genai with confluent
1.0.0
这是使用 Confluence Cloud 的实时生成式 AI 演示。这个想法受到 Eden Marco(LangChain- 使用 LangChain 开发 LLM 支持的应用程序)领导的 Udemy 培训的影响。 Eden Marco 给了我升级链接。 Eden Marco 对 Python 中的 Lngchain LLM 开发做了很好的介绍。我采用了破冰的想法,并将其转移到使用 Confluence 和 AI 运行 Data in Motion 的真实用例中。
该存储库将部署:
请将此存储库克隆到您的桌面上:
cd $HOME # or what-ever directory you want to use
git clone https://github.com/ora0600/genai-with-confluent.git
cd genai-with-confluent/terraform/演示执行是完全自动化的,但在执行之前,您需要在此处设置一些内容:
创建 Salesforce 开发人员帐户 在此处注册 配置 Salesforce CDC,请参阅此处使用屏幕截图关注我的设置 高级步骤:
您需要 Salesforce CDC Connector 的所有参数,因此请安全存储它们。
您需要一个 Confluence Cloud 的工作帐户。注册 Confluence Cloud 非常简单,首次试用时您将获得 400 美元的免费预算。如果您没有可用的 Confluence Cloud 帐户,请注册 Confluence Cloud。
pip3 install confluent_kafka
pip3 install requests
pip3 install fastavro
pip3 install avro
pip3 install jproperties
pip3 install langchain
pip3 install openai
pip3 install langchain_openai
pip3 install -U langchain-community
pip3 install google-search-results
pip3 install Flask
pip3 install langchain_core
pip3 install pydantic对于 Confluence Cloud:通过 CLI 在 Confluence Cloud 中创建 API 密钥:
confluent login
confluent api-key create --resource cloud --description " API for terraform "
# It may take a couple of minutes for the API key to be ready.
# Save the API key and secret. The secret is not retrievable later.
# +------------+------------------------------------------------------------------+
# | API Key | <your generated key> |
# | API Secret | <your generated secret> |
# +------------+------------------------------------------------------------------+通过使用您的数据执行以下命令,将 Confluence Cloud 的所有参数复制到terraform.tfvars文件中:
cat > $PWD /terraform/terraform.tfvars << EOF
confluent_cloud_api_key = "{Cloud API Key}"
confluent_cloud_api_secret = "{Cloud API Key Secret}"
sf_user= "salesforce user"
sf_password = "password"
sf_cdc_name = "LeadChangeEvent"
sf_password_token = "password token"
sf_consumer_key = "consumer key of connected app"
sf_consumer_secret = "consumer secret of connect app"
EOFTerraform 将获取所有这些参数并为您进行配置,并最终部署所有融合的云资源,包括服务帐户和角色绑定。
我们使用langchain LLM版本0.1 Langchain Docu
暗示:
| 现在,这需要花钱。不幸的是,API 不是免费的。我花费 10 美元用于开放 AI,10 美元用于 ProxyCurl API,SERP API 仍处于免费状态。 |
首先我们需要一个允许我们使用 OpenAI 的密钥。按照此处的步骤创建帐户,然后仅创建 API 密钥。
下一个任务:创建 proxycurl api 密钥。 ProxyCurl 将用于抓取 Linkedin。注册 proxyurl 并以 10 美元购买积分(或任何您认为足够的东西,也许您开始更多更少),请按照以下步骤操作
为了能够在 Google 中搜索正确的 linkedin 配置文件 URL,我们需要此处的 SERP API 的 API 密钥。
现在,通过执行以下命令将所有密钥放入env-vars文件中:
cat > $PWD /terraform/env.vars << EOF
export PYTHONPATH=/YOURPATH
export OPENAI_API_KEY=YOUR openAI Key
export PROXYCURL_API_KEY=YOUR ProxyURL Key
export SERPAPI_API_KEY=Your SRP API KEy
EOF恭喜你准备工作已经完成。我知道,这是一个巨大的设置。
现在是简单的部分。只需执行 terraform 即可。执行 terraform,所有 Confluence 云资源将自动部署:
cd terraform
terraform init
terraform plan
terraform apply这需要一段时间。将提供 Confluence 云资源。如果这样做,iterm2 终端将自动打开并执行三个服务。
好的,现在您需要将新的潜在客户添加到 Salesforce 中。这是最后一个手动步骤。
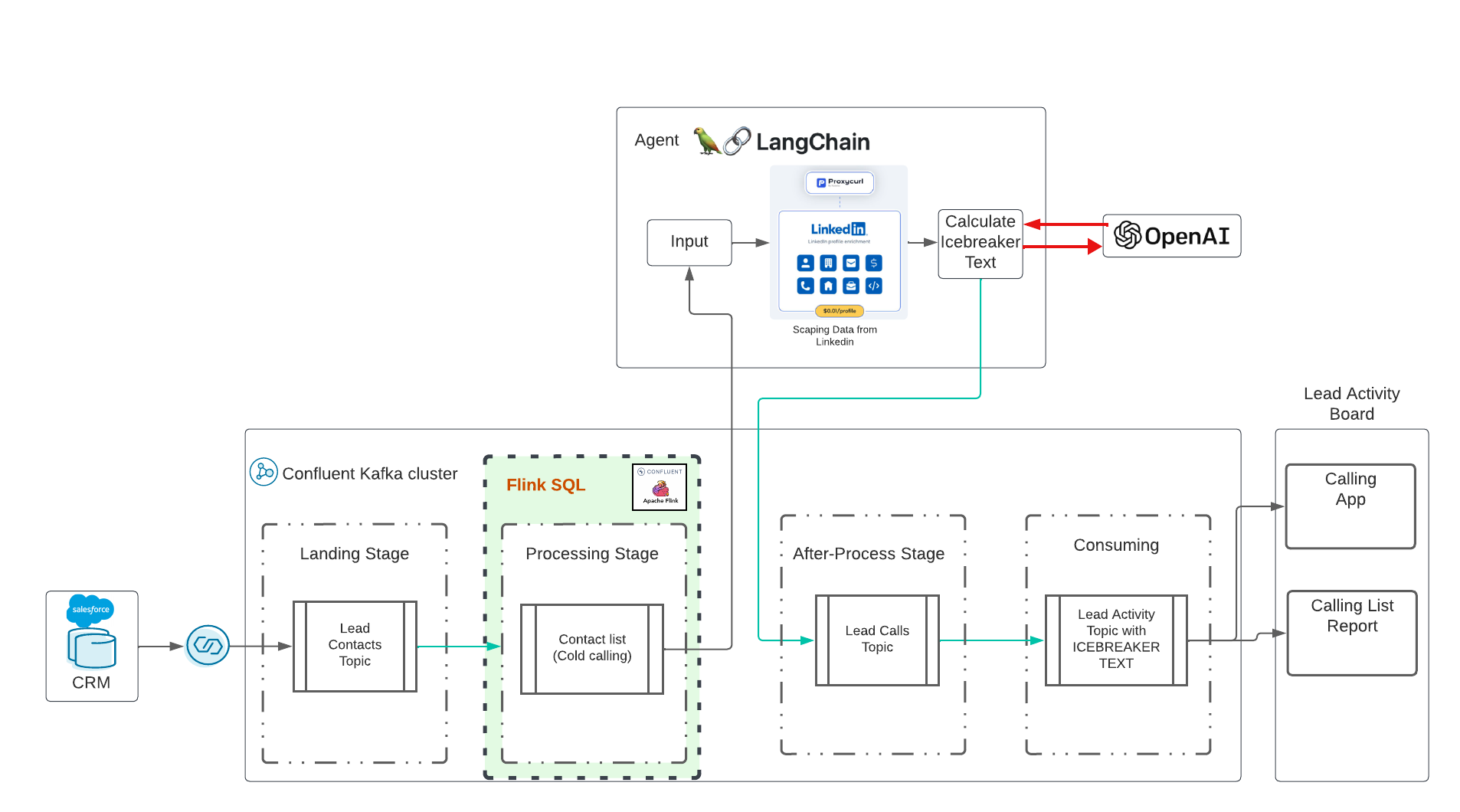
生成式人工智能将从 Kafka 集群中获取新的领导者,并通过从 Linkedin 获取信息并自动实时执行提示来执行 LLM 操作。 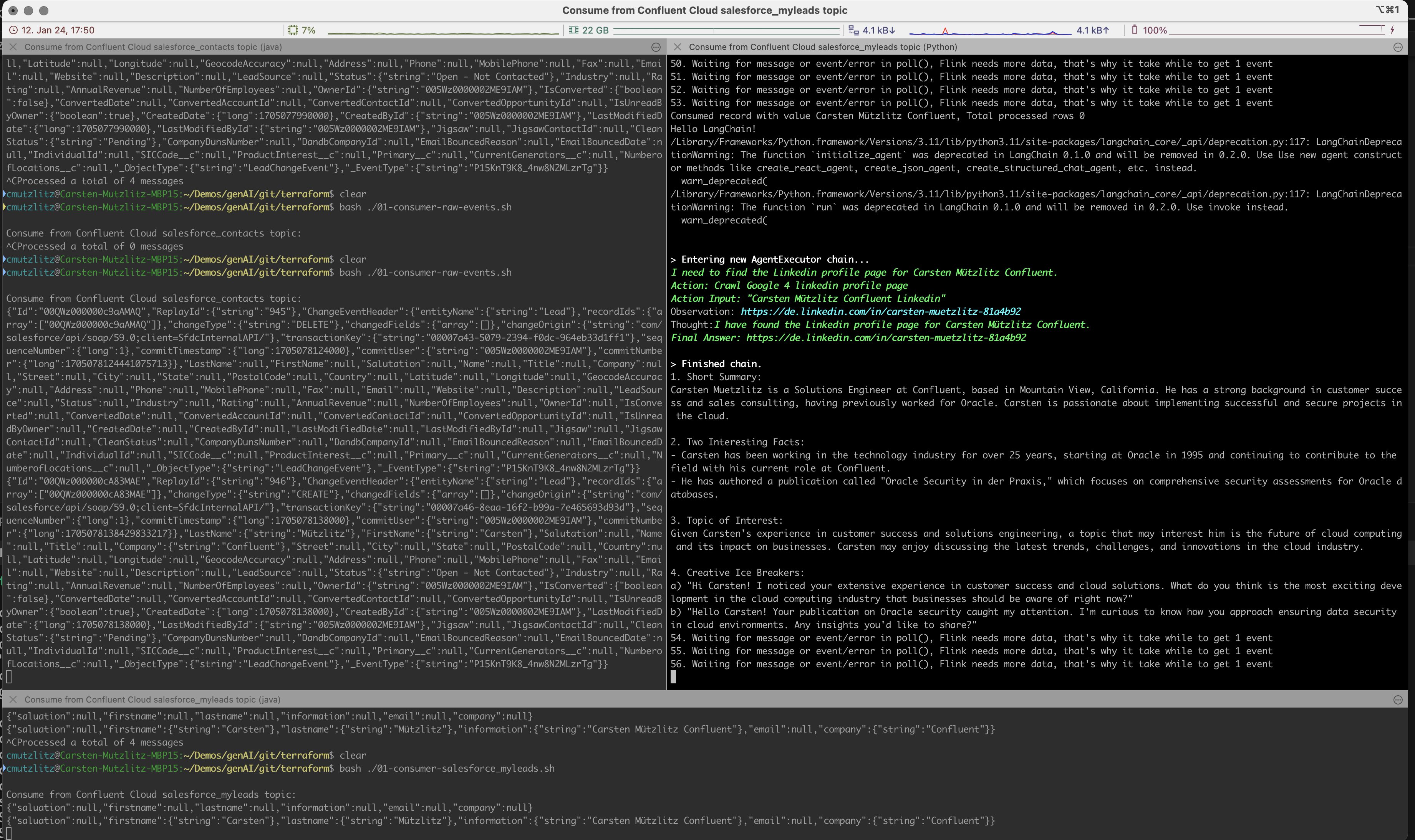
该提示将被视为Chatgpt的任务,我们制定了C>hatgpt应制定以下内容:
我们在此演示中运行chatgpt-3.5-turbo模型。该模型的代币有限,但是目前最快、最古老的模型。当然还有最便宜的。如果您尝试使用 Kai Waehner 作为 Lead,那么您会发现当前模型的代币不够。你能做的就是改变模型。这是最简单的方法,另一种方法是将内容分割成块。请查看当前型号以检查每个型号的代币数量。
我从我的测试开始:
model_name="gpt-4-turbo"并重新启动客户端。在我看来,这个简单的演示并不是检索增强生成 (RAG) 模式的用例。我们从给定的 API 获取所有信息,将数据存储到向量数据库中是没有意义的。通过API实时加载信息比新鲜数据要高效得多。为您的用例使用正确的模型,在我们的例子中,它应该是具有更高数量代币的快速模型。
Salesforce 已重置您的密码,您需要不时更改它。如果您更改密码,您还会获得新的密码安全令牌。请不要忘记在terraform.tfvars文件中更改此设置。
如果完成,您可以使用 CTRL+c 停止终端中的程序并销毁 Confluence Cloud 中的所有内容:
terraform destroy如果出现错误,再次执行destroy,直到所有内容都被删除,那么您就可以确定没有资源在运行并消耗成本。
terraform destroy您需要一个 Confluence 云帐户(新帐户免费获得 400 美元积分)。您需要一个具有当前信用额度的 OPenAI 帐户。您需要一个具有当前积分的 ProxyCurl API 帐户。您需要 SERP API 帐户,在这里您将获得起始连接数。这对我来说就足够了。
我总共花费了 20 美元(Open AI、ProxyCurl),但我仍然没有用完积分。


