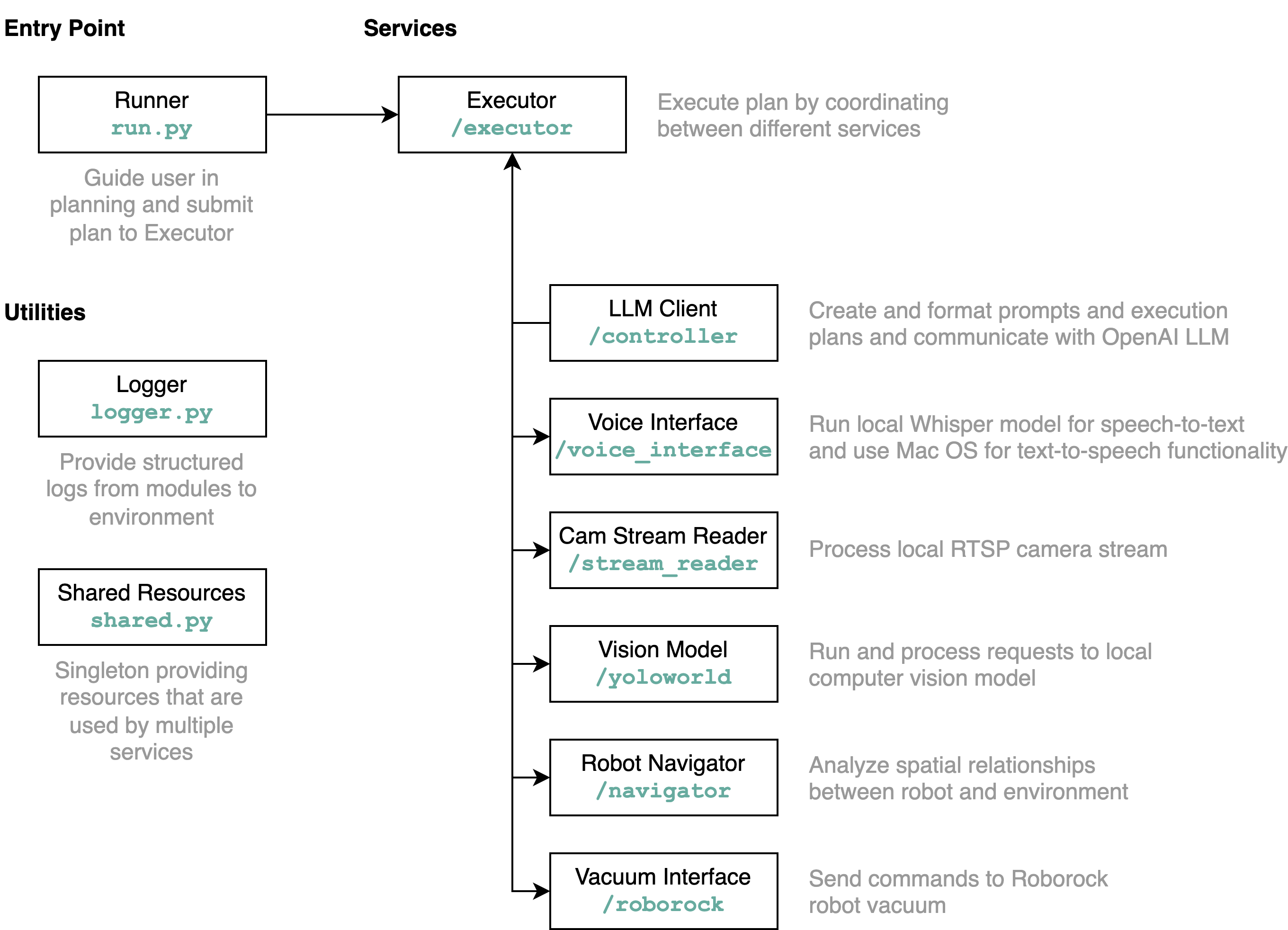
requirements.txt中的需求安装到Python环境中(使用Python 3.11进行测试)src/config.template.toml重命名为config.toml 。对于以下所有步骤,请将获取的凭据插入到config.toml中python-roborock库的文档中阅读有关如何执行此操作的更多信息。src/run.py来运行工作流程。 了解此存储库详细功能以及元素如何交互的最佳方法是通过架构图:
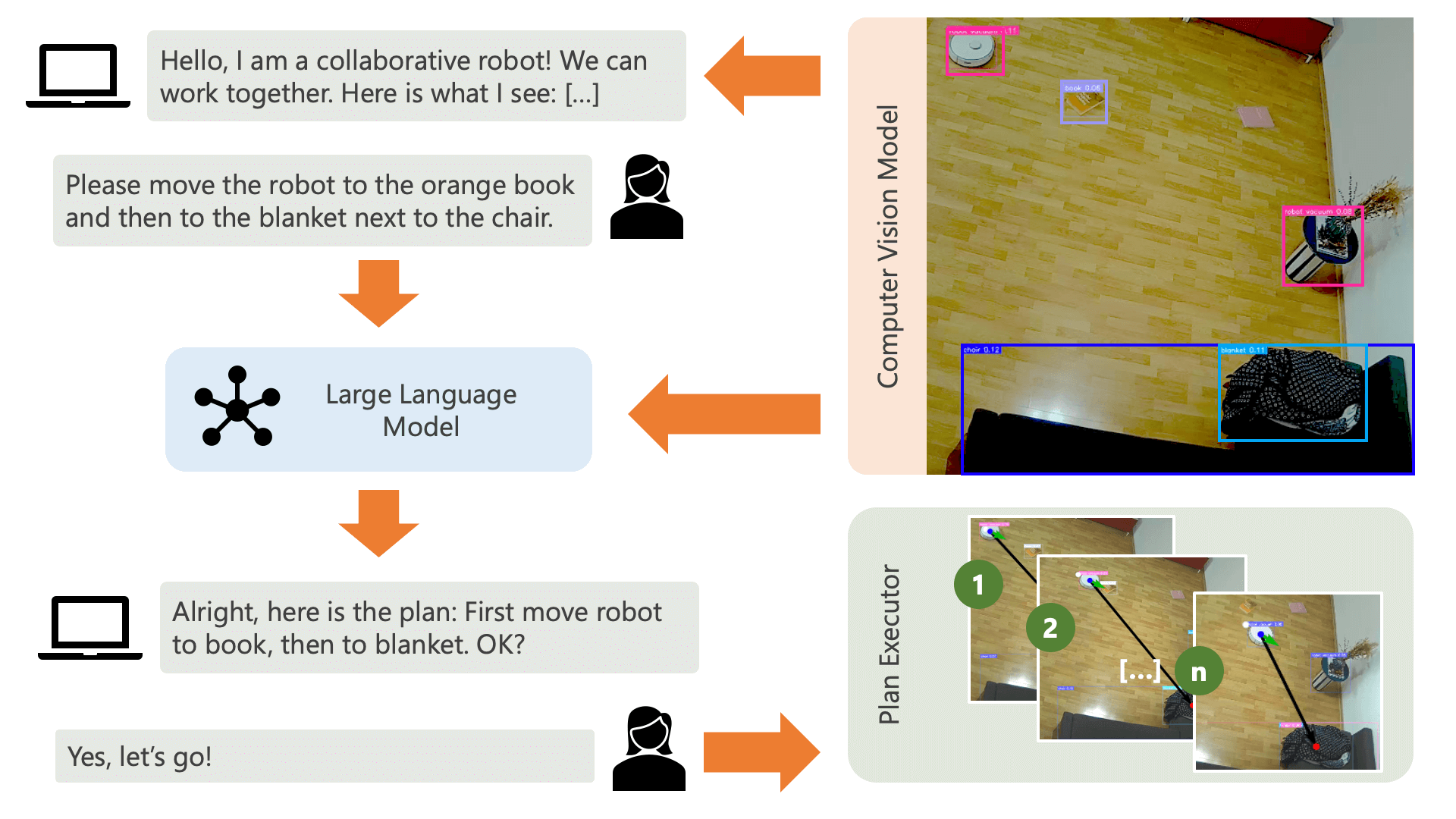
当您如上所述运行run.py文件时,会发生以下情况及其工作原理:
系统通过音频消息向用户致意,并希望他们告诉系统他们想要做什么。例如,用户可能希望机器人从坐在黄色椅子上的人那里拿起咖啡,然后将其运送给坐在黑色沙发上的另一个人。然后系统将创建一个计划来执行这些操作。
系统需要了解什么才能实现用户想要做的事情?系统需要了解其环境以及可以在该环境中执行的操作。在这里,我们使用具有对象检测功能的计算机视觉模型来向系统提供有关环境的信息。吸尘器本身可以执行 3 个简单的动作:向前移动、转动和不执行任何操作。环境中的另一个操作是等待用户执行某个操作。
为了避免用户方面的困惑,用户了解人工智能如何感知其环境非常重要。例如,如果计算机视觉模型无法识别某个物体,人工智能将无法将其纳入计划中。同样重要的是,用户要意识到模型识别存在不确定性。使用 OpenAI 的 GPT-4o 大语言模型和描述提示,系统会对其环境进行解释,并在询问用户希望系统做什么之前将其读给用户。
给定环境信息和用户输入的关于他们想要做什么的信息,系统就可以制定一个计划。在这里,我们要求法学硕士根据用户的输入和环境的描述制定一个计划。您可以在controller目录中找到提示模板。这里令人兴奋的技巧是,法学硕士只能通过根据计算机视觉模型的输出生成的两个表来了解其环境。这是一个例子:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
一旦法学硕士处理了计划提示,它就会输出两件事:推理和计划。在系统继续执行计划之前,它将使用解释提示生成计划的简短摘要,以便用户确认该计划符合他们要求执行的操作。这本着“人在环”方法的精神,我们的运作立场是,在真实、开放的物理环境中,人们可能会受到人工智能行为的伤害,因此要求人类参与是合理的。在人工智能继续执行它自己提出的任何计划之前提供反馈。
一旦用户确认,系统就会继续执行计划。由法学硕士生成的这样的计划可能如下所示:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
]使用executor ,系统逐步执行计划。为了减少所需的设置时间,机器人控制遵循简单、不准确但有效的算法:
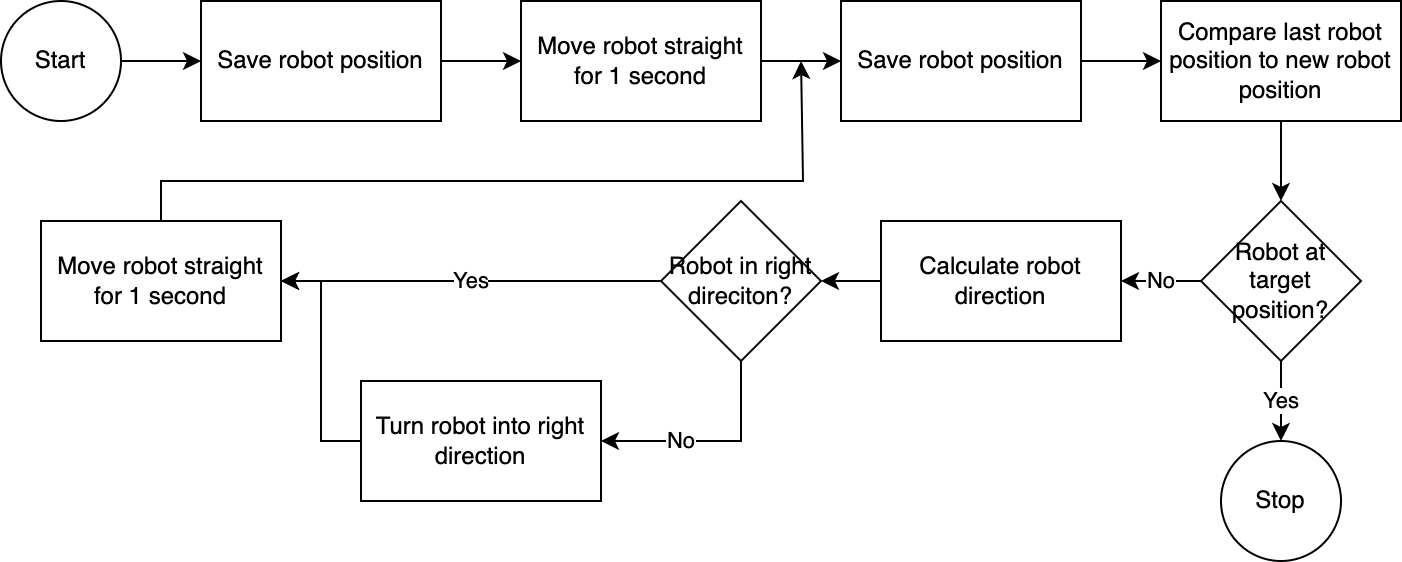
计算机视觉系统评估机器人的位置。通过navigator模块中的代码,分析和比较机器人相对于其目标位置和相对于其最后已知位置的位置。这种方法并不完美,因为没有考虑相机的位置和镜头畸变。通过这种方法测量的角度不准确。然而,由于系统是迭代的,因此经常会补偿错误。然而,值得注意的是,这是以速度为代价的。该系统速度很慢,因为需要时间来分析图像、计算路径并通知机器人下一步要采取的步骤。
一旦机器人到达目标位置,执行器就会继续执行计划的下一步。对于涉及用户输入的操作,执行器将使用文本转语音和语音转文本功能与用户交互。
在这个系统中,我们主要使用在本地计算机或网络上运行的服务。 GPT-4o 是个例外。我们通过互联网将文本数据发送到 OpenAI 的模型。文本数据包括转录的用户输入和识别的对象表。我们在这里使用 GPT-4o 的唯一原因是因为这是黑客马拉松时可用的最佳模型之一 - 我们还可以运行本地 LLM,然后在没有连接到互联网的情况下完全工作,从而在整个流程中保护隐私。运营。
该存储库中包含的计算机视觉模型是由 YOLO-World 模型在 HuggingFace 空间中生成的,提示如下: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human 。如果您想识别其他物体,请调整提示并通过此空间下载 ONNX 模型。然后,您可以替换src/yoloworld/models/rev0目录中的模型。
请注意,为了正确提取模型,您需要在导出模型之前手动更改 HuggingFace 空间中的最大框数和得分阈值参数。
您可以在 YOLO-World 网站上了解有关令人兴奋的 YOLO-World 模型的更多信息,该模型建立在视觉语言建模的最新进展之上。
该项目是在 MIT 许可证下发布的。
该存储库没有受到主动监控,也无意扩展它——它首先是一个学习练习。但是,如果您受到启发,请随时通过打开 GitHub 问题或拉取请求为该项目做出贡献。


