ndvr
1.0.0
神经搜索黑客马拉松第二名?
我们目睹了各种视频共享网站中视频数据的爆炸式增长,互联网上有数十亿个视频,从大规模视频数据库中执行近重复视频检索(NDVR)成为一个重大挑战。 NDVR旨在从海量视频数据库中检索近似重复的视频,其中近似重复的视频被定义为视觉上接近原始视频的视频。
用户有强烈的动机去复制热门短视频并上传增强版本来获得关注。随着短视频的增长,检测近似重复短视频出现了新的困难和挑战。
在这里,我们使用 Jina 构建了一个神经搜索解决方案来解决 NDVR 的挑战。
目录

硬阳性候选视频示例。顶行:侧纹、滤色、水洗。中行:横屏改为竖屏,黑边较大。底行:旋转
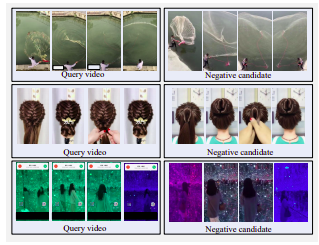
硬负面视频的示例。所有候选者在视觉上都与查询相似,但不接近重复。
选择候选视频有以下三种策略:
由于时间和资源的限制,我们决定采用转换检索策略。在实际应用中,用户会复制热门视频以获取个人激励。用户通常会选择稍微修改复制的视频以绕过检测。这些修改包括视频裁剪、边框插入等。
为了模仿这种用户行为,我们定义了一种时间变换,即视频加速,和三种空间变换,即视频裁剪、黑色边框插入和视频旋转。
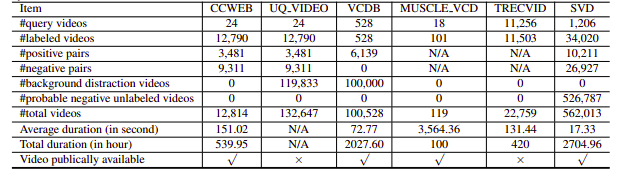
不幸的是,所研究的 NDVR 数据集要么分辨率低,要么巨大,要么特定领域,要么不公开(我们个人也很少联系过)。因此,我们决定创建小型自定义数据集进行实验。
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexFlow索引定义如下:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : true这分为以下步骤:
这里我们使用 YAML 文件来定义 Flow 并用它来索引数据。 index函数采用input_fn参数,该参数采用 Iterator 来传递文件路径,该文件路径将进一步包装在IndexRequest中并发送到 Flow。
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query然后,您可以使用自定义端点http://localhost:45678/api/search打开 Jinabox
查询流程定义如下:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.yml查询流程分为以下步骤:


