qwen2 in a lambda
1.0.0
更新于 11/09/2024
(标记日期是因为 Python 中的 LLM API 发展得非常快,并且在其他人阅读本文时可能会引入重大更改!)
这是一个关于如何使用 Docker 和 SAM CLI 将 Qwen GGUF 模型文件放入 AWS Lambda 的小研究
改编自https://makit.net/blog/llm-in-a-lambda-function/
我想知道是否可以通过仅利用 Lambda 的功能而不是 Lambda + Bedrock 来减少 AWS 支出,因为从长远来看,这两种服务都会产生更多成本。
这个想法是为了适应一个小型语言模型,相对而言,该模型不会那么资源密集,并且希望在 128 - 256 mb 内存配置上接收亚秒到秒的延迟
我还想使用 GGUF 模型来使用不同级别的量化来找出加载到内存中的最佳性能/文件大小
qwen2-1_5b-instruct-q5_k_m.gguf到qwen_fuction/function/app.y / LOCAL_PATH中更改模型路径qwen_function/function/requirements.txt下安装 pip 包(最好在 venv/conda 环境中)sam build / sam validatesam local start-api在本地进行测试curl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate提示LLMsam deploy --guided以部署到 AWS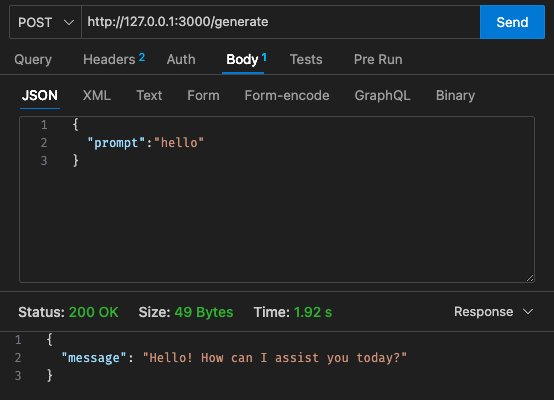
AWS
初始配置 - 128mb,30 秒超时
调整后的配置 #1 - 512mb,30 秒超时
调整后的配置 #2 - 512mb,30 秒超时
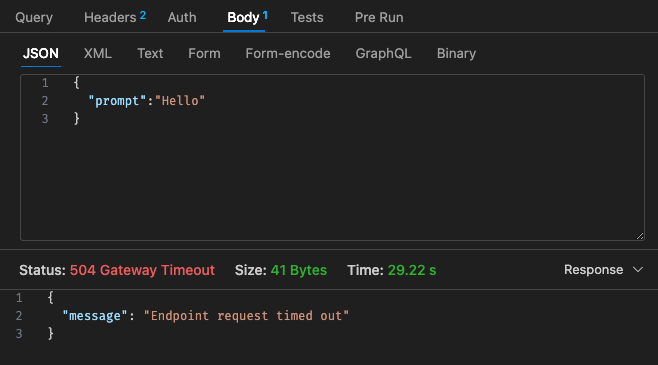
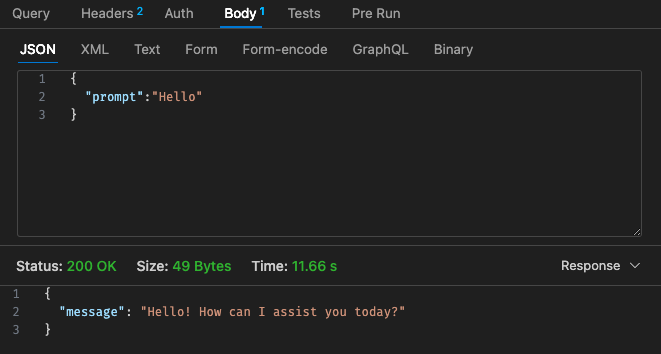
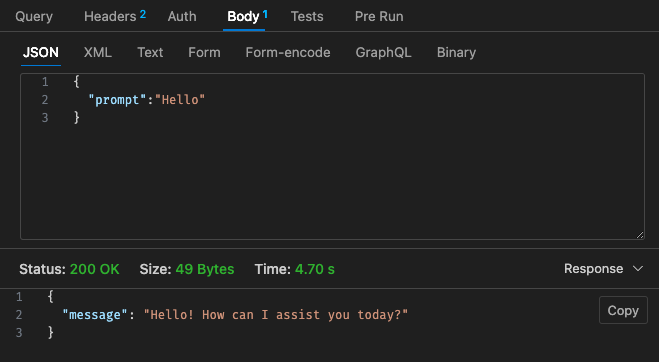
回顾 Lambda 的定价结构,
仅在云上使用使用 AWS Bedrock 等的托管 LLM 可能会更便宜,因为与 Claude 3 Haiku 相比,带有 Qwen 的 Lambda 的定价结构看起来并不更具竞争力
此外,API 网关超时不容易配置为超过 30 秒超时,具体取决于您的用例,这可能不是很理想
本地结果取决于您的机器规格!并且可能会严重扭曲您的看法、期望与现实
另外,根据您的使用案例,每个 lambda 调用和响应的延迟可能会导致较差的用户体验
总而言之,我认为这是一个有趣的小实验,尽管它并没有完全满足我的业余项目 Qwen 1.5b 的预算和延迟要求。再次感谢@makit 的指导!


