auctus
1.0.0
该项目是一个数据集的网络爬虫和搜索引擎,专门用于机器学习中的数据增强任务。它能够在不同存储库中查找数据集并为其建立索引以供以后检索。
文档可在此处获取
它分为多个组件:
datamart_geo 。其中包含从 Wikidata 和 OpenStreetMap 中提取的有关行政区域的数据。它位于自己的存储库中,并在此处用作子模块。datamart_profiler 。这可以由客户端安装,将允许客户端库在本地分析数据集,而不是将它们发送到服务器。 apiserver 和 profiler 服务也使用它。datamart_materialize 。这用于具体化 Auctus 支持的各种来源的数据集。它可以由客户端安装,这将允许他们在本地具体化数据集,而不是使用服务器作为代理。datamart_augmentation 。它执行两个数据集的连接或并集,并由 apiserver 服务使用,但也可以单独使用。datamart_core 。这包含服务的通用代码。仅用于服务器组件。出于性能原因(必须快速导入),文件系统锁定代码与datamart_fslock分开。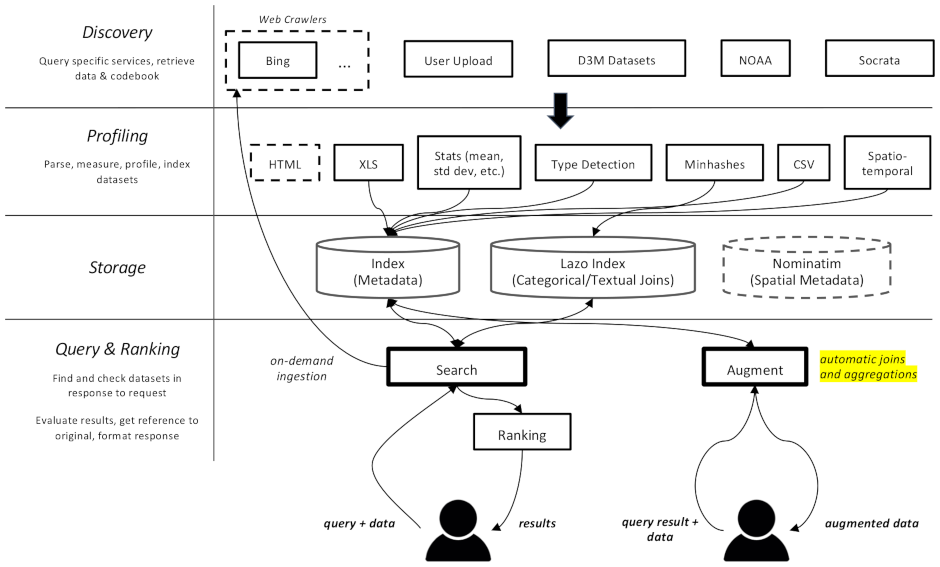
Elasticsearch 用作搜索索引,为每个已知数据集存储一个文档。
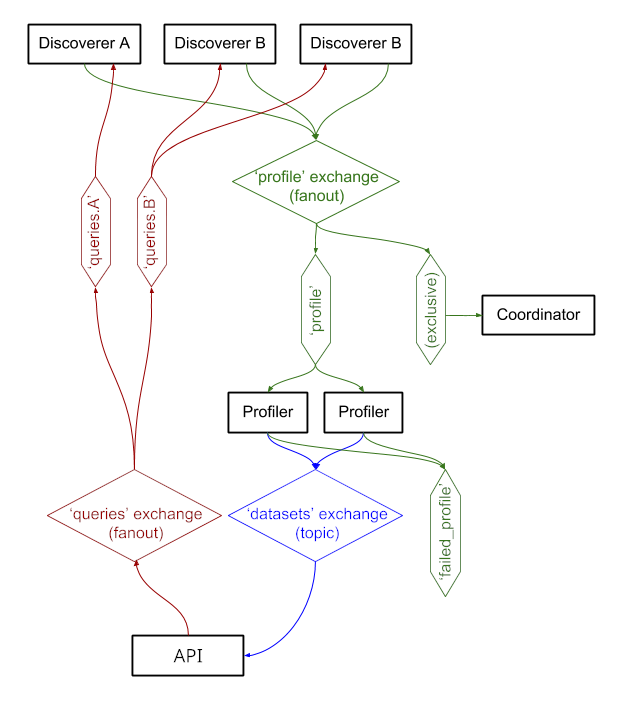
这些服务通过RabbitMQ交换消息,使我们能够拥有具有排队和重试语义的复杂消息传递模式,以及诸如按需查询之类的复杂模式。
该系统目前正在 https://auctus.vida-nyu.org/ 上运行。您可以在 https://grafana.auctus.vida-nyu.org/ 查看系统状态。
要使用 docker-compose 在本地部署系统,请执行以下步骤:
确保您已使用git submodule init && git submodule update检出子模块
确保您已安装并配置 Git LFS ( git lfs install )
将 env.default 复制到 .env 并更新其中的变量。您可能想要更新生产部署的密码。
确保您的节点已设置为运行 Elasticsearch。您可能必须提高 mmap 限制。
API_URL是 apiserver 容器对客户端可见的 URL。在生产部署中,这可能是面向公众的 HTTPS URL。如果使用反向代理,它可以与“协调器”组件提供服务的 URL 相同(请参阅 nginx.conf)。
要在本地运行脚本,您可以通过运行以下命令将环境变量加载到 shell 中. scripts/load_env.sh (即点空间脚本... )
运行scripts/setup.sh来初始化数据卷。这将为volumes/子目录设置正确的权限。
如果您想从头开始,可以删除volumes/但请确保之后再次运行scripts/setup.sh以设置权限。
$ docker-compose build --build-arg version=$(git describe) apiserver
$ docker-compose up -d elasticsearch rabbitmq redis minio lazo
这些将需要几秒钟才能启动并运行。然后就可以启动其他组件了:
$ docker-compose up -d cache-cleaner coordinator profiler apiserver apilb frontend
您可以使用--scale选项启动更多分析器或 apiserver 容器,例如:
$ docker-compose up -d --scale profiler=4 --scale apiserver=8 cache-cleaner coordinator profiler apiserver apilb frontend
端口:
$ scripts/docker_import_snapshot.sh
这将从 auctus.vida-nyu.org 下载 Elasticsearch 转储并将其导入到本地 Elasticsearch 容器中。
$ docker-compose up -d socrata zenodo
$ docker-compose up -d elasticsearch_exporter prometheus grafana
Prometheus 配置为自动查找容器(请参阅 prometheus.yml)
使用自定义 RabbitMQ 映像,并添加插件(管理和 prometheus)。


