yagooglesearch
v1.10.0
yagooglesearch是一个 Python 库,用于执行智能、逼真且可调的 Google 搜索。它模拟真实的人类 Google 搜索行为,以防止 Google 进行速率限制(可怕的 HTTP 429 响应),如果 HTTP 429 被 Google 阻止,则逻辑会后退并继续尝试。该库不使用 Google API,并且很大程度上基于 googlesearch 库。其特点包括:
requests库进行 HTTP 请求和 cookie 管理该代码按原样提供,您对其使用方式承担全部责任。抓取 Google 搜索结果可能会违反其服务条款。另一个 Python Google 搜索库有一些有趣的信息/讨论:
Google 的首选方法是使用他们的 API。
pip install yagooglesearchgit clone https://github.com/opsdisk/yagooglesearch
cd yagooglesearch
virtualenv -p python3 .venv # If using a virtual environment.
source .venv/bin/activate # If using a virtual environment.
pip install . # Reads from pyproject.toml import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
max_search_result_urls_to_return = 100 ,
http_429_cool_off_time_in_minutes = 45 ,
http_429_cool_off_factor = 1.5 ,
# proxy="socks5h://127.0.0.1:9050",
verbosity = 5 ,
verbose_output = True , # False (only URLs) or True (rank, title, description, and URL)
)
client . assign_random_user_agent ()
urls = client . search ()
len ( urls )
for url in urls :
print ( url )尽管通过 GUI 搜索 Google 将显示类似“大约 13,000,000 个结果”的消息,但这并不意味着yagooglesearch会找到与此接近的任何内容。测试最多返回400条左右的结果。如果您设置 400 < max_search_result_urls_to_return ,一条警告消息将打印到日志中。参见#28 的讨论。
使用yagooglesearch执行 Google 搜索时的策略是低而慢。如果您开始收到 HTTP 429 响应,则 Google 已正确地将您检测为机器人,并将在一段时间内阻止您的 IP。 yagooglesearch无法绕过验证码,但您可以通过从浏览器执行 Google 搜索并证明您是人类来手动执行此操作。
被阻止的标准和阈值尚不清楚,但一般来说,随机化用户代理、在分页搜索结果之间等待足够的时间(7-17 秒)以及在不同的 Google 搜索之间等待足够的时间(30-60 秒)就足够了。不过,您的里程肯定会有所不同。将此库与 Tor 一起使用可能会很快阻止您。
如果yagooglesearch检测到来自 Google 的 HTTP 429 响应,它将休眠http_429_cool_off_time_in_minutes分钟,然后重试。每次检测到 HTTP 429 时,等待时间都会增加http_429_cool_off_factor倍。
目标是让yagooglesearch担心 HTTP 429 检测和恢复,而不会给使用它的脚本带来负担。
如果您不希望yagooglesearch处理 HTTP 429 而希望自己处理,请在实例化 yagooglesearch 对象时传递yagooglesearch_manages_http_429s=False 。如果检测到 HTTP 429,字符串“HTTP_429_DETECTED”将添加到将返回的列表对象中,下一步应该由您决定。列表对象将包含在检测到 HTTP 429 之前找到的所有 URL。
import yagooglesearch
query = "site:twitter.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
verbosity = 4 ,
num = 10 ,
max_search_result_urls_to_return = 1000 ,
minimum_delay_between_paged_results_in_seconds = 1 ,
yagooglesearch_manages_http_429s = False , # Add to manage HTTP 429s.
)
client . assign_random_user_agent ()
urls = client . search ()
if "HTTP_429_DETECTED" in urls :
print ( "HTTP 429 detected...it's up to you to modify your search." )
# Remove HTTP_429_DETECTED from list.
urls . remove ( "HTTP_429_DETECTED" )
print ( "URLs found before HTTP 429 detected..." )
for url in urls :
print ( url )
yagooglesearch支持使用代理。提供的代理用于搜索的整个生命周期,使其看起来更人性化,而不是针对搜索的不同部分轮流使用各种代理。一般搜索生命周期为:
google.com要使用代理,请在初始化yagooglesearch.SearchClient对象时提供代理字符串:
client = yagooglesearch . SearchClient (
"site:github.com" ,
proxy = "socks5h://127.0.0.1:9050" ,
)支持的代理方案基于 Python requests库中支持的方案 (https://docs.python-requests.org/en/master/user/advanced/#proxies):
httphttpssocks5 - “导致 DNS 解析发生在客户端,而不是代理服务器上。”您可能不希望这样做,因为所有 DNS 查找都来自运行yagooglesearch位置而不是代理。socks5h - “如果您想解析代理服务器上的域,请使用socks5h作为方案。”如果您使用 SOCKS,这是最佳选择,因为 DNS 查找和 Google 搜索源自代理 IP 地址。 如果您对 HTTPS 代理使用自签名证书,则在以下情况下可能需要禁用 SSL/TLS 验证:
yagooglesearch.SearchClient对象: import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verify_ssl = False ,
verbosity = 5 ,
) query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verbosity = 5 ,
)
client . verify_ssl = False 如果您想使用多个代理,那么该负担就落在利用yagooglesearch库使用不同代理实例化新的yagooglesearch.SearchClient对象的脚本上。下面是循环代理列表的示例:
import yagooglesearch
proxies = [
"socks5h://127.0.0.1:9050" ,
"socks5h://127.0.0.1:9051" ,
"http://127.0.0.1:9052" , # HTTPS proxy with a self-signed SSL/TLS certificate.
]
search_queries = [
"python" ,
"site:github.com pagodo" ,
"peanut butter toast" ,
"are dragons real?" ,
"ssh tunneling" ,
]
proxy_rotation_index = 0
for search_query in search_queries :
# Rotate through the list of proxies using modulus to ensure the index is in the proxies list.
proxy_index = proxy_rotation_index % len ( proxies )
client = yagooglesearch . SearchClient (
search_query ,
proxy = proxies [ proxy_index ],
)
# Only disable SSL/TLS verification for the HTTPS proxy using a self-signed certificate.
if proxies [ proxy_index ]. startswith ( "http://" ):
client . verify_ssl = False
urls_list = client . search ()
print ( urls_list )
proxy_rotation_index += 1 如果您有GOOGLE_ABUSE_EXEMPTION cookie 值,则可以在实例化SearchClient对象时将其传递到google_exemption中。
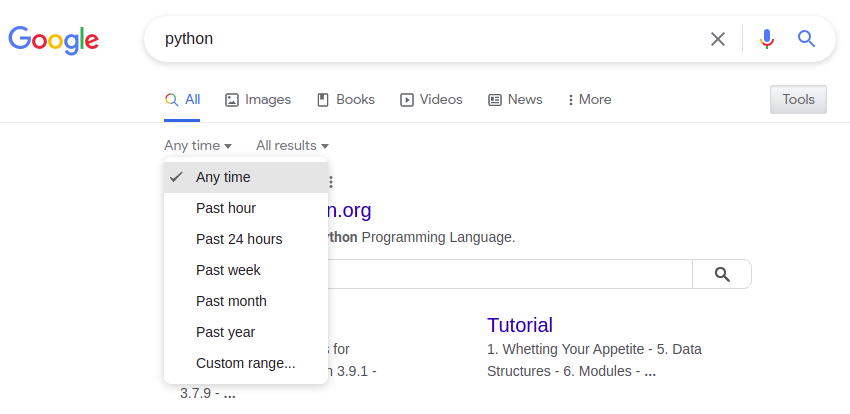
&tbs=参数用于指定逐字过滤器或基于时间的过滤器。
&tbs=li:1
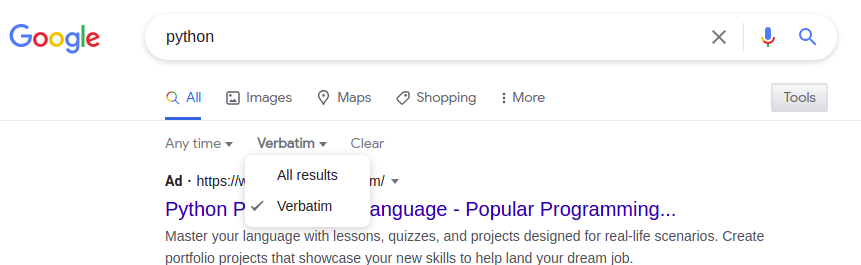
| 时间过滤器 | &tbs= URL 参数 | 笔记 |
|---|---|---|
| 过去一小时 | 季度:h | |
| 过去的一天 | qdr:d | 过去 24 小时 |
| 过去一周 | qdr:w | |
| 过去一个月 | 日期:米 | |
| 去年 | qdr:y | |
| 风俗 | cdr:1,cd_min:1/1/2021,cd_max:6/1/2021 | 请参阅 yagooglesearch.get_tbs() 函数 |
目前, .filter_search_result_urls()函数将删除任何包含“google”一词的网址。这是为了防止返回的搜索 URL 被 Google URL 污染。如果您尝试显式搜索 URL 中可能包含“google”的结果(例如site:google.com computer ,请注意这一点
根据 BSD 3 条款许可证分发。请参阅许可证了解更多信息。
@opsdisk
项目链接:https://github.com/opsdisk/yagooglesearch


