BigBertha
skeletal-integrations

BigBertha 是一种架构设计,演示了如何使用开源容器原生技术在任何 Kubernetes 集群上实现自动化 LLMOps(大型语言模型操作)?
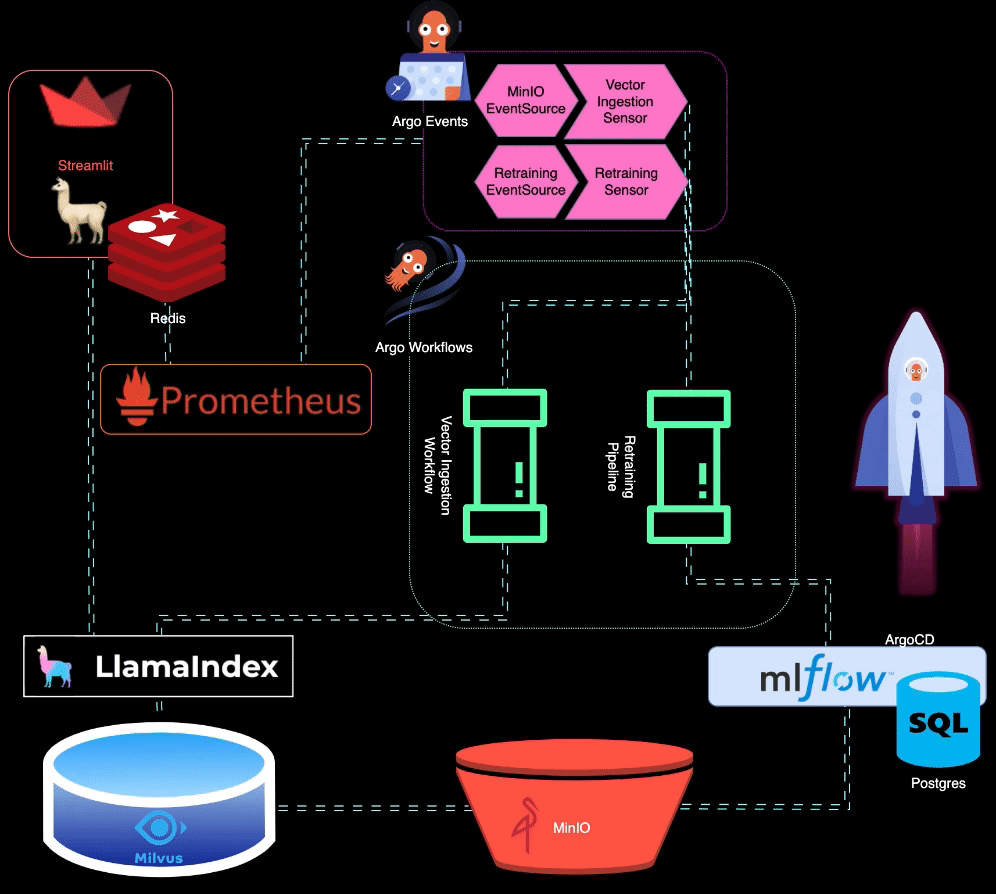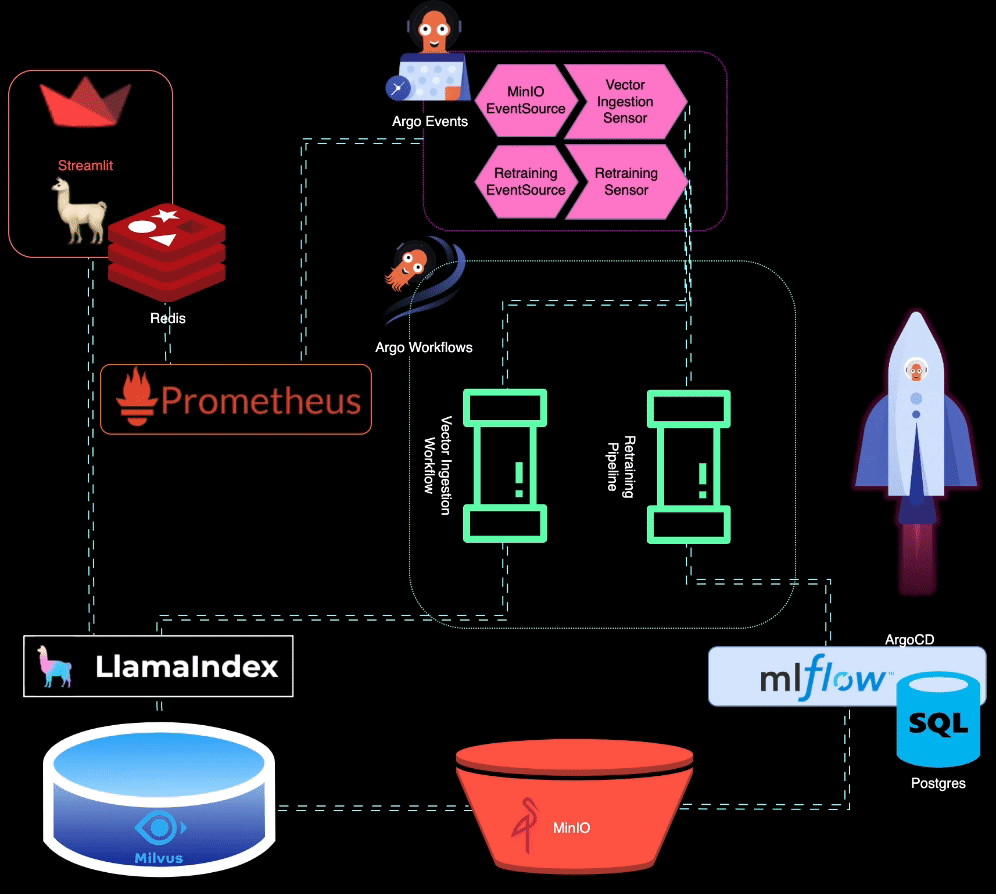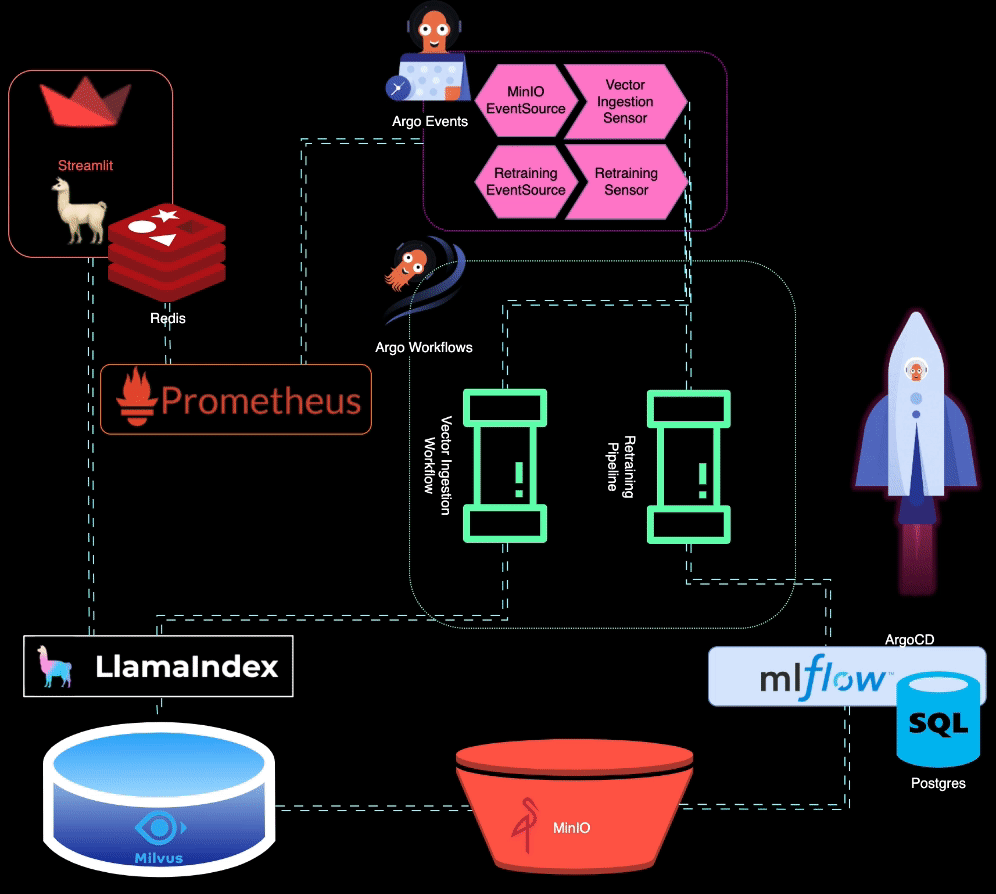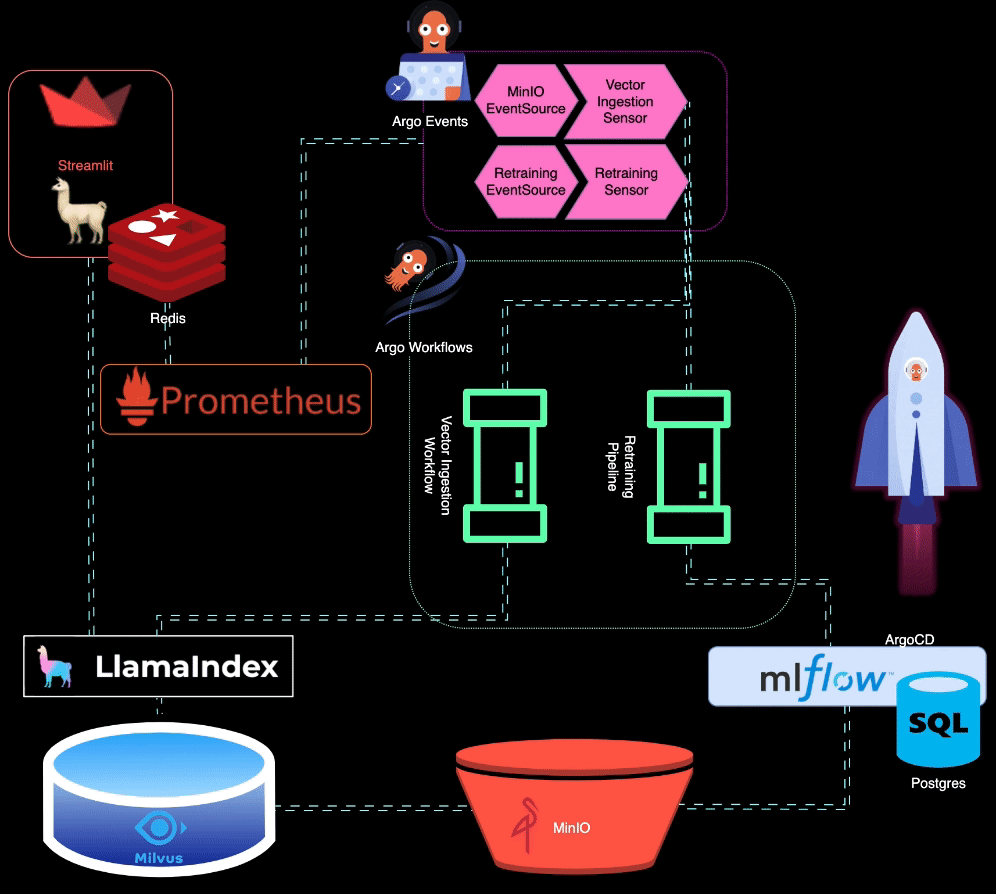
? BigBertha 利用 Prometheus 监控 LLM(大型语言模型)服务模块。出于演示目的,Streamlit 应用程序用于为 LLM 提供服务,Prometheus 从中获取指标。设置警报是为了检测性能下降。
当模型性能下降时,Prometheus 会触发警报。这些警报由 AlertManager 管理,AlertManager 使用 Argo Events 触发重新训练管道来微调模型。
?️ 再训练管道是使用 Argo 工作流程进行编排的。该管道可以定制以执行 LLM 特定的再培训、微调和指标跟踪。 MLflow 用于记录重新训练的 LLM。
MinIO 用于非结构化数据存储。 Argo Events 设置为侦听 MinIO 上的上传事件,在上传新数据时触发矢量摄取工作流程。
? Argo Workflows 用于运行向量摄取管道,该管道利用 LlamaIndex 来生成和摄取向量。这些向量存储在 Milvus 中,作为检索增强生成的知识库。
BigBertha 依赖于几个关键组件:
ArgoCD:一种 Kubernetes 原生持续交付工具,用于管理 BigBertha 堆栈中的所有组件。
Argo Workflows:一个 Kubernetes 原生工作流引擎,用于运行矢量摄取和模型再训练管道。
Argo Events:一个 Kubernetes 原生的基于事件的依赖管理器,它连接各种应用程序和组件,根据事件触发工作流程。
Prometheus + AlertManager:用于模型性能相关的监控和警报。
LlamaIndex:连接 LLM 和数据源的框架,用于数据摄取和索引。
Milvus: Kubernetes 原生向量数据库,用于存储和查询向量。
MinIO:一种用于存储非结构化数据的开源对象存储系统。
MLflow:一个用于管理机器学习生命周期的开源平台,包括实验跟踪和模型管理。
Kubernetes:容器编排平台,可自动部署、扩展和管理容器化应用程序。
Docker 容器: Docker 容器用于以一致且可重复的方式打包和运行应用程序。
作为演示,BigBertha 包括一个基于 Streamlit 的聊天机器人,该机器人为 Llama2 7B 量化聊天机器人模型提供服务。一个简单的 Flask 应用程序用于公开指标,Redis 充当 Streamlit 和 Flask 进程之间的中介。
该项目是开源的,并受此存储库中包含的许可证文件中概述的条款和条件的约束。


