cape webservices
1.0.0
所有后端 Cape Web 服务的入口点。
前端演示在这里(仅当您已经启动后端时才有效)。
Cape 是一套开源库,用于管理问答模型,通过自动“阅读”文档来回答问题。它基于在海量数据集上训练的最先进的机器阅读模型,并包含多种机制,使其易于使用并根据用户反馈进行改进。它被设计为可移植的,即在单个笔记本电脑或并行计算机集群上工作以加速计算,并且是开源友好的,可在所有专业水平上使用。
它使用户能够
有多种使用 Cape 的方法:
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.rundocker run -p 5050:5050 bloomsburyai/cape我们建议至少 3GB RAM 和至少 2 个现代 CPU 核心(如果是虚拟的,则为 4 个)。如果您使用 Docker,请确保增加 Docker 首选项中的内存资源限制。
您可以运行包含管理仪表板的独立版本的 Web 应用程序。安装 docker 后,更新并运行 Cape 镜像:
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
这将启动后端和前端 Web 服务,默认情况下它还会为两者创建隧道,输出公共 url:
RANDOM_STRING_HERE .ngrok.io?configuration={"api":{"backendURL":"https:// RANDOM_STRING_HERE .ngrok .io:5050","超时":"15000"}}拉取最新版本的 Docker 镜像(下载所有依赖项和机器读取模型需要一些时间): docker pull bloomsburyai/cape
运行 Docker 容器并使用以下命令在其中启动 IPython 控制台: docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
导入响应程序: from cape_responder.responder_core import Responder
提出问题并存储响应(答案列表)并使用以下命令显示第一个答案: response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
如果您有兴趣更多地了解响应的样子,请使用以下命令显示完整的响应: print(response)
要在 Linux 系统上本地安装 Cape,请查看部署/Dockerfile。
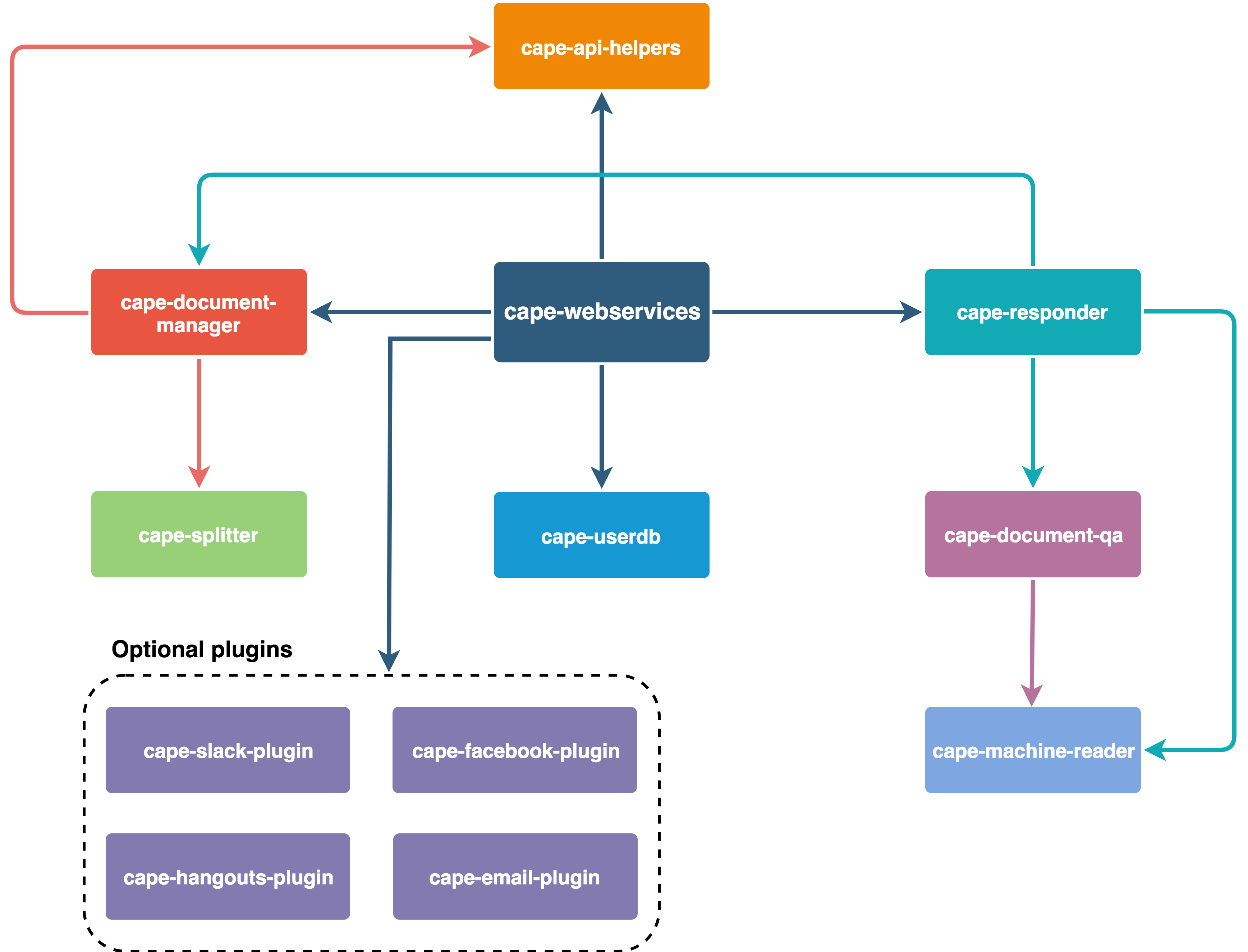
总而言之,Cape 的组织方式如下:


