genkitx hnsw
1.0.0

您可以在此存储库中对此插件做出贡献。
HNSW 是矢量数据库分层可导航小世界 (HNSW) 图是矢量相似性搜索中表现最好的索引之一。 HNSW 是一项非常受欢迎的技术,它一次又一次地产生最先进的性能,具有超快的搜索速度和出色的召回率。了解有关 HNSW 的更多信息。
如果您愿意,您可以更喜欢这个矢量数据库
通过此功能,您可以在生成式 AI 中实现高性能的检索增强生成 (RAG),因此您无需构建自己的 AI 模型或重新训练 AI 模型来获取更多上下文或知识,而是可以添加额外的上下文层,以便您的 AI 模型可以理解比基础 AI 模型更多的知识。如果您想根据您定义的特定信息或知识获得更多上下文或更多知识,这非常有用。
你有餐厅应用程序或网站,你可以添加有关你的餐厅、地址、食物菜单列表及其价格和其他特定信息的具体信息,这样当你的客户向人工智能询问有关你的餐厅的问题时,你的人工智能可以准确地回答。这可以消除您构建聊天机器人的精力,您可以使用富含特定知识的生成式人工智能。
对话示例:
You :我在泗水市的餐厅的价格表是多少?
AI : 价格表:
在安装插件之前,请确保已安装以下先决条件:
npm install -g typescript )要安装此插件,您可以运行此命令或使用您喜欢的包管理器
npm install genkitx-hnsw该插件有以下几个功能:
HNSW Indexer用于根据您提供的所有数据和信息创建向量索引。该向量索引将作为HNSW Retriever的知识参考。HNSW Retriever用于以 Gemini 模型为基础获取生成式 AI 响应,并根据您的矢量索引添加额外的知识和上下文。 这是 Genkit 插件流的用法,通过 HNSW Vector Store、Gemini Embedder 和 Gemini LLM 将数据保存到矢量存储中。
在文件夹中准备数据或文档
将插件导入到您的 Genkit 项目中
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; 打开Genkit UI并选择注册的插件HNSW Indexer
使用输入和输出所需参数执行流程
dataPath :人工智能要学习的数据和其他文档路径indexOutputPath :根据您提供的数据和文档处理的矢量存储索引的预期输出路径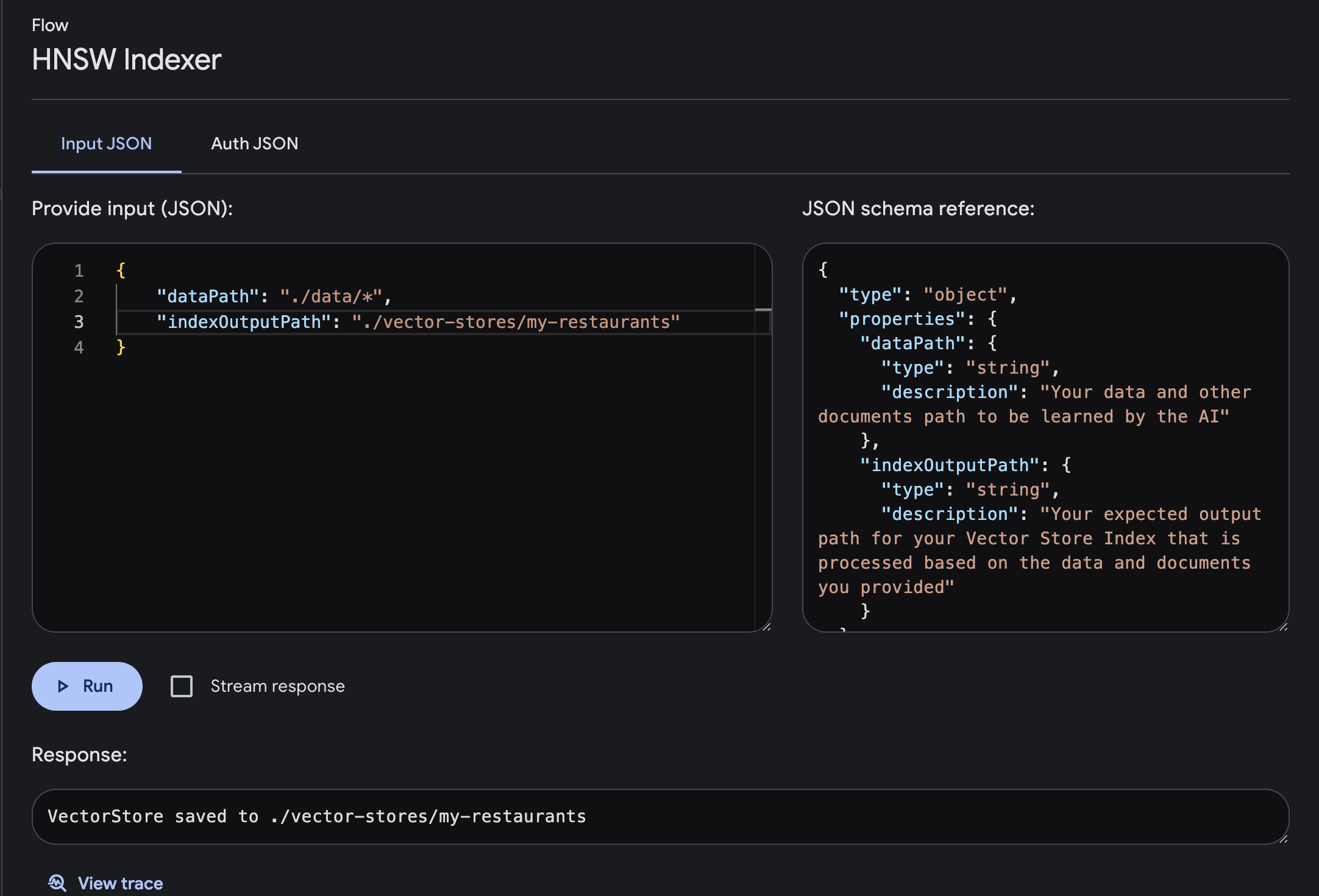
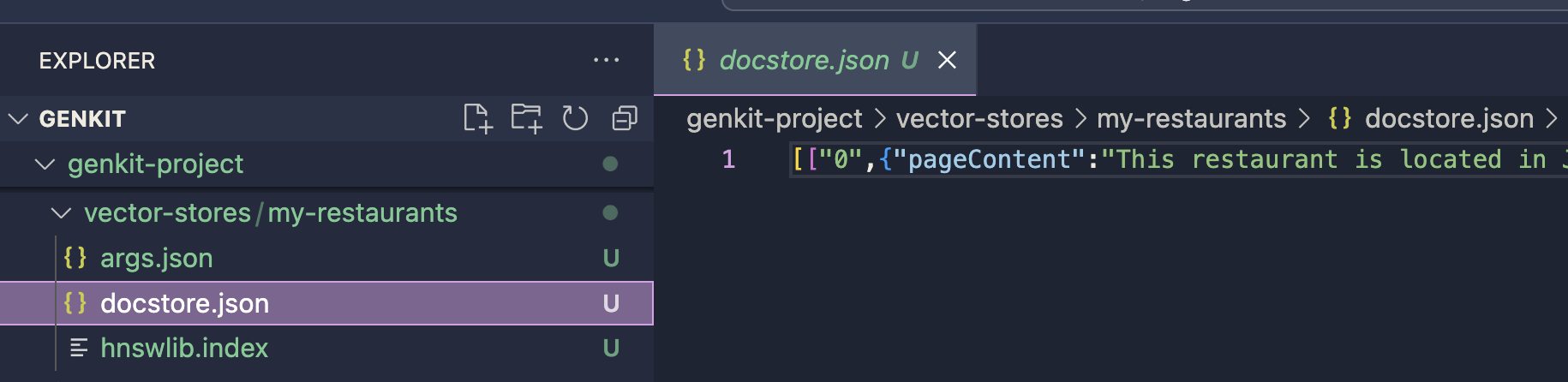 矢量存储将保存在定义的输出路径中。该索引将用于 HNSW Retriever 插件的提示生成过程。您可以使用 HNSW Retriever 插件继续实施
矢量存储将保存在定义的输出路径中。该索引将用于 HNSW Retriever 插件的提示生成过程。您可以使用 HNSW Retriever 插件继续实施
chunkSize: number一次处理多少数据。这就像将一项大任务分解成更小的部分以使其更易于管理。通过设置块大小,我们决定人工智能一次性处理多少信息,这会影响人工智能学习过程的速度和准确性。
default value : 12720
separator: string在创建向量索引期间,用于分隔输入数据中不同信息的符号或字符。它帮助人工智能了解一个数据单元的结束位置和另一个数据单元的开始位置,使其能够更有效地处理数据并从数据中学习。
default value : "n"
这是 Genkit 插件流程的用法,通过 Gemini LLM 模型处理您的提示,该模型在您提供的 HNSW 矢量数据库中丰富了附加和特定信息或知识。使用此插件,您将获得包含其他特定上下文的 LLM 响应。
将插件导入到您的 Genkit 项目中
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;确保导入Gemini LLM模型提供商的GoogleAI插件,目前该插件仅支持Gemini,很快将提供更多模型!
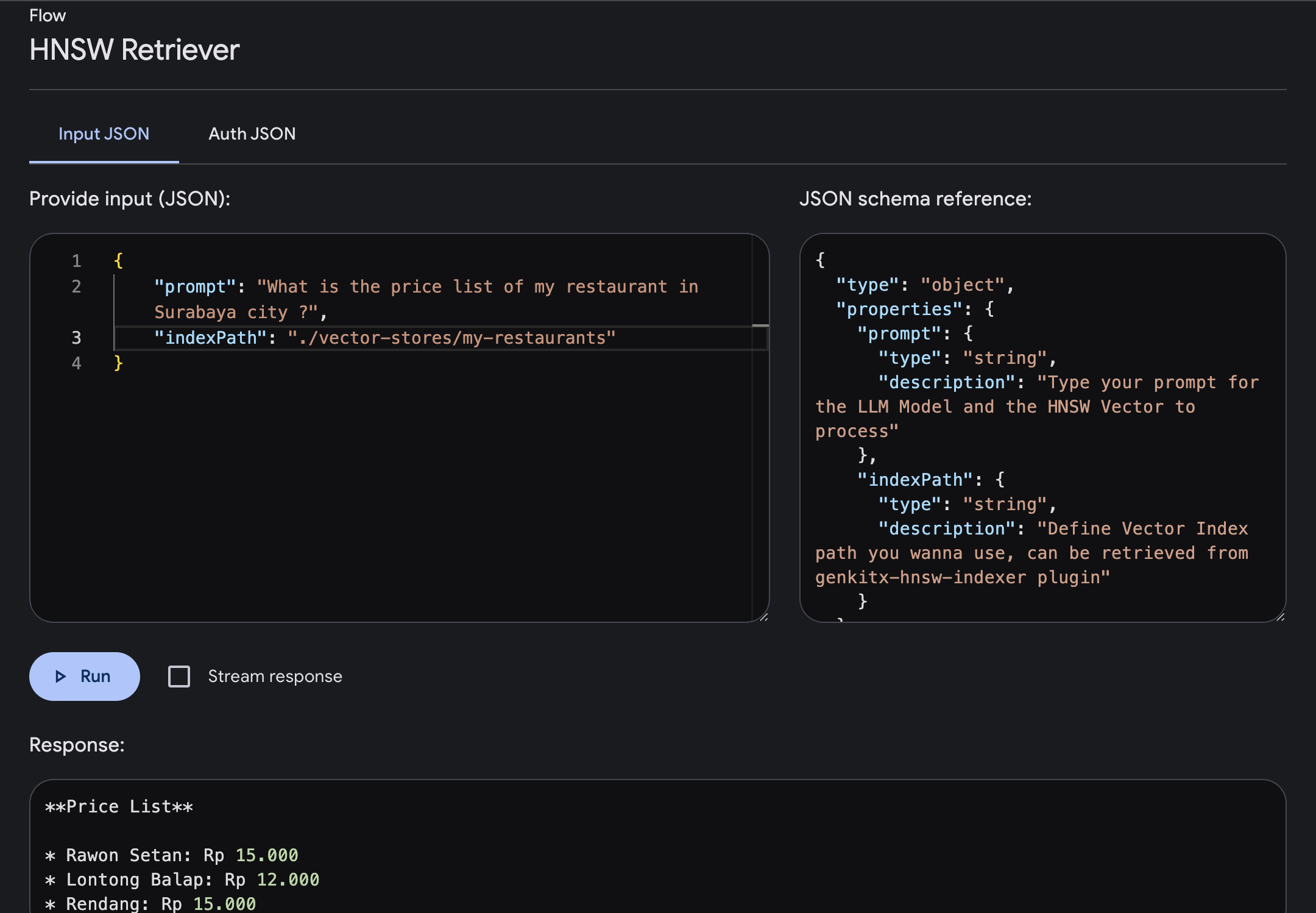
打开 Genkit UI 并选择注册的插件HNSW Retriever使用所需参数执行流程
prompt :输入提示,您将根据您提供的向量获得包含更丰富上下文的答案。indexPath :定义要用作知识参考的文件夹矢量索引路径,您可以从 HNSW Indexer 插件获取此文件路径。在此示例中,我们尝试询问泗水市一家餐厅的价目表信息,该信息已在矢量索引中提供。
我们可以输入提示并运行它,流程完成后,您将得到基于您的向量索引的包含特定知识的响应。
temperature: number温度控制生成输出的随机性。较低的温度会产生更具确定性的输出,模型会在每一步选择最有可能的标记。较高的温度会增加随机性,使模型能够探索不太可能的标记,从而可能生成更具创意但不太连贯的文本。
default value : 0.1
maxOutputTokens: number此参数指定模型在单个推理步骤中应生成的标记(单词或子词)的最大数量。它有助于控制生成文本的长度。
default value : 500
topK: number Top-K 采样将模型的选择限制为每一步中最有可能的前 K 个标记。这有助于防止模型考虑过于罕见或不太可能的标记,从而提高生成文本的连贯性。
default value : 1
topP: number Top-P采样,也称为核心采样,考虑token的累积概率分布,选择累积概率超过预定义阈值(通常表示为P)的最小token集合。这允许根据令牌的可能性动态选择每一步考虑的令牌数量。
default value : 0
stopSequences: string[]这些是标记序列,生成后会通知模型停止生成文本。这对于控制生成的输出的长度或内容非常有用,例如确保模型在到达句子或段落的末尾后停止生成。
default value : []
许可证:阿帕奇2.0


