sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
维护者: jcudit 和 lsgos
项目至少维持到(YYYY-MM-DD): 2023-03-14
这是如何使用 Cohere API 构建简单语义搜索引擎的示例。它并不是为了生产就绪或有效扩展(尽管可以适应这些目的),而是为了展示生成由 Cohere 大型语言模型 (LLM) 生成的表示形式支持的搜索引擎的简便性。
这里使用的搜索算法相当简单:它只是使用co.embed端点找到与问题的表示最匹配的段落。下面对此进行了更详细的解释,但这里有一个简单的图表来说明正在发生的事情。首先,我们将输入文本分解为一系列段落,将它们在输入中的地址存储到列表中,并使用co.embed为每个段落生成向量嵌入:
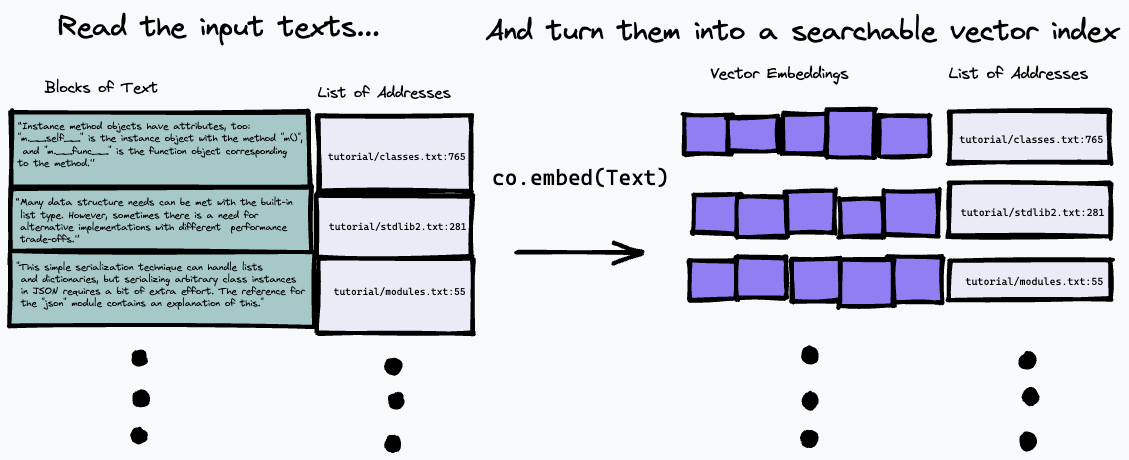
然后,我们可以通过嵌入文本查询来查询索引,并使用某种向量相似度度量(我们使用余弦相似度)查找源文本中具有最接近匹配的段落: 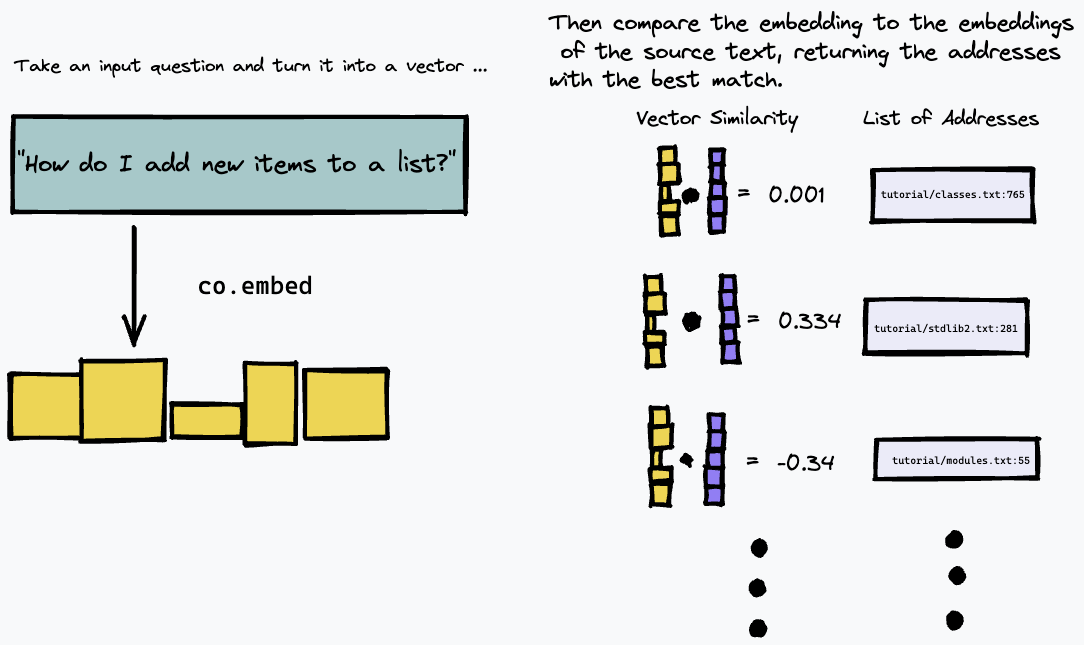
因此,它最适合文本源,其中给定问题的答案可能由文本中的具体段落给出,例如技术文档或内部 wiki,它们被构造为具体说明或事实的列表。例如,它在回答有关小说等自由格式文本的问题时效果不佳,因为小说中的信息可能分散在几个段落中;为此,您需要使用不同的方法来索引文本。
例如,该存储库在最新 python 文档的文本版本上构建了一个简单的语义搜索引擎。
要安装 python 要求,请确保已安装诗歌并运行:
# install python deps
poetry install您还应该安装 docker。在 OS X 上,如果您使用自制程序,我们建议运行
brew install --cask docker在 OS X 上首次运行 docker(例如运行我们的服务器)之前,请打开 Docker 应用程序并授予其在系统上运行所需的权限。
您还需要在COHERE_TOKEN中有一个 Cohere API 密钥。从 Cohere 平台获取一个(如果需要,创建一个帐户),并将其写入您的环境
export COHERE_TOKEN= < MY_API_KEY > (其中<MY_API_KEY>是您获得的密钥,不带<...>括号)。
或者,您可以将COHERE_TOKEN=<MY_API_KEY>作为附加参数传递给下面的任何make命令。
按照以下步骤首先构建文档集合的语义索引。这些步骤为官方 python 文档生成语义索引,但可以适用于任意数据收集。
首先,通过运行以下命令之一下载 python 文档。
如果你想快速开始,请运行
make download-python-docs-small将文档集限制为 python 教程。我们仅建议您进行快速测试,因为结果非常有限。
如果你想在整个 python 文档中测试搜索引擎,请运行
make download-python-docs但请注意,生成嵌入将需要几个小时(尽管这只需要完成一次)。
或者,如果您想尝试自己的文本,只需将其作为.txt文件下载到此存储库中名为txt/目录中。
获得一些文本后,我们需要将其处理为嵌入和地址的搜索索引。
这可以通过使用命令来完成
make embeddings假设您的目标文本位于./txt/目录下。
该命令将递归地搜索./txt/目录中具有.txt扩展名的文件,并构建一个包含每个段落的嵌入、文件名和行号的简单数据库。
警告:如果您有大量文本要搜索,这可能需要一些时间才能完成!
构建了embeddings.npz文件后,您可以使用以下命令构建一个 docker 映像,该映像将提供一个简单的 REST 应用程序,以允许您查询您创建的数据库:
make build然后您可以使用启动服务器
make run对于一个简单的例子来说,这有点矫枉过正,但它的目的是反映建立大量文本的索引相对较慢的事实,并确保查询引擎的速度很快。
如果您想将此项目用作实际应用程序的构建块,您可能需要在服务器体系结构中维护文本嵌入数据库并使用轻量级客户端对其进行查询。将服务器打包为 Docker 应用程序意味着通过将其部署到云服务来将其转变为“真正的”应用程序非常简单。
如果您为以下任何选项打开新的终端窗口,请记住运行
export COHERE_TOKEN= < MY_API_KEY > 到目前为止,最简单的选择是运行我们的帮助程序脚本:
scripts/ask.sh " My query here "来查询数据库。该脚本采用可选的第二个参数来指定所需结果的数量。
脚本弹出修改后的vim界面,命令如下:
q退出。顶部窗格将显示文档中找到结果的位置。
服务器运行后,您可以使用简单的 REST API 对其进行查询。您可以转至此处的/docs#/default/search_search_post直接探索 API。这是一个简单的 JSON REST API;以下是如何使用curl进行查询:
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
这将返回长度为num_results的 JSON 列表,每个列表都包含与查询最接近语义匹配的块的文件名和行号( doc_url和block_url )。但您可能实际上只想阅读文件中的部分内容,这是最好的答案。
当我们搜索本地文本文件时,使用命令行工具解析输出实际上更容易一些;使用提供的 python 脚本utils/query_server.py在命令行上查询它。 query_server.py以标准file_name:line_number:格式打印结果,因此我们可以利用vim的快速修复模式以一种很好的方式对实际结果进行分页。
假设你的机器上有 vim,你可以简单地
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
让 vim 在搜索算法返回的位置打开索引文本文件。 (使用:qall关闭窗口和快速修复导航器)。您可以使用:cn和:cp循环显示返回的结果。结果并不完美;这是语义搜索,因此您可能会期望匹配有点模糊。尽管如此,我经常发现你可以在前几个结果中得到问题的答案,并且使用 Cohere 的 API 可以让你用自然语言表达你的问题,并且让你只需几行代码就可以构建一个非常有效的搜索引擎。
python 文档案例中的一些值得尝试的查询表明搜索在通用自然语言问题上运行良好,包括:
How do I put new items in a list? (请注意,这个问题避免使用关键字“append”,并且与文档解释append的方式不完全匹配(他们说它用于将新项目添加到列表的末尾)。但是语义搜索正确地指出相关段落仍然是最佳匹配。)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (注意这个问题,我的第一个结果是关于基本上这个确切主题的常见问题解答,但问题措辞不同。但是,由于它是语义搜索,我们的算法正确地挑选出与含义匹配的结果,而不仅仅是我们的查询的措辞)How do I remove an item from a set?How do list comprehensions work?该存储库使用非常简单的策略来索引文档并搜索最佳匹配。首先,它将每个文档分成段落或“块”。然后,它在每个段落上调用co.embed ,以便使用 Cohere 的语言模型生成向量嵌入。然后,它将每个嵌入向量以及相应的文档和段落的行号存储在一个简单的数组中作为“数据库”。
为了实际进行搜索,我们使用 FAISS 相似性搜索库。当我们收到查询时,我们使用相同的 Cohere API 调用来嵌入查询。然后我们使用 FAISS 来找到顶部
如果您有任何问题或意见,请提出问题或通过 Discord 联系我们。
如果您想为此项目做出贡献,请阅读此存储库中的CONTRIBUTORS.md ,并在提交任何拉取请求之前签署贡献者许可协议。当您第一次向 Cohere 存储库发出拉取请求时,将会生成一个用于签署 Cohere CLA 的链接。
Toy Semantic Search 具有 MIT 许可证,如 LICENSE 文件中所示。


