genai knowledge capture
1.0.0
该概念验证解决方案解释了一种潜在的解决方案,可用于通过公司高级员工的录音捕获部落知识。它概述了使用 Amazon Transcribe 和 Amazon Bedrock 服务对输入数据进行系统记录和验证的方法。通过提供一种使这种非正式知识正式化的结构,该解决方案保证了其对组织中后续员工群体的长期使用和适用性。这一努力不仅确保了卓越运营的持续维持,而且通过结合通过直接经验获得的实践知识,提高了培训计划的有效性。
该演示应用程序是使用 Amazon Transcribe 和 Amazon Bedrock 的文档生成应用程序的概念验证。
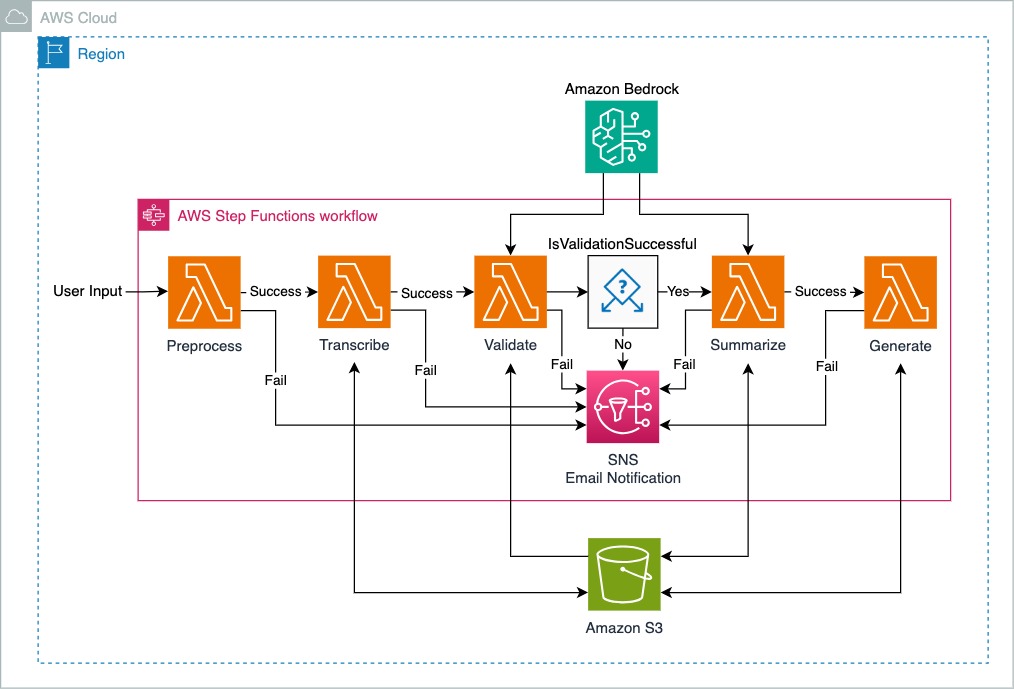
该图描绘了 AWS 云区域内由 AWS Step Functions 编排的工作流程的解决方案架构。该工作流由多个旨在处理用户输入的步骤组成,并在每个步骤中提供成功和失败处理机制。下面是工艺流程的描述:
用户输入:工作流程通过用户输入启动,以触发preprocess Lambda 函数。
预处理:首先对输入进行预处理。如果成功,则进入transcribe步骤;如果失败,则会触发 Amazon SNS 发送通知。
转录:此步骤采用上一步的输出。成功的转录将进入验证步骤,并且转录输出存储在 Amazon S3 存储桶中。
验证:验证转录的数据。根据验证结果,工作流程有所不同:
Summarize :验证后,如果数据成功汇总,汇总文本将存储在 Amazon S3 存储桶中。如果失败,则会触发 Amazon SNS 发送通知。
Amazon Bedrock是支持 Validate 和 Summarize Lambda 函数的核心服务。
生成:最后一步根据摘要文本生成最终文档。如果失败,它会触发 Amazon SNS 发送通知。
流程中的每个步骤都标记有“成功”或“失败”路径,指示工作流处理各个阶段错误的能力。发生故障时,Amazon SNS 用于向用户发送通知。
AWS Step Functions 工作流程作为中央协调器运行,确保每个任务都按正确的顺序执行,并适当处理每个步骤的成功或失败。
cdk.json文件告诉 CDK Toolkit 如何执行您的应用程序。
该项目的设置类似于标准 Python 项目。初始化过程还会在此项目中创建一个 virtualenv,存储在.venv目录下。要创建 virtualenv,它假设您的路径中有一个可以访问venv包的python3 (或 Windows 的python )可执行文件。如果由于任何原因自动创建 virtualenv 失败,您可以手动创建 virtualenv。
要在 MacOS 和 Linux 上手动创建 virtualenv:
$ python3 -m venv .venv初始化过程完成并创建 virtualenv 后,您可以使用以下步骤激活 virtualenv。
$ source .venv/bin/activate如果你是Windows平台,你可以像这样激活virtualenv:
% .venvScripts activate.bat激活 virtualenv 后,您可以安装所需的依赖项。
$ pip install -r requirements.txt要添加其他依赖项(例如其他 CDK 库),只需将它们添加到setup.py文件并重新运行pip install -r requirements.txt命令。
此时,您现在可以为此代码合成 CloudFormation 模板。
$ cdk synth要添加其他依赖项(例如其他 CDK 库),只需将它们添加到setup.py文件并重新运行pip install -r requirements.txt命令。
如果这是您第一次在特定帐户和区域运行 cdk,您将需要引导它。
$ cdk bootstrap
一旦引导完成,您就可以继续部署 cdk。
$ cdk deploy
如果这是您第一次部署它,则在 ECS(Amazon Elastic Container Service)中构建多个 Docker 映像的过程可能需要大约 30-45 分钟。请耐心等待直至完成。之后,它将开始部署 docgen-stack,通常需要大约 5-8 分钟。
部署过程完成后,您将在终端中看到 cdk 的输出,您还可以在 CloudFormation 控制台中验证状态。
如果您想在使用完 cdk 后将其删除,以避免日后产生费用,您可以通过控制台删除它,也可以在终端中执行以下命令。
$ cdk destroy您可能还需要手动删除 cdk 生成的 S3 存储桶。请确保删除所有生成的资源,以避免产生费用。
cdk ls列出应用程序中的所有堆栈cdk synth发出合成的 CloudFormation 模板cdk deploy将此堆栈部署到您的默认AWS帐户/区域cdk diff将部署的堆栈与当前状态进行比较cdk docs打开 CDK 文档cdk destroy dstroys 一个或多个指定的堆栈 code # Root folder for code for this solution
├── lambdas # Root folder for all lambda functions
│ ├── preprocess # Lambda function that processes user input, and outputs audio files uris for Amazon Transcribe
│ ├── transcribe # Lambda function that triggers Amazon Transcribe batch transcription
│ ├── validate # Lambda function that analyzes answers from Amazon Transcribe using LLMs from Amazon Bedrock
│ ├── summarize # Lambda function that summarizes on-topic texts from Amazon Transcribe using LLMs from Amazon Bedrock
│ └── generate # Lambda function that generates documents from the summary.
└── code_stack.py # Amazon CDK stack that deploys all AWS resources
要定制 DocGen 应用程序以合并您自己的数据,应遵循以下步骤:
部署后,AWS CDK 基础设施将有助于将音频文件自动传输到指定的 Amazon S3 存储桶。随后,可以启动 AWS Step Function 的执行以开始处理阶段。
部署解决方案后,您可以将电子邮件订阅到 SNS 主题以接收通知。
请关注SNS邮件通知。
如果 StepFunction 工作流程中的任何步骤失败,您将收到电子邮件通知。
部署后,您可以使用以下命令触发已部署的 AWS 状态机:
aws stepfunctions start-execution
--state-machine-arn "arn:aws:states:<your aws region>:<your account id>:stateMachine:genai-knowledge-capture-stack-state-machine"
--input "{"documentName": "<your document name>", "audioFileFolderUri": "s3://<your s3 bucket>/assets/audio_samples/what is amazon bedrock/"}"
请参阅贡献以获取更多信息。
该库根据 MIT-0 许可证获得许可。请参阅许可证文件。


