aiwhispr
version 0.941
AIWhispr 是一种无/低代码工具,用于自动化向量嵌入管道以进行语义搜索。一个简单的配置即可驱动读取文件、提取文本、创建矢量嵌入并将其存储在矢量数据库中的管道。
人工智能耳语

AIWhispr 具有用于以下矢量数据库的连接器
1Qdrant
2 米尔乌斯
3 维阿特
4 类型感应
5、MongoDB
6 Postgres - PGVector
请确保您已安装并启动矢量数据库。
AIWISPR_HOME_DIR 环境变量应该是 aiwhispr 目录的完整路径。
AIWISPR_LOG_LEVEL环境变量可以设置为DEBUG / INFO / WARNING / ERROR
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
请记住在 shell 登录脚本中添加环境变量
运行以下命令
$AIWHISPR_HOME/shell/install_python_packages.sh
如果 uwsgi 安装失败,请确保安装了 gcc、python-dev 、 python3-dev 。
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr 附带了一个 Streamlit 应用程序来帮助您入门。
运行streamlit应用程序
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
这应该会在默认端口 8501 上启动一个 Streamlit 应用程序,并在您的 Web 浏览器上启动一个会话
配置管道以对内容进行索引以进行语义搜索需要执行 3 个步骤。
1.配置从存储位置读取文件
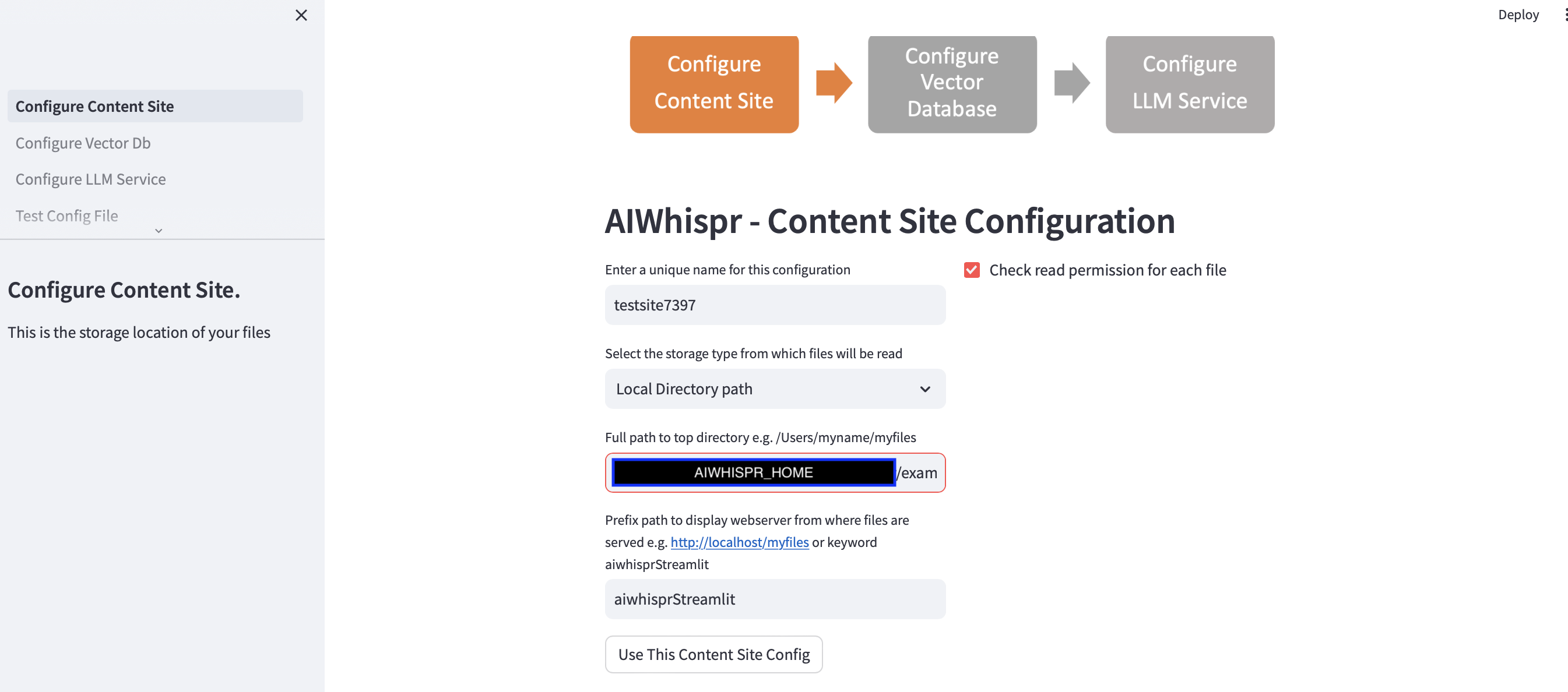
您可以通过单击“使用此内容站点配置”按钮继续默认配置
并进入下一步配置矢量数据库连接。
默认示例将为 BBC 的新闻报道编制索引以进行语义搜索。
Streamlit 应用程序假定您正在开始新配置,并将分配随机配置名称。您可以覆盖它以给它一个更有意义的名称。配置名称应该是唯一的;它不能包含空格或特殊字符。
默认配置将从本地目录路径 $AIWISPR_HOME/examples/http/bbc 读取内容
其中包含来自 BBC 的 2000 多个新闻报道,这些新闻报道已编入索引以进行语义搜索。
您可以选择读取存储在 AWS S3、Azure Blob、Google Cloud Storage 上的内容。
前缀路径配置用于为搜索结果创建 href Web 链接。您可以继续使用默认关键字“aiwhisprStreamlit”
单击“使用此内容站点配置”按钮,然后单击左侧边栏中的“配置矢量数据库”进入下一步以配置矢量数据库连接。
2.配置矢量数据库
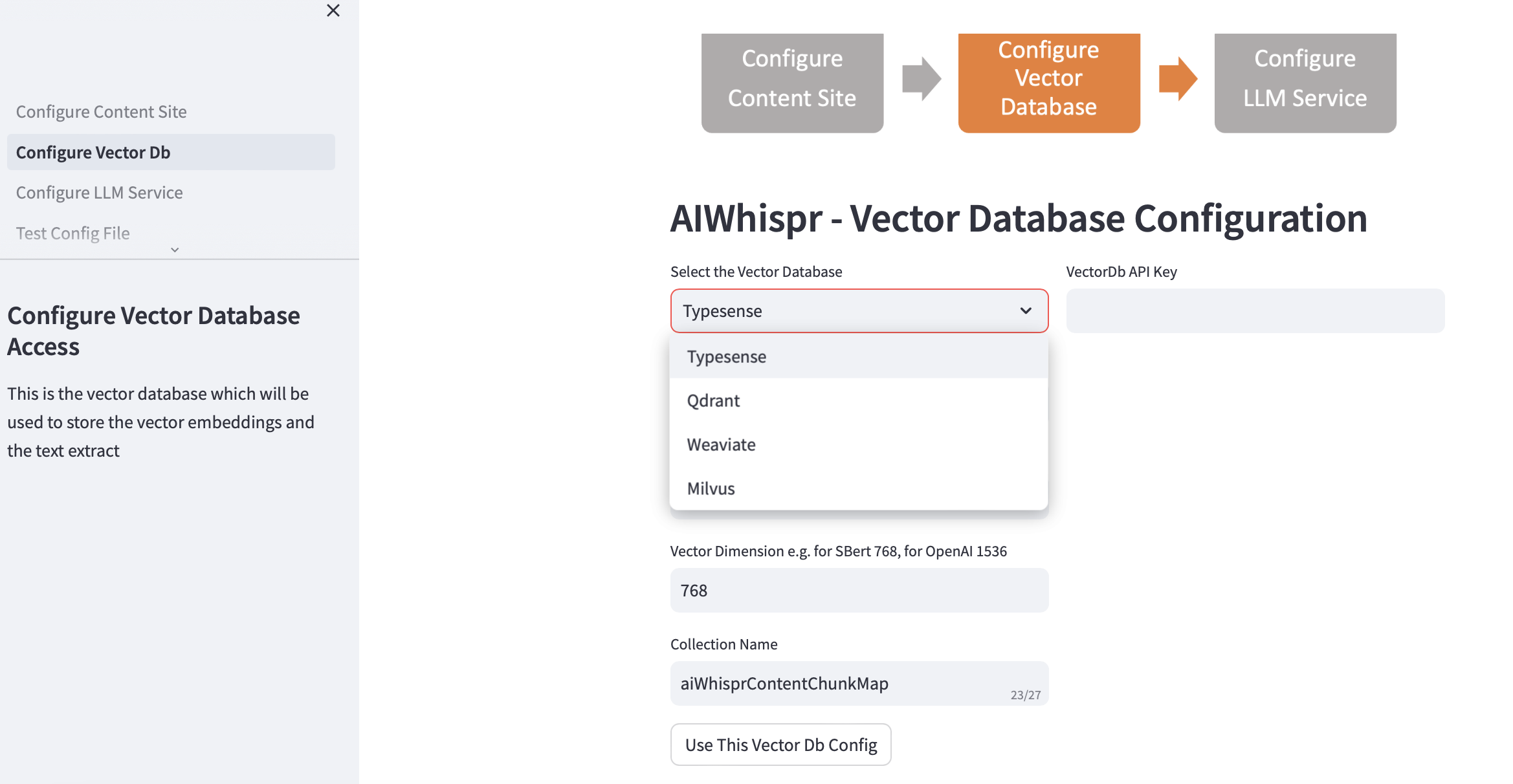
选择您的向量数据库并提供连接详细信息。
当您选择矢量数据库时,Vector Db IP 地址和端口号将根据默认安装进行填充。您可以根据您的设置更改此设置。
您的矢量数据库应该配置为进行身份验证。对于 Qdrant、Weaviate、Typesense,需要 API 密钥。对于 Milvus,应配置用户 ID 和密码组合。
应根据您计划用于将文本编码为向量嵌入的 LLM 来指定向量维度大小。示例:对于 Open AI“text-embedding-ada-002”,应配置为 1536,这是 OpenAI 嵌入服务返回的向量的大小。
矢量数据库中创建的默认集合名称是 aiwhisprContentChunkMap。您可以指定自己的集合名称。
单击“使用此矢量数据库配置”按钮,然后单击左侧边栏中的“配置 LLM 服务”进入下一步。
3.配置LLM服务
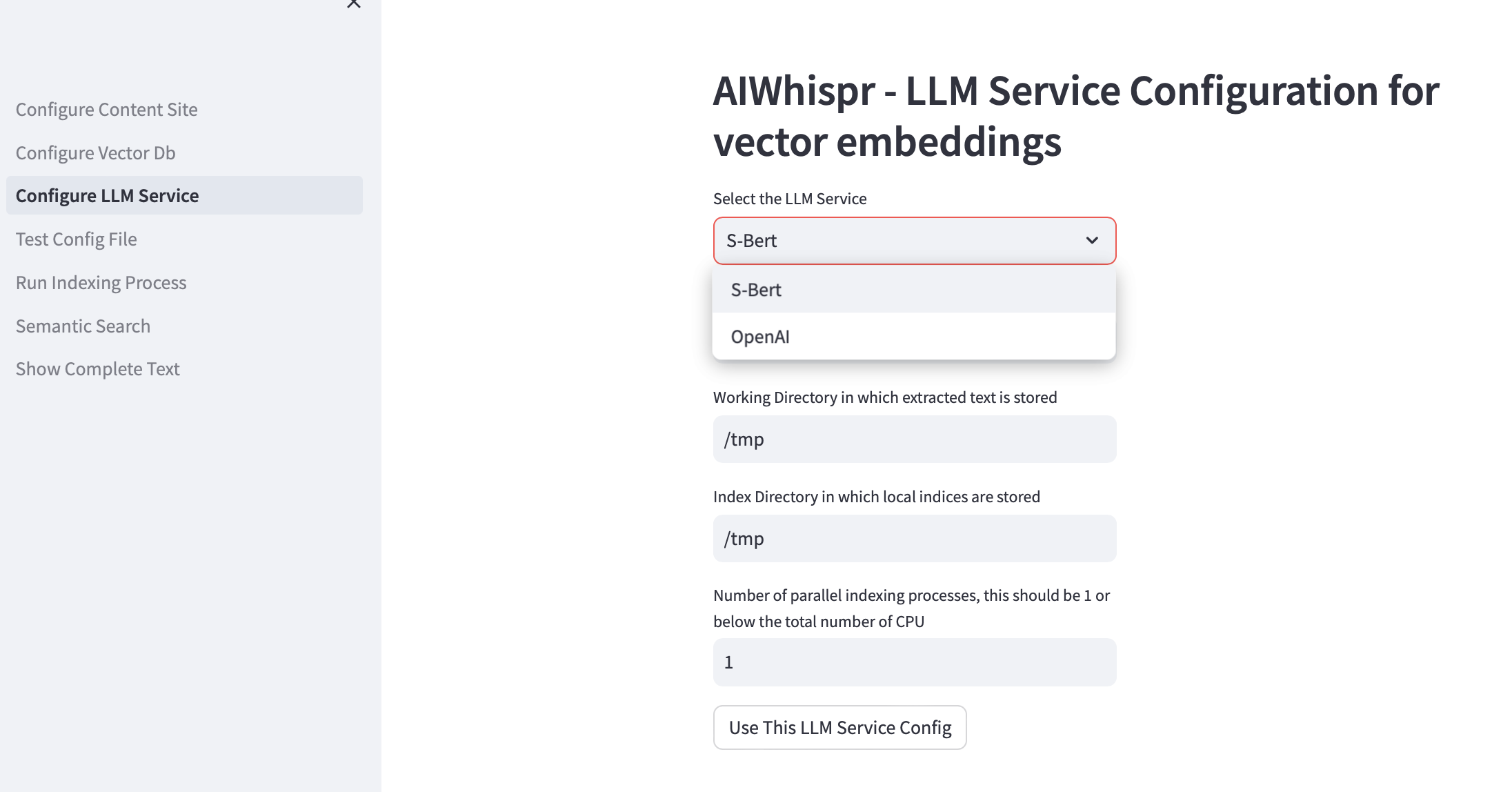
您可以选择使用本地运行的 Sbert 预训练模型或使用 OpenAI API 创建向量嵌入。
对于 SBert 模型系列,使用的默认模型是 all-mpnet-base-v2。您可以指定另一个 SBert 模型。
对于 OpenAI,默认嵌入模型是 text-embedding-ada-002
默认工作目录是/tmp
工作目录是本地计算机上的位置,它将用作处理从存储位置读取/下载的文件的工作目录。然后,从文档中提取的文本会被分成较小的大小(通常为 700 个单词),然后将其编码为向量嵌入。工作目录用于存储文本块。
默认本地索引目录是/tmp
您可以为工作目录和索引目录指定持久的本地目录路径。
index-dir 用于存储必须读取的内容文件的索引列表。 AIWhispr 支持多个进程进行索引,每个进程将使用自己的索引列表,从而允许您利用计算机上的多个 CPU。
如果您想利用多个 CPU 进行索引(读取内容、创建向量嵌入、存储在向量数据库中),请在测试框中指定并行进程数。我们的建议是该值应为 1 或最大值(CPU 数量/2)。例如,在 8 CPU 计算机上,此值应设置为 4。AIWhispr 使用多处理来绕过 Python GIL 限制。
单击“使用此 LLM 服务配置”以创建矢量嵌入管道配置文件的最终版本。
将显示配置文件的内容及其在计算机上的位置。
您可以通过单击左侧边栏中的“测试配置文件”来测试此配置。
4. 测试配置
您现在应该看到一条消息,显示矢量嵌入管道配置文件的位置和一个按钮“测试配置文件”
单击该按钮将启动该过程,该过程将测试管道配置
您应该在日志末尾看到“NO ERRORS”消息,通知您可以使用此管道配置。
单击左侧边栏中的“运行索引过程”以启动管道。
5. 运行索引过程
您应该看到一个“开始索引”按钮。
单击此按钮启动管道。日志每 15 秒更新一次。
默认示例索引 2000 多个 BBC 新闻报道,大约需要 20 分钟。
当索引进程正在运行时,即当 Streamlit“正在运行”状态显示在右上角时,请勿离开此页面。
您还可以在计算机上使用 grep 检查索引进程是否正在运行。
ps -ef | grep python3 | grep index_content_site.py
6. 语义搜索
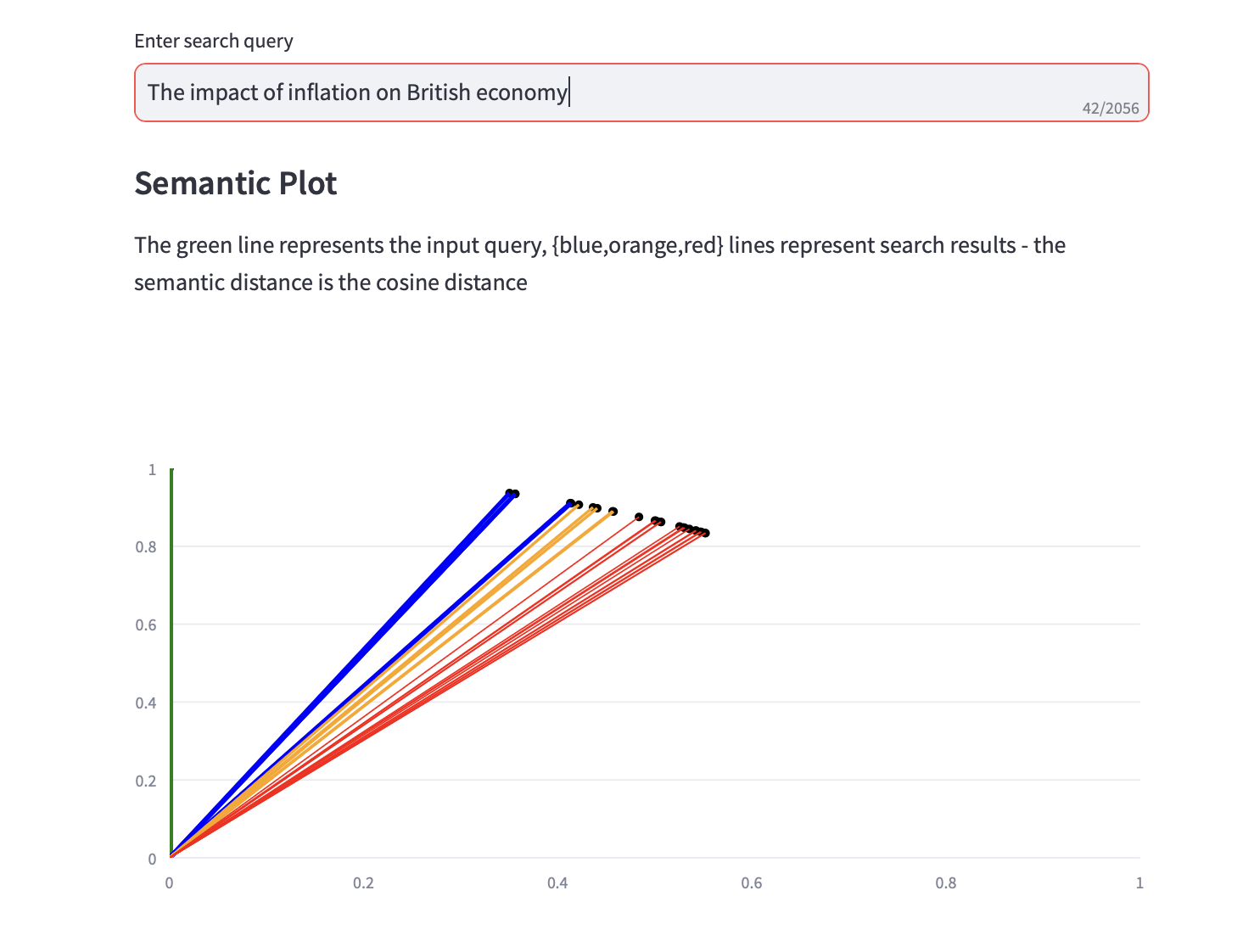
您现在可以运行语义搜索查询。
显示余弦距离的语义图以及搜索结果的前 3 个 PCA 分析也与文本搜索结果一起显示。