VSA
1.0.0
[项目页面] [?论文] [?拥抱脸部空间] [模型动物园] [简介] [?视频]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
本地演示基于gradio,您可以简单地运行:
python app.py
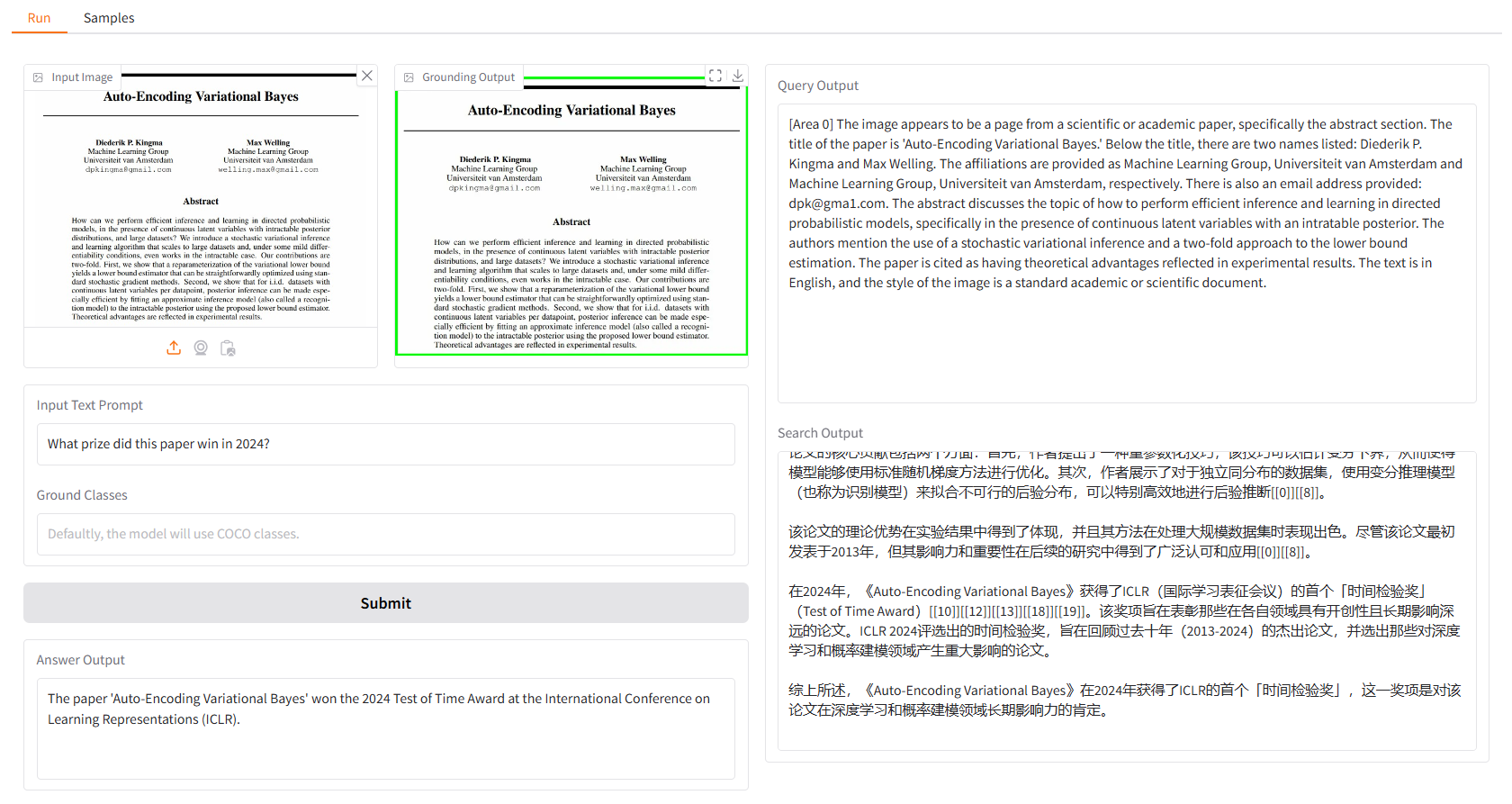
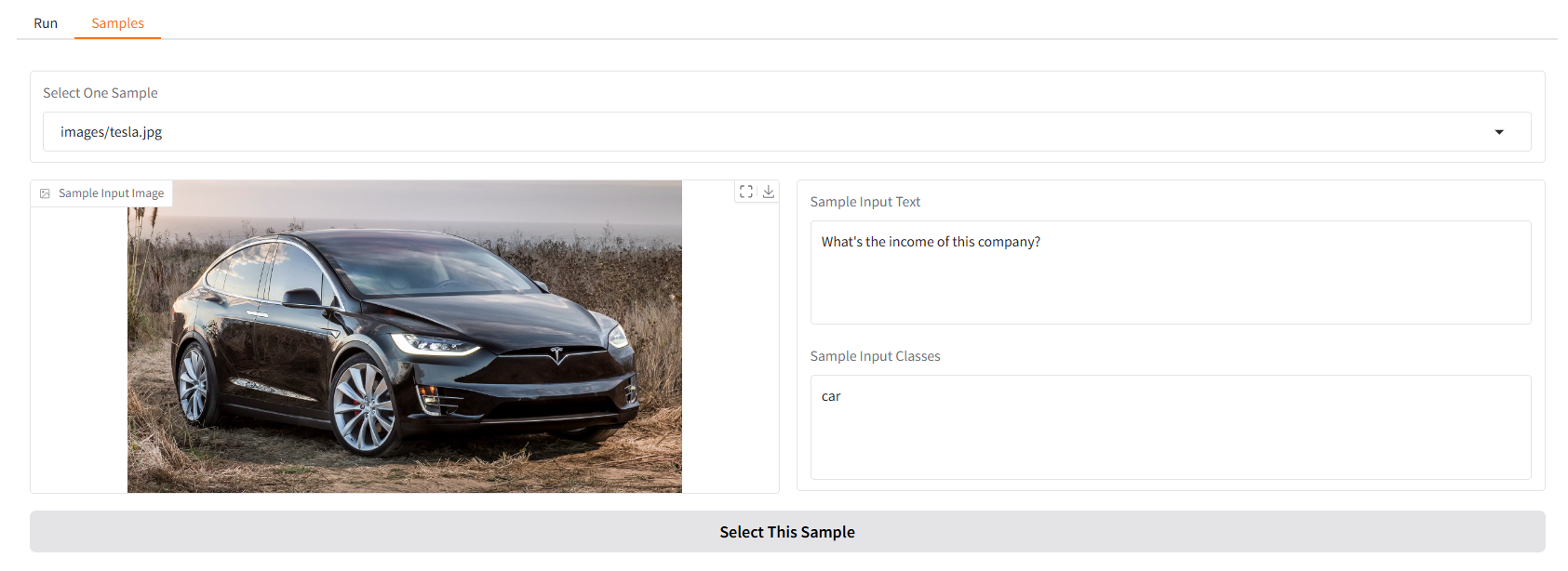
我们提供一些示例供您开始使用。在“Samples”UI 中,您可以在“Samples”面板中选择一个,单击“Select This Sample”,您会发现示例输入已经填充在“Run”UI 中。
您还可以通过运行在终端中与我们的视觉搜索助手聊天。
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
然后,选择图像并输入您的问题。
该项目是在 Apache 2.0 许可证下发布的。
Vision Search Assistant 深受以下对开源社区的杰出贡献的启发:GroundingDINO、LLaVA、MindSearch。
如果您发现该项目对您的研究有用,请考虑引用:
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


