wagtail_textract
1.0.0
该软件包未维护,我们也没有计划维护它。
我们建议您使用它作为示例,也许将代码复制到您自己的项目中,但不要安装该包。
该包用于将 Wagtail 的 Document 类替换为允许使用 textract 在文档文件内容中搜索的类。
Textract 可以从(以及其他)PDF、Excel 和 Word 文件中提取文本。
该包的灵感来自 Wagtail 中的“搜索:从文档中提取文本”问题。
文档将像以前一样工作,只是 Wagtail 管理界面中的文档搜索也会在文件内容中查找搜索词。
一些屏幕截图来说明。
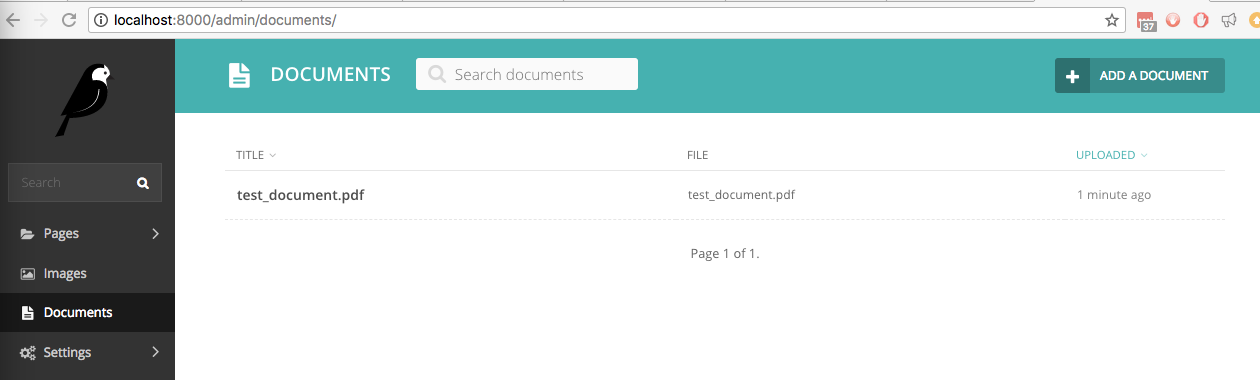
在安装了wagtail_textract的新 Wagtail 网站中,我们上传了一个名为test_document.pdf的文件,其中包含手写文本。它列在管理界面的文档下:
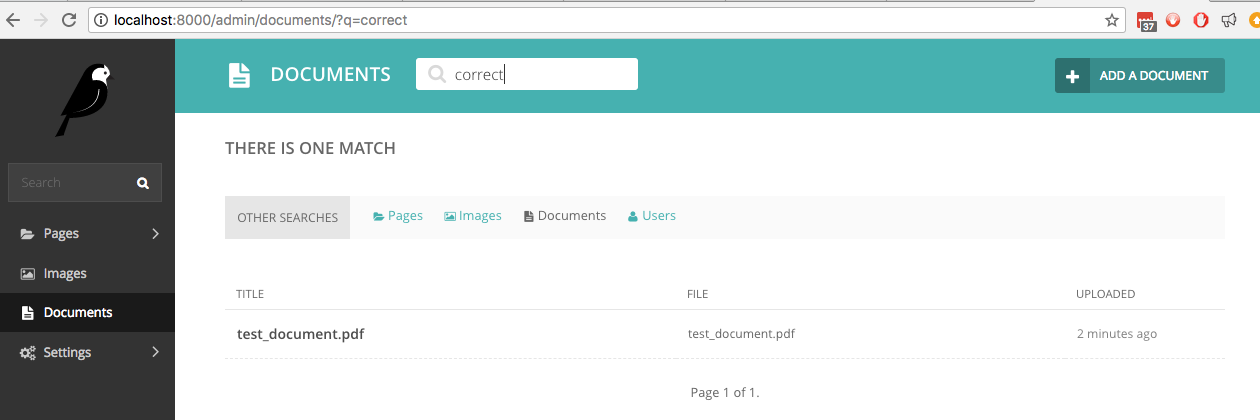
如果我们现在在文档中搜索单词correct ,这是手写单词之一,实时搜索会找到它:
假设这个搜索不仅应该在 Wagtail 的管理界面中可用,而且还应该在面向公众的搜索视图中可用,我们为此提供了一个代码示例。
自 2018 年 8 月以来,我们一直在 https://nuffic.nl 上的生产中使用此包。
wagtail_textract添加到您的要求和/或pip install wagtail_textractINSTALLED_APPS 。WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document"添加到 Django 设置中。注意:在安装 wagtail_texttract 期间您会收到不兼容警告(已安装 Wagtail 2.0.1):
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
我们还没有看到这会导致问题,但需要记住这一点。
为了使textract使用 Tesseract(如果常规textract找不到文本,就会发生这种情况),您需要添加 Tesseract 可以基于其单词匹配的数据文件。
在你的项目目录下创建tessdata目录,然后下载你想要的语言。
文档保存后,转录在asyncio执行器中自动完成,以防止在处理过程中阻塞响应。
要转录所有现有文档,请运行管理命令:
./manage.py transcribe_documents
显然,这可能需要很长时间。
以下是显示页面和文档结果的搜索视图(在 Wagtail 管理界面之外)的代码示例。
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
})您的模板应该允许以不同于页面的方式处理文档,因为您无法在文档上执行pageurl result :
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} 为了使用 wagtail_texttract,您的CustomizedDocument模型应该与 wagtail_textract 的 Document 执行相同的操作:
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
]请注意,子类的第一个类应该是TranscriptionMixin ,因此它的save()优先于其他父类的 save() 。
要运行测试,请查看此存储库并:
make test
覆盖率报告将在./coverage_html_report/中生成。


