Qmedia
1.0.0
英语| 简体中文
变更日志 - 报告问题 - 请求功能
1内容卡2多模式内容抹布3纯本地多式联运模型QMedia是一款开源多媒体AI内容搜索引擎,为文本/图像和短视频内容提供丰富的信息提取方法。它整合非结构化文本/图像和短视频信息,构建多模态RAG内容问答系统。目的是以开源的方式分享和交流人工智能内容创作的想法。问题
与您的朋友分享 QMedia。
激发内容创作的新想法
| 加入我们的 Discord 社区! | |
|---|---|
 | 加入我们的微信群吧! |
Web Service受 XHS 网页版启发,使用 Typescript、Next.js、TailwindCSS 和 Shadcn/UI 技术栈实现RAG Search/Q&A Service和Image/Text/Video Model ServiceRAG Search/Q&A Service 、 Image/Text/Video Model Service可以单独部署,根据用户资源灵活部署,也可以嵌入到其他系统中进行图文视频内容提取。 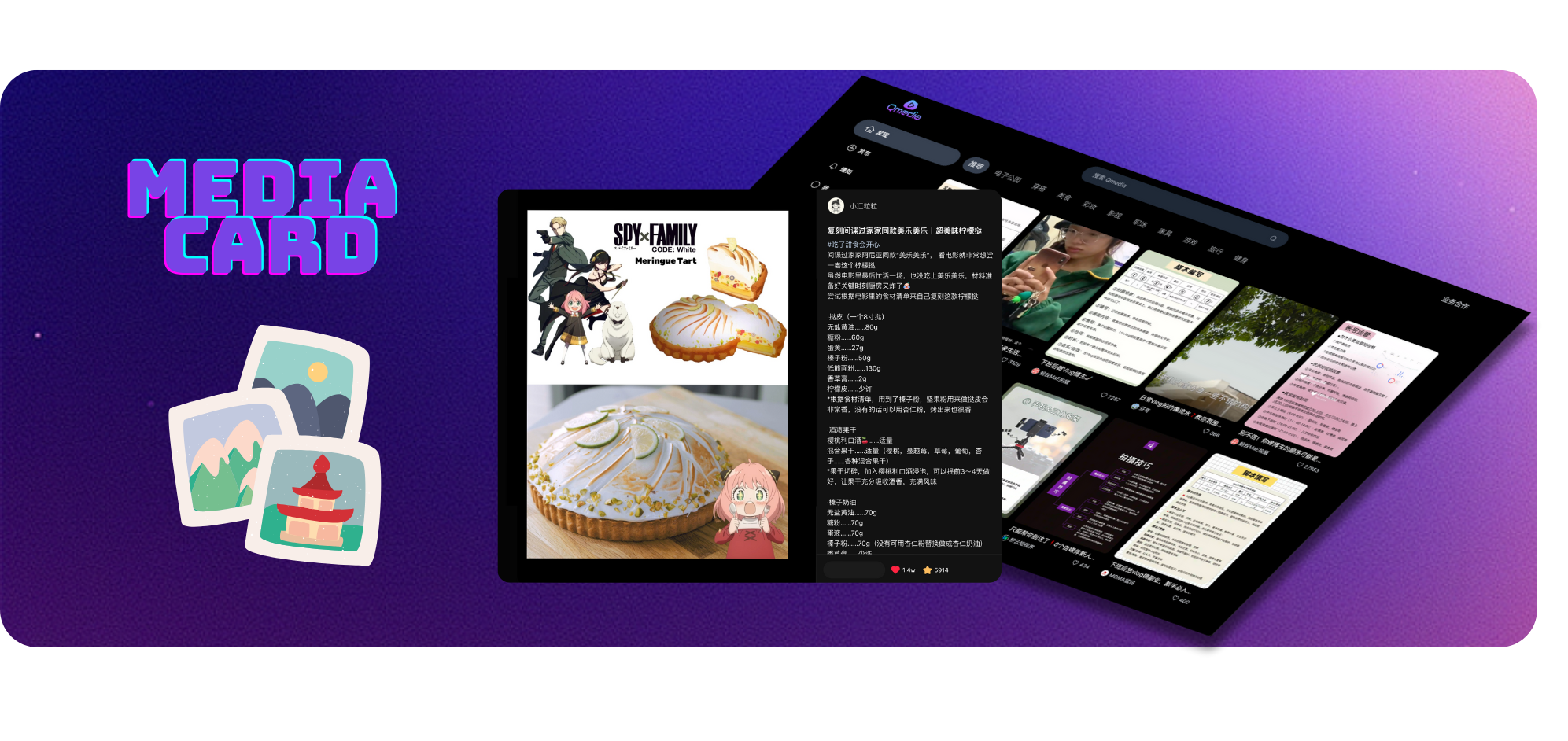
本地部署各类模型 与RAG应用层分离,方便更换不同模型 本地模型生命周期管理,可配置手动或自动发布,减少服务器负载
语言模型:
特征嵌入模型:
图像模型:
视觉理解模型:
视频模型
QMedia服务:根据资源可用性,可以部署在本地,也可以将模型服务部署在云端
多模式模型服务mm_server :
多模态模型部署和API调用
奥拉马 LLM 模型
图像模型
视频模型
特征嵌入模型
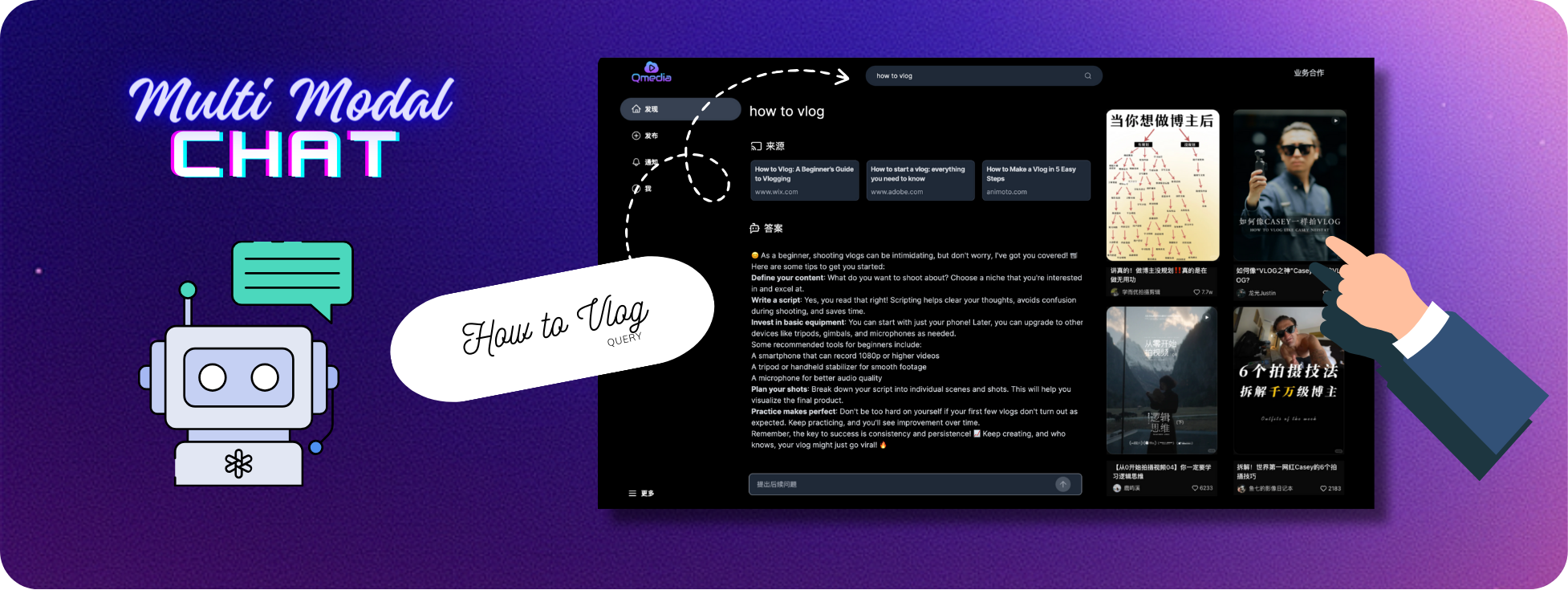
内容搜索和问答服务mmrag_server :
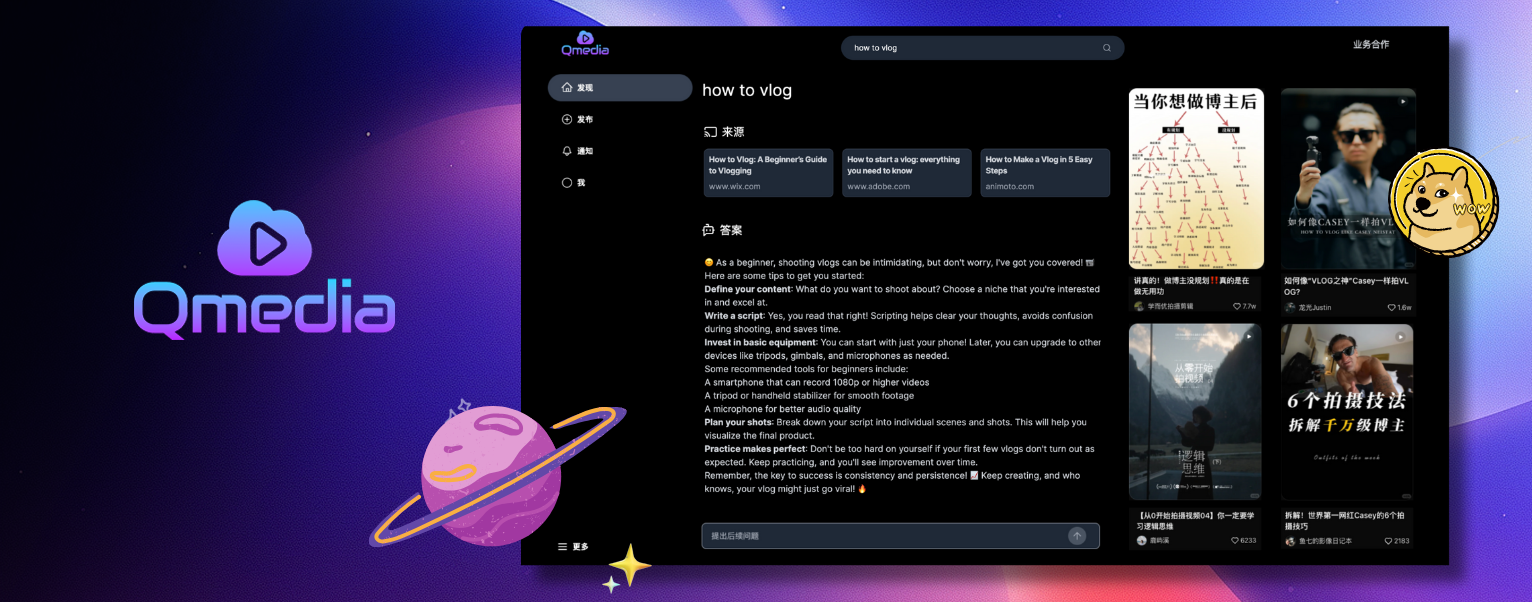
内容卡展示及查询
图片/文本/短视频内容提取、嵌入、存储服务
多模态数据 RAG 检索服务
内容问答服务
qmedia_web :语言:TypeScript 框架:Next.js 样式:Tailwind CSS 组件:shadcn/uimm_server + qmedia_web + mmrag_server网页内容展示、内容RAG搜索与问答、模型服务
# Start mm_server service
cd mm_server
source activate qllm
python main.py
# Start mmrag_server service
cd mmrag_server
source activate qmedia
python main.py
# Start qmedia_web service
cd qmedia_web
pnpm devmmrag_server会从assets/medias和assets/mm_pseudo_data.json中读取伪数据,并调用mm_server将文本/图像和短视频中的信息提取并结构化为node信息,然后存储在db中。检索和问答将基于db中的数据。 # assets file structure
assets
├── mm_pseudo_data.json # Content card data
└── medias # Image/Video files替换assets中的内容,并删除历史存储的db文件。 assets/medias包含图片/视频文件,可以替换为自己的图片/视频文件。 assets/mm_pseudo_data.json包含内容卡数据,可以替换为您自己的内容卡数据。运行服务后,模型将自动提取信息并将其存储在db中。
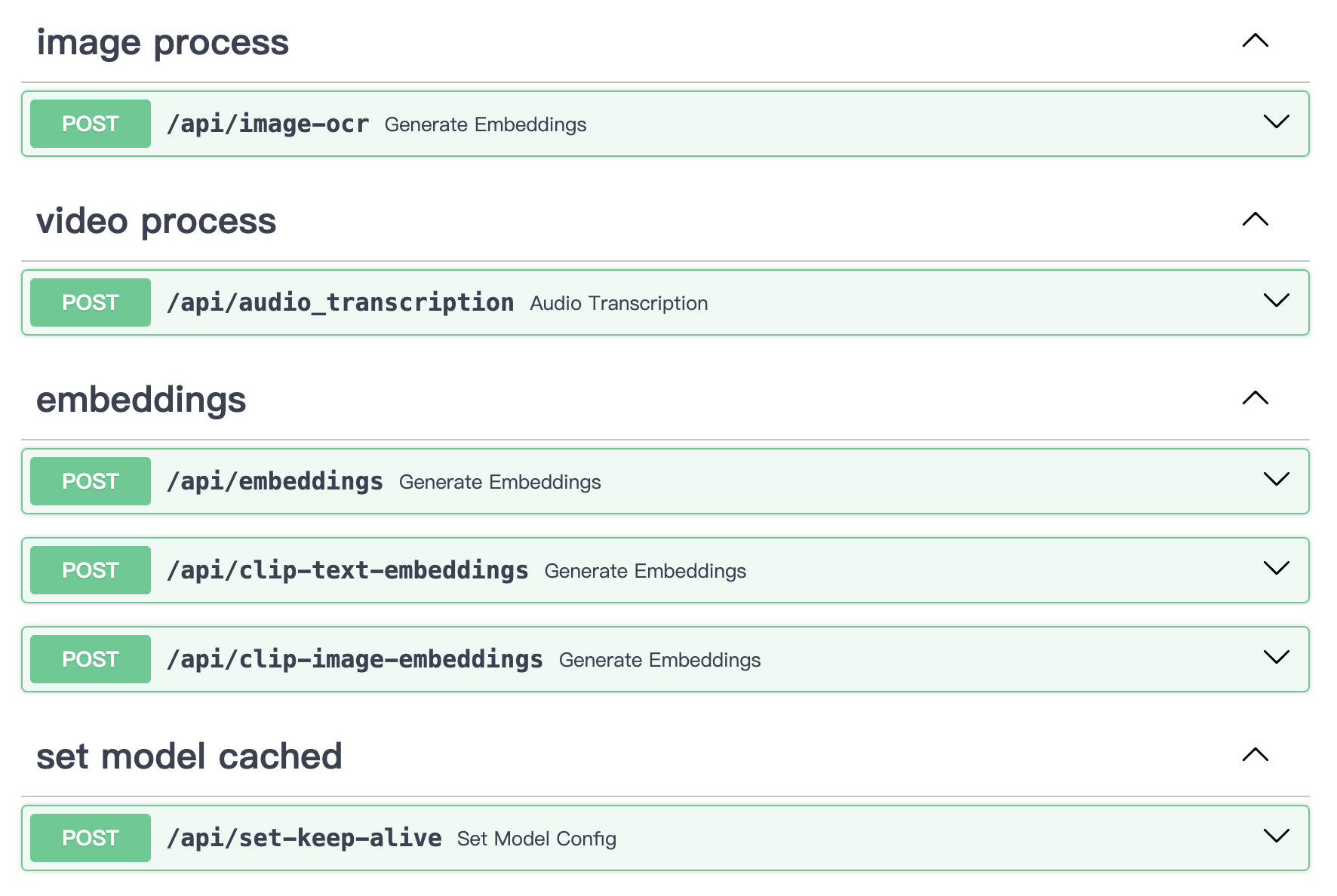
可以独立使用mm_server本地图文视频信息提取服务。它可以用作独立的图像编码、文本编码、视频转录提取和图像 OCR 服务,可在任何场景下通过 API 访问。
# Start mm_server service independently
cd mm_server
python main.py
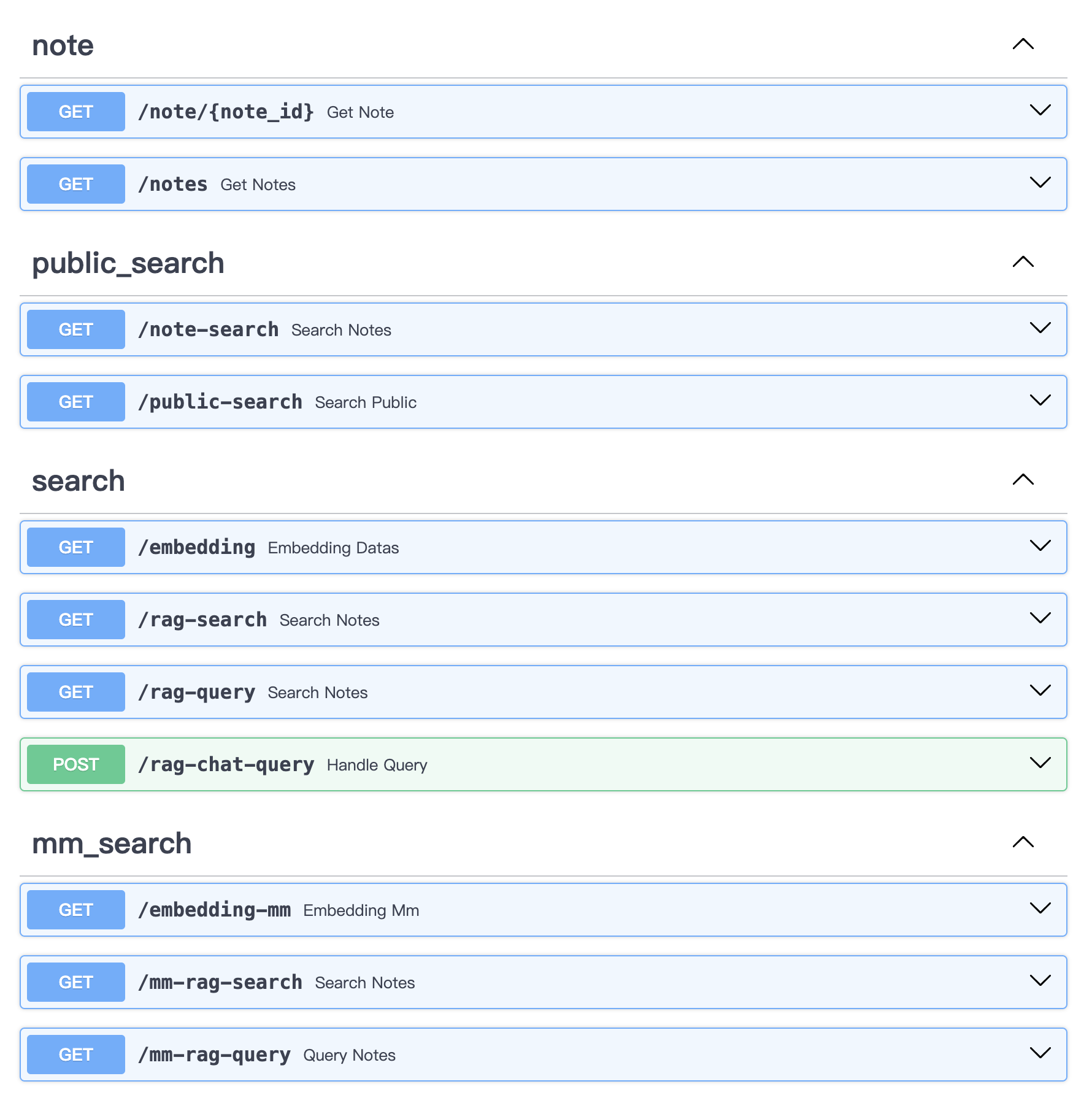
# uvicorn main:app --reload --host localhost --port 50110API内容:
可以结合使用mm_server + qmedia_web通过API在纯Python环境中执行内容提取和RAG检索。
# Start mmrag_server service independently
cd mmrag_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110API内容:
QMedia已获得 MIT 许可
感谢 QAnything 提供的强大 OCR 模型。
感谢 llava-llama3 强大的 llm 视觉模型。


