full stack on prem cv mlops
1.0.0
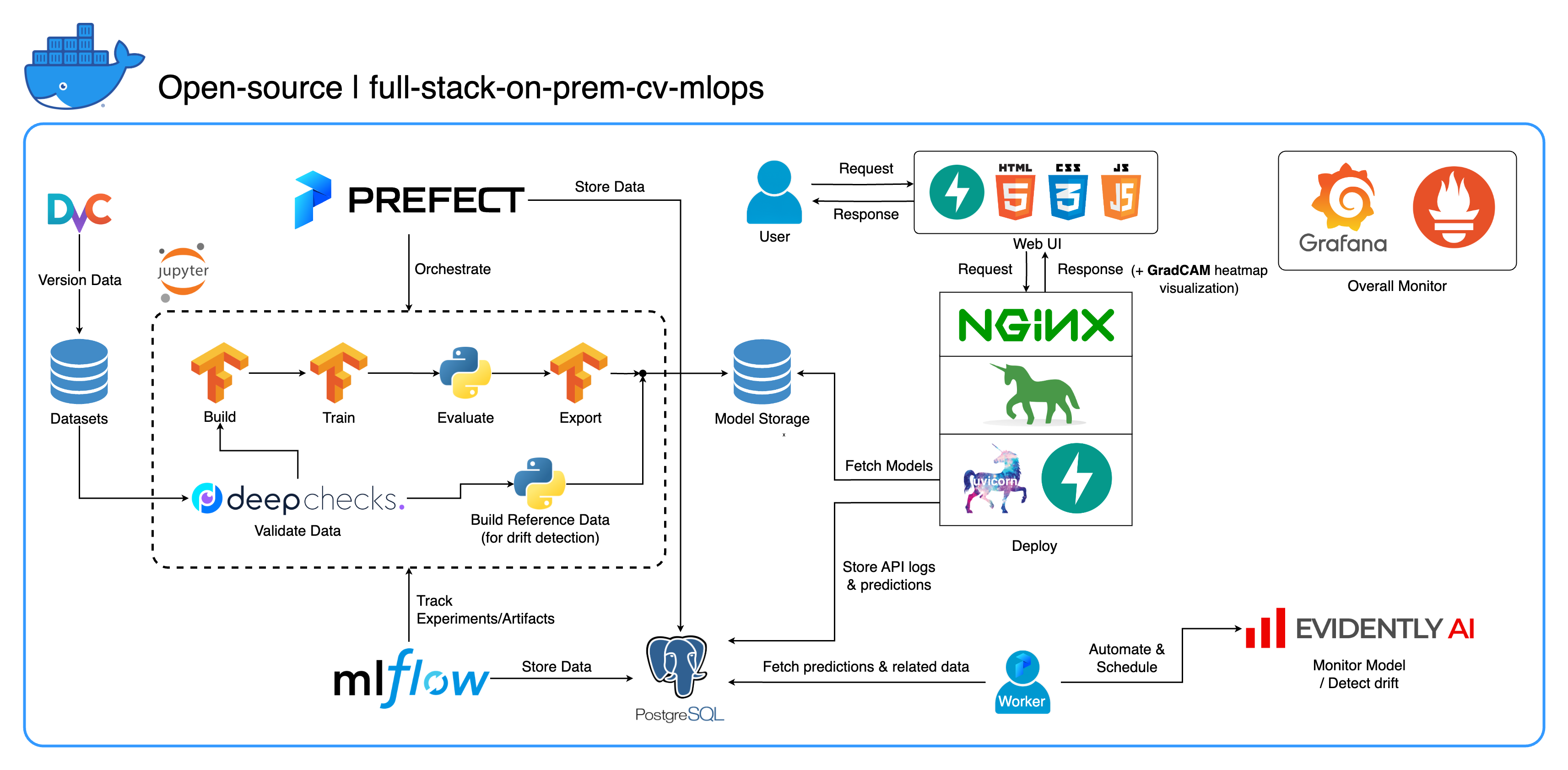
欢迎来到我们专为计算机视觉任务设计的全面的本地 MLOps 生态系统,主要关注图像分类。该存储库为您提供了所需的一切,从 Jupyter Lab/Notebook 中的开发工作区到生产级服务。最好的部分?只需“1个配置和1个命令”即可运行整个系统从构建模型到部署!我们集成了许多最佳实践,以确保可扩展性和可靠性,同时保持灵活性。虽然我们的主要用例围绕图像分类,但我们的项目结构可以轻松适应各种 ML/DL 开发,甚至从本地过渡到云!
另一个目标是展示如何集成所有这些工具并使它们在一个完整的系统中协同工作。如果您对特定组件或工具感兴趣,请随意挑选适合您项目需求的组件或工具。
整个系统被容器化到单个 Docker Compose 文件中。要设置它,您所要做的就是运行docker-compose up !这是一个完全本地部署的系统,这意味着不需要云帐户,并且使用整个系统不会花费您一毛钱!
我们强烈建议您观看演示视频部分中的演示视频,以获得全面的概述并了解如何将此系统应用到您的项目中。这些视频包含的重要细节可能太长且不够清晰,无法在此处介绍。
演示:https://youtu.be/NKil4uzmmQc
深入的技术演练:https://youtu.be/l1S5tHuGBA8
视频中的资源:
要使用此存储库,您只需要 Docker。作为参考,我们在 Mac M1 上使用Docker 版本 24.0.6、构建 ed223bc和Docker Compose 版本 v2.21.0-desktop.1 。
我们在这个项目中实施了一些最佳实践:
tf.data for TensorFlow 实现高效数据加载器/管道imgaug lib 进行图像增强,与 TensorFlow 的核心函数相比,增强选项具有更大的灵活性os.env进行重要或服务级别的配置logging模块而不是print进行日志记录.env动态配置docker-compose.yml中的变量default.conf.template优雅地在 Nginx 配置中应用环境变量(Nginx 1.19 中的新功能)大多数端口都可以在此存储库根目录下的 .env 文件中自定义。以下是默认值:
123456789 )[email protected] ,密码: SuperSecurePwdHere )admin ,密码: admin )如果您不使用基于 ARM 的计算机(我们使用 Mac M1 进行开发),则必须考虑在docker-compose.yml中注释这些platform: linux/arm64行。否则这个系统就无法工作。
--recurse-submodules标志: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdocker-compose.yml中取消注释jupyter服务下的deploy部分,并将services/jupyter/Dockerfile中的基础镜像从ubuntu:18.04更改为nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (文本在文件中,您只需注释和取消注释)即可利用您的 GPU。您可能还需要在主机上安装nvidia-container-toolkit才能使其正常工作。对于 Windows/WSL2 用户,我们发现这篇文章非常有帮助。docker-compose up或docker-compose up -d以分离终端。datasets/animals10-dvc处的 DvC 子模块,然后按照如何使用部分中的步骤操作。 http://localhost:8888/labcd ~/workspace/docker-compose.yml中配置) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasks目录中创建flows目录中创建的流中调用run_flow.py进行调用。start(config)函数。该函数接受 Python 字典形式的配置,然后基本上调用该文件中的特定流程。datasets目录内,并且它们都应具有与此存储库内的目录结构相同的目录结构。~/ariya/中的central_storage应包含至少 2 个名为models和ref_data的子目录。这个central_storage服务于对象存储目的,存储要在开发和部署环境中使用的所有暂存文件。 (如果您想部署在云上并使其更具可扩展性,这是您可以考虑更改为云存储服务的事情之一)重要如果您想更改约定,请务必格外小心(因为这些内容是绑定在系统的不同部分并使用的):
central_storage路径 -> 里面应该有models/ ref_data/子目录<model_name>.yaml 、 <model_name>_uae 、 <model_name>_bbsd 、 <model_name>_ref_data.parquetcurrent_model_metadata_file和monitor_pool_namecomputer-viz-dl (默认值)的预安装Conda环境,以及该存储库所需的所有包。所有 Python 命令/代码都应该在此 Jupyter 中运行。central_storage卷充当整个开发和部署过程中使用的中央文件存储。它主要包含Parquet格式的模型文件(包括漂移检测器)和参考数据。在模型训练步骤结束时,新模型将保存在此处,部署服务将从该位置提取模型。 (注意:这是替换云存储服务以实现可扩展性的理想场所。)model部分构建分类器模型。该模型是使用TensorFlow构建的,其架构在tasks/model.py:build_model处进行硬编码。dataset部分准备用于训练的数据集。此步骤使用DvC来检查磁盘中数据与config中指定版本的一致性。如果有更改,它会以编程方式将其转换回指定版本。如果您想保留更改,以防万一您正在试验数据集,您可以将配置中的dvc_checkout字段设置为false ,以便 DvC 不会执行其操作。train部分构建数据加载器并开始训练过程。使用MLflow跟踪和记录实验信息和工件。注意:DeepChecks 的结果报告( .html文件)也上传到 MLflow 上的训练实验以供约定。model部分构建模型元数据文件。central_storage (在本例中,它只是复制到central_storage位置。您可以更改此步骤以将文件上传到云存储)model/drift_detection部分构建漂移检测器。central_storage 。central_storage 。central_storage获取新训练的模型。 (这是教程演示视频中讨论的一个问题,请观看以了解更多详细信息)current_model_metadata_file存储以.yaml结尾的模型元数据文件名, monitor_pool_name存储用于部署 Prefect 工作器和流程的工作池名称。cd到deployments/prefect-deployments并使用配置中的deploy/prefect部分的输入运行prefect --no-prompt deploy --name {deploy_name} 。由于此存储库中的所有内容都已经进行了 Docker 化和容器化,因此将服务从本地转换为云端非常简单。当您完成服务 API 的开发和测试后,您可以通过从 Dockerfile 构建容器来分离services/dl_service ,并将其推送到云容器注册表服务(例如 AWS ECR)。就是这样!
注意:如果您想在实际生产环境中使用服务代码,则存在一个潜在的问题。我已经在深度视频中解决了这个问题,我建议您花一些时间观看整个视频。 
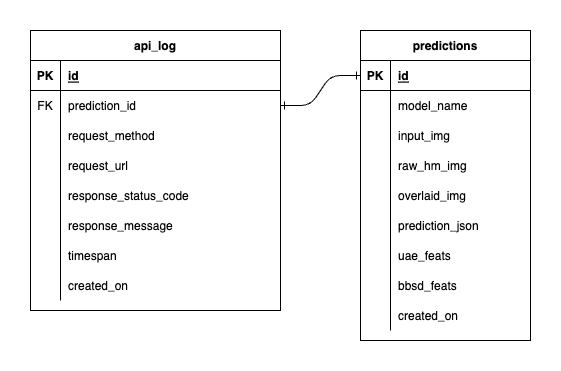
我们在 PostgreSQL 中拥有三个数据库:一个用于 MLflow,一个用于 Prefect,另一个是我们为 ML 模型服务创建的。我们不会深入研究前两个,因为它们是由这些工具自行管理的。我们的 ML 模型服务的数据库是我们自己设计的。
为了避免过于复杂,我们只使用两个表来保持简单。关系和属性显示在下面的 ERD 中。从本质上讲,我们的目标是存储有关传入请求和我们的服务响应的基本详细信息。所有这些表都是自动创建和操作的,因此您无需担心手动设置。
值得注意的是: input_img 、 raw_hm_img和overlaid_img是存储为字符串的 Base64 编码图像。 uae_feats和bbsd_feats是我们的漂移检测算法的嵌入特征数组。
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block错误,请尝试export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0然后重新运行您的脚本。

