jira ticket classification
1.0.0
Jira Ticket Classification 是一个自动化系统,旨在使用 Amazon Bedrock 的 AI 功能对 Jira 票据进行分类。该项目可与 Jira Server 导出一起使用,提供与 Jira Cloud 中提供的自动化功能类似的自动化功能。
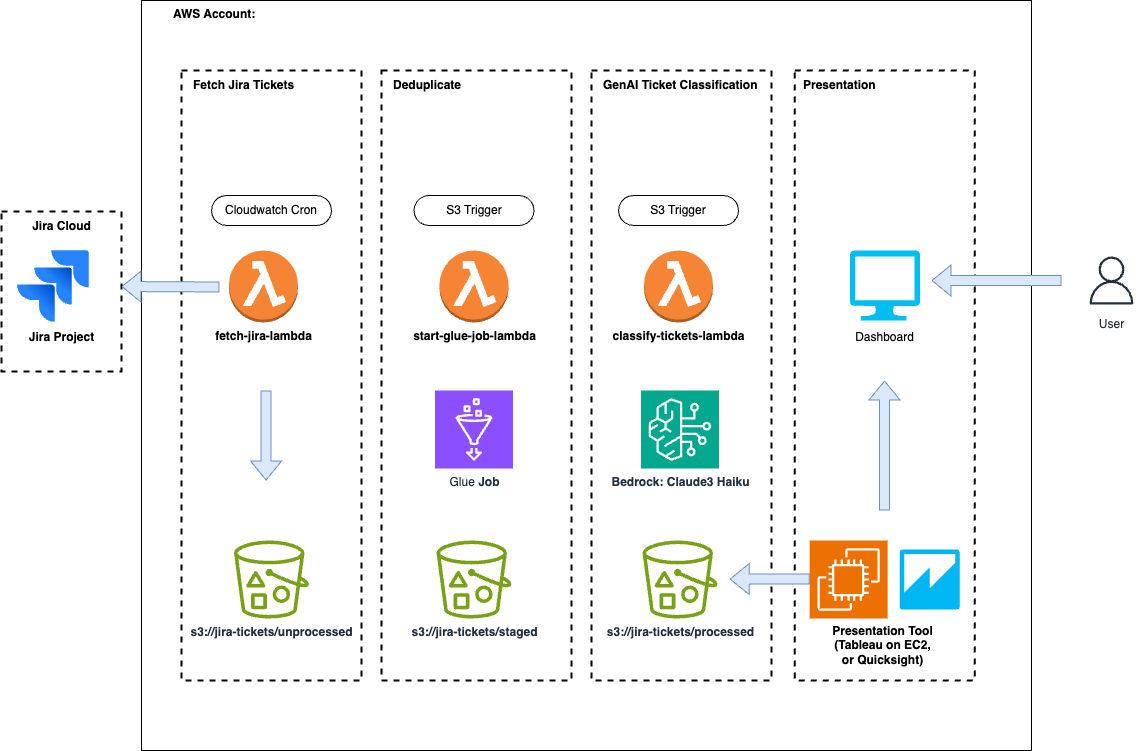
注意:如果您允许用户手动上传 Jira 导出并运行自动拉取,则重复数据删除非常重要。如果您可以确保增量导入不包含重复项,则可以删除 AWS Glue 作业。
数据输入:JIRA 票证导出放置在已部署的 S3 存储桶的/unprocessed文件夹中。
数据处理:系统处理导出的票据。
Bedrock 分类:票证数据发送到 Amazon Bedrock,后者使用预定义的分类提示对每张票证进行分类。
重复数据删除:AWS Glue 确保不处理重复的分类,从而保持数据完整性。
结果:分类结果被存储,可用于更新原始 Jira 票证或用于进一步分析。
重要通知:该项目使用 Terraform 在您的 AWS 环境中部署资源。您将因使用的 AWS 资源而产生费用。请注意您的 AWS 区域中 Lambda、Bedrock、Glue 和 S3 等服务的定价。
所需权限:您需要提升权限,特别是高级用户权限,才能部署 Terraform 堆栈。
设置项目:
infrastructure文件夹。terraform init以初始化 Terraform 工作目录。terraform apply以在您的 AWS 环境中创建资源。拆除该项目:
infrastructure文件夹。terraform destroy以删除该项目创建的所有资源。 每当对代码进行其他更改时,请确保在基础结构文件夹上运行 tfsec。
运行 TFSec
$ tfsec .禁止的警告每次对代码进行其他更改时,请确保在基础结构文件夹上运行 tfsec。这些安全警告已被抑制,但在将该解决方案投入生产之前请先检查这些警告。此外,此示例存储库使用 AWS 托管密钥。鼓励在生产环境中使用客户管理密钥 (CMK)。
/unprocessed文件夹中。欢迎为改进该项目做出贡献。请随时提交拉取请求或开放问题来讨论潜在的增强功能。
该项目已获得 MIT 许可证的许可。有关详细信息,请参阅许可证文件。
如需支持或报告问题,请在项目的 GitHub 存储库中打开问题。


