ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
YouTube 简介 • Discord 聊天 • 完整文档
安装 UStore 非常简单,使用起来就像 Python dict一样简单。
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi'我们刚刚创建了一个内存嵌入式事务数据库,并在其main集合中添加了一个条目。您更喜欢磁盘上的数据吗?换一行。
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )您想要连接到远程 UStore 服务器吗? UStore 附带 Apache Arrow Flight RPC 接口!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' )您是否存储类似 NetworkX 的MultiDiGraph ?或者类似 Pandas 的DataFrame ?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1函数调用可能看起来相同,但底层实现可以寻址远程计算机上持久内存中某处的数百 TB 数据。
是否有其他人同时更新这些集合?捆绑您的操作以保证一致性!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )到目前为止,我们只介绍了 UStore 的一小部分。您可以用它来...
但UStore 还可以。这是地图:
## 基本用法
UStore 的目的不仅仅是作为数据库,而是作为“构建数据库”工具包和 NoSQL 潜在事务数据库的开放标准,为“创建、读取、更新、删除”操作(简称 CRUD)定义零拷贝二进制接口。
一些简单的 C99 标头可以将几乎任何底层存储引擎链接到众多高级语言驱动程序,将对二进制字符串值的支持扩展到图形、灵活模式文档和其他模式,旨在取代 MongoDB、Neo4J、Pinecone 和 ElasticSearch使用单个 ACID 事务系统。
例如,Redis 提供了具有类似目标的 RediSearch、RedisJSON 和 RedisGraph。 UStore 做得更好,允许您添加您最喜欢的键值存储 (KVS),嵌入式、独立或分片,例如 FoundationDB,从而增强其功能。
二进制大对象可以放置在 UStore 中。根据所使用的底层技术,性能会有很大差异。内存中的 UCSet 速度最快,但最不适合较大的对象。持久化 UDisk 在正确配置后,可以完全绕过 Linux 内核,包括文件系统层,直接寻址块设备。
当基于 SPDK 等用户空间驱动程序构建时,高端服务器上的现代持久 IO 每个套接字可以超过 100 GB/s。这接近高端 RAM 的实际吞吐量,并解锁了数据库用例中不常见的新功能。现在,人们可以将千兆字节大小的视频文件放在 ACID 事务数据库中,紧邻其元数据,而不是使用像 MinIO 这样的单独的对象存储。
JSON 是当今最常用的文档格式。 UStore 文档集合支持 JSON,以及 MongoDB 使用的 MessagePack 和 BSON。

UStore 还不能水平扩展,但可以提供更高的单节点性能,并且借助开源的simdjson和yyjson库,在多核系统上具有几乎线性的垂直可扩展性。此外,要与数据交互,您不需要像 MQL 这样的自定义查询语言。相反,我们优先考虑开放 RFC 标准,以真正避免供应商锁定:
现代图形数据库(例如 Neo4J)难以应对巨大的工作负载。它们需要太多的 RAM,而且它们的算法一次只能观察一个条目的数据。我们在两个方面进行优化:
特征存储和矢量数据库(例如 Pinecone、Milvus 和 USearch)为矢量搜索提供独立索引。 UStore 将其实现为一种单独的模式,与文档和图表相同。特征:
用于 Python 的 UStore 和用于 C++ 的 UStore 看起来非常不同。我们的 Python SDK 模仿其他 Python 库 - Pandas 和 NetworkX。同样,C++ 库提供了 C++ 开发人员期望的接口。
众所周知,人们出于不同的目的使用不同的语言。某些语言未实现某些 C 级功能。要么是因为没有需求,要么是因为我们还没有做到这一点。
| 姓名 | 办理 | 收藏 | 批次 | 文档 | 图表 | 副本 |
|---|---|---|---|---|---|---|
| C99标准 | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| C++ SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| Python SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| Go语言SDK | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| Java SDK | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| 箭飞行 API | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
这里的一些前端周围有整个生态系统!例如,Apache Arrow Flight API 拥有自己的 C、C++、C#、Go、Java、JavaScript、Julia、MATLAB、Python、R、Ruby 和 Rust 驱动程序。
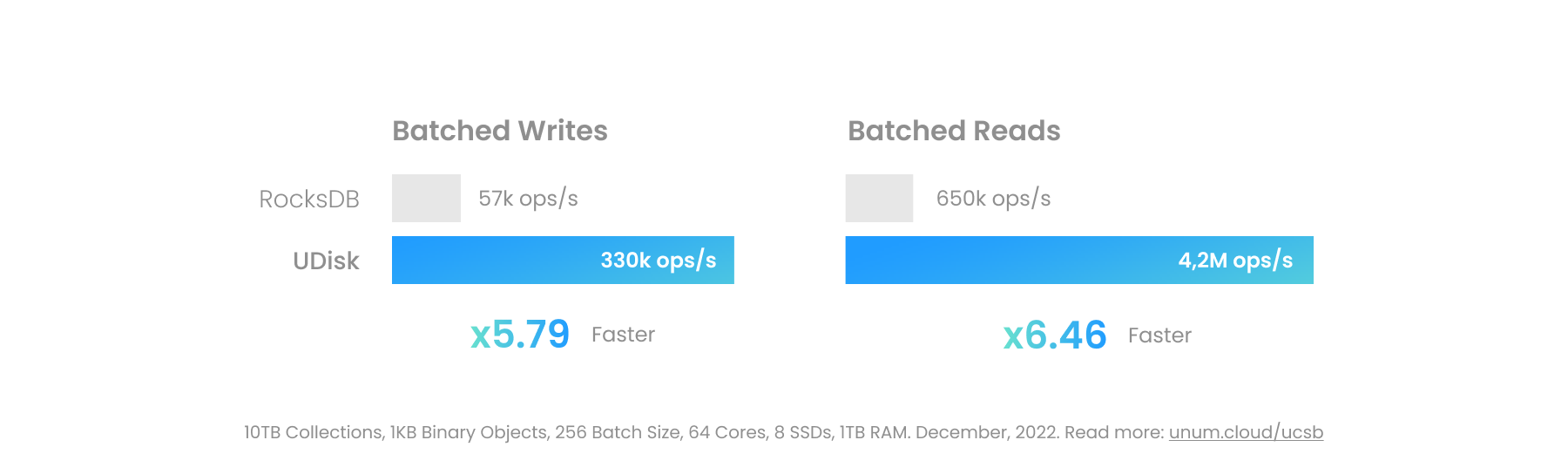
以下引擎几乎可以互换使用。从历史上看,LevelDB 是第一个。 RocksDB 随后改进了功能和性能。现在它成为一半 DBMS 初创公司的基础。
| 水平数据库 | Rocks数据库 | U盘 | UC集 | |
|---|---|---|---|---|
| 速度 | 1x | 2x | 10倍 | 30倍 |
| 执着的 | ✓ | ✓ | ✓ | ✗ |
| 交易性 | ✗ | ✓ | ✓ | ✓ |
| 块设备支持 | ✗ | ✗ | ✓ | ✗ |
| 加密 | ✗ | ✗ | ✓ | ✗ |
| 手表 | ✗ | ✓ | ✓ | ✓ |
| 快照 | ✓ | ✓ | ✓ | ✗ |
| 随机抽样 | ✗ | ✗ | ✓ | ✓ |
| 批量枚举 | ✗ | ✗ | ✓ | ✓ |
| 命名集合 | ✗ | ✓ | ✓ | ✓ |
| 开源 | ✓ | ✓ | ✗ | ✓ |
| 兼容性 | 任何 | 任何 | Linux | 任何 |
| 维护者 | 谷歌 | 乌努姆 | 乌努姆 |
UCSet 和 UDisk 均由 Unum 设计和维护。两者的功能都很齐全,但我们的替代方案提供的最关键的功能是性能。记忆力快很容易。 UCSet 的核心逻辑可以在模板化的仅标头ucset库中找到。
设计 UDisk 是一项更具挑战性的工作,历时 7 年。它包括发明新的树状结构、使用io_uring实现部分内核旁路、使用SPDK实现完全旁路、CUDA GPU 加速,甚至自定义内部文件系统。 UDisk 是第一个从头开始设计并考虑并行架构和内核旁路的引擎。
原子性始终得到保证。即使在非事务性写入上 - 要么所有更新都通过,要么全部失败。
一致性以尽可能严格的形式实现 - “严格可串行化”意味着:
但是,可以在特定操作级别调整默认行为。为此, ::ustore_option_transaction_dont_watch_k可以传递给ustore_transaction_init()或任何事务性读/写操作,以控制暂存期间的一致性检查。
| 读 | 写 | |
|---|---|---|
| 头 | 严格系列 | 严格系列 |
| 通过快照进行交易 | 串行 | 严格系列 |
| 没有快照的交易 | 严格系列 | 严格系列 |
| 不带手表的交易 | 严格系列 | 顺序 |
如果您对这个主题不熟悉,请查看有关一致性的 Jepsen.io 博客。
| 读 | 写 | |
|---|---|---|
| 通过快照进行交易 | ✓ | ✓ |
| 没有快照的交易 | ✗ | ✓ |
根据定义,持久性不适用于内存系统。在混合或持久系统中,我们更喜欢默认禁用它。几乎每个构建在 KVS 之上的 DBMS 都喜欢实现自己的持久性机制。在分布式数据库中更是如此,其中可能存在三个单独的预写日志:
如果您仍然需要持久性,请使用可选标志刷新写入提交。在 C 驱动程序中,您可以使用::ustore_option_write_flush_k标志调用ustore_transaction_commit() 。
整个 DBMS 适合小于 100 MB 的 Docker 镜像。运行以下脚本来拉取并运行容器,在端口38709上公开 Apache Arrow Flight 服务器。默认情况下,客户端 SDK 也将通过同一端口进行通信。
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustore可以通过以下方式检索默认配置文件:
cat /var/lib/ustore/config.json连接和测试的最简单方法是使用以下命令:
python ...预打包的 UStore 镜像可在多个平台上使用:
不要犹豫,将 UStore 商业化并重新分发。
调整数据库既是一门艺术,也是一门科学。像 RocksDB 这样的项目提供了数十个旋钮来优化行为。我们允许将专门的配置文件转发到底层引擎。
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}我们还有一个更简单的程序,对于 80% 的用户来说已经足够了。可以扩展以利用多个设备或目录,或转发专门的引擎配置。
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}数据库集合也可以使用 JSON 文件进行配置。
从当前版本开始,使用 64 位有符号整数。它允许[0, 2^63)范围内的唯一键。带有 UUID 的 128 位版本即将推出,但强烈建议不要使用可变长度密钥。为什么会这样呢?
使用可变长度密钥对键值存储的设计施加了许多限制。首先,它意味着缓慢的字符比较——现代超标量 CPU 的性能杀手。其次,它强制将键和值连接到磁盘上,以最大限度地减少导航所需的元数据。最后,它违反了我们将 KVS 作为“持久内存分配器”的简单逻辑视图,给它带来了更多的责任。
处理字符串键的推荐方法是:
这将导致从字符串到整数表示的单个转换点,并使大部分系统保持敏捷,并且 C 级接口比它们原本应有的更简单。
目前我们只能处理 4 GB 或更小的值。为什么?键值存储通常用于高频操作。通常(每秒数千次),在现代硬件上访问和修改 4 GB 及更大的文件是不可能的。因此,我们坚持使用较小长度的类型,使使用 Apache Arrow 表示稍微容易一些,并允许 KVS 更好地压缩索引。
我们的开发路线图是公开的,并托管在 GitHub 存储库中。即将到来的任务包括:
请在此处阅读我们文档中的完整路线图。


