CrawlerTutorial
1.0.0
当我们在网路上浏览时,常常会看到各式各样感兴趣的内容,例如新闻、商品、影片、图片等等。但若是想从这些网页中搜集大量特定的资讯,手动操作就显得费时费力。
这时,网页爬虫(Web Crawler)就派上用场了!简单来说,网页爬虫就是可以模仿人类浏览器行为,自动抓取网页资讯的程式。利用这种程式的自动化能力,我们可以轻松地从网站上「爬取」我们感兴趣的资料,再把这些资料储存下来以供日后分析使用。
网页爬虫的运作方式通常是先向目标网站发送HTTP 请求,接着取得该网站回应的HTML 并解析页面中的内容,再将有用的资料取出来。例如,我们想要收集PTT 八卦版上的文章标题、作者、时间等资讯,就可以使用网页爬虫的技术,自动化抓取这些资讯并储存下来。这样一来就可以不用手动浏览网站,就能取得所需的资讯。
网页爬虫有很多实际的应用,例如:
当然,在使用网页爬虫时,我们需要遵守网站的使用条款及隐私政策,不可以违反网站的规定进行资讯抓取。同时,为了保障网站的正常运作,我们也需要设计适当的爬取策略,避免对网站造成过大的负荷。
本教学范例使用Python3 并且会使用pip 来安装所需的套件。以下是需要安装的套件:
requests :用于发送与接收HTTP 请求及回应。requests_html :用于分析和抓取HTML 中的元素。rich :让资讯精美地输出到console,例如显示美观的表格。lxml或PyQuery :用于解析HTML 中的元素。使用以下指令来安装这些套件:
pip install requests requests_html rich lxml PyQuery在基础篇中,会简单介绍如何从PTT 网页上收集资料,例如文章标题、作者和时间等。
以下用PTT 的看版文章作为我们的爬虫目标啰!
在进行网页爬虫时,我们使用requests.get()函式来模拟浏览器发送HTTP GET 请求来「浏览」网页。这个函式会返回一个requests.Response物件,其中包含了网页的回应内容。然而,需要注意的是,这个内容是以纯文字的原始码形式呈现,没有经过浏览器的渲染。我们可以透过response.text属性来取得。
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
在后续使用中我们会需要用到requests_html来扩增requests除了能像浏览器一样浏览,也需要解析HTML 网页, requests_html会将纯文字的response.text原始码包进requests_html.HTML方便后面的使用。改写也非常简单使用session.get()来替代上述的requests.get() 。
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )然而,当我们尝试套用这个方法到八卦版(Gossiping) 时,可能会遇到错误。这是因为在第一次浏览八卦版时,网站会确认年龄是否已满十八岁;当我们点击确认后,浏览器会记录相应的cookies,使得下次再次进入时就不会再次询问(你可以试着使用无痕模式打开测试看看八卦版首页)。然而,对于网页爬虫来说,我们需要把该笔特殊的cookies 记录下来,这样在浏览时就能假装已通过十八岁的测试。
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )接下来,我们可以使用response.html.find()方法来进行元素的定位,并使用CSS 选择器来指定目标元素。在这个步骤中,我们可以观察到在PTT 网页版中,每篇文章的标题讯息都位于具有r-ent类别的div标签中。因此,我们可以使用CSS 选择器div.r-ent来定位这些元素。
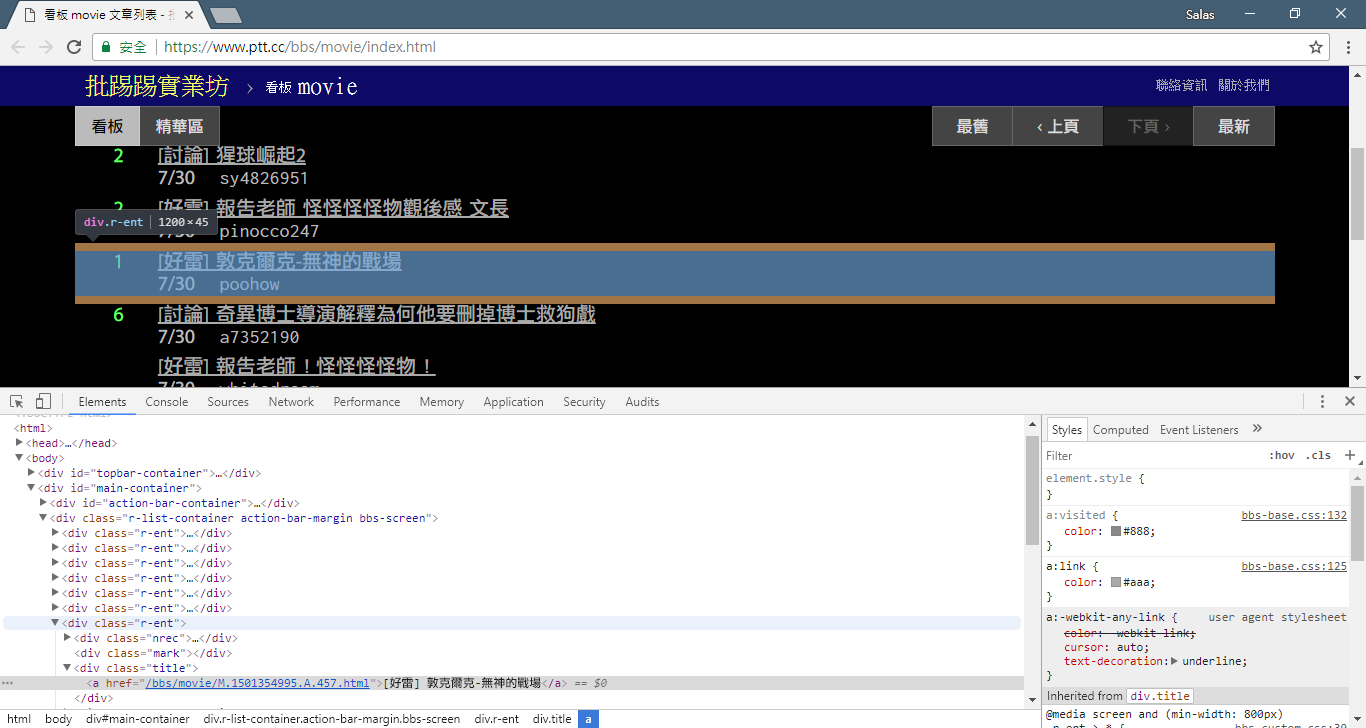
使用response.html.find()方法会回传一个符合条件的元素列表,所以我们可以使用for回圈来逐个处理这些元素。在每个元素内部,我们可以使用element.find()方法来进一步解析元素,并使用CSS 选择器来指定要提取的资讯。在这个范例中,我们可以使用CSS 选择器div.title来定位标题元素。同样地,我们可以使用element.text属性来获取元素的文字内容。
以下是使用requests_html的范例程式码:
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... 在前一步骤中,我们使用了response.html.find()方法来定位每个文章的元素。这些元素是以div.r-ent的CSS 选择器定位到的。 你可以使用开发者工具(Developer Tools) 功能来观察网页的元素结构。打开网页后按下F12 键,将显示一个开发者工具面板,其中包含了网页的HTML 结构和其他资讯。
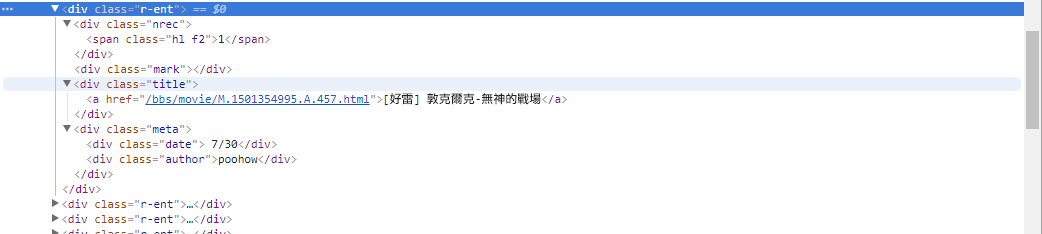
使用开发者工具,你可以使用滑鼠指标在网页上选择特定的元素,然后在开发者工具面板中查看该元素的HTML 结构、CSS 属性等详细资讯。这样可以帮助你确定要定位的元素和相应的CSS 选择器。 另外,或许会发现怎么程式有时候会出错啊? !看看网页版发现原来当该页面中有文章被删除时,网页上的<本文已被刪除>这个元素的原始码結構和原本不一样哇!所以我们可以进一步强化来处理文章被删除的情况。
现在,让我们回到使用requests_html进行资讯提取的范例程式码:
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )输出文字处理:
这边我们可以利用rich显示精美的输出,首先建立起rich的表格物件,然后将上述范例程式码回圈中的print替换成add_row到表格。最后,我们使用rich的print函式才能正确将表格输出到终端。
执行结果
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )
现在,我们将使用「观察法」来找出上一页的连结。不,我不是指问你浏览器上的按钮在哪里,而是要看开发者工具中的「source tree」。我相信你已经发现了,关于页面跳转的超连结位于<div class="action-bar">的<a class="btn wide">元素中。因此,我们可以像这样提取它们:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )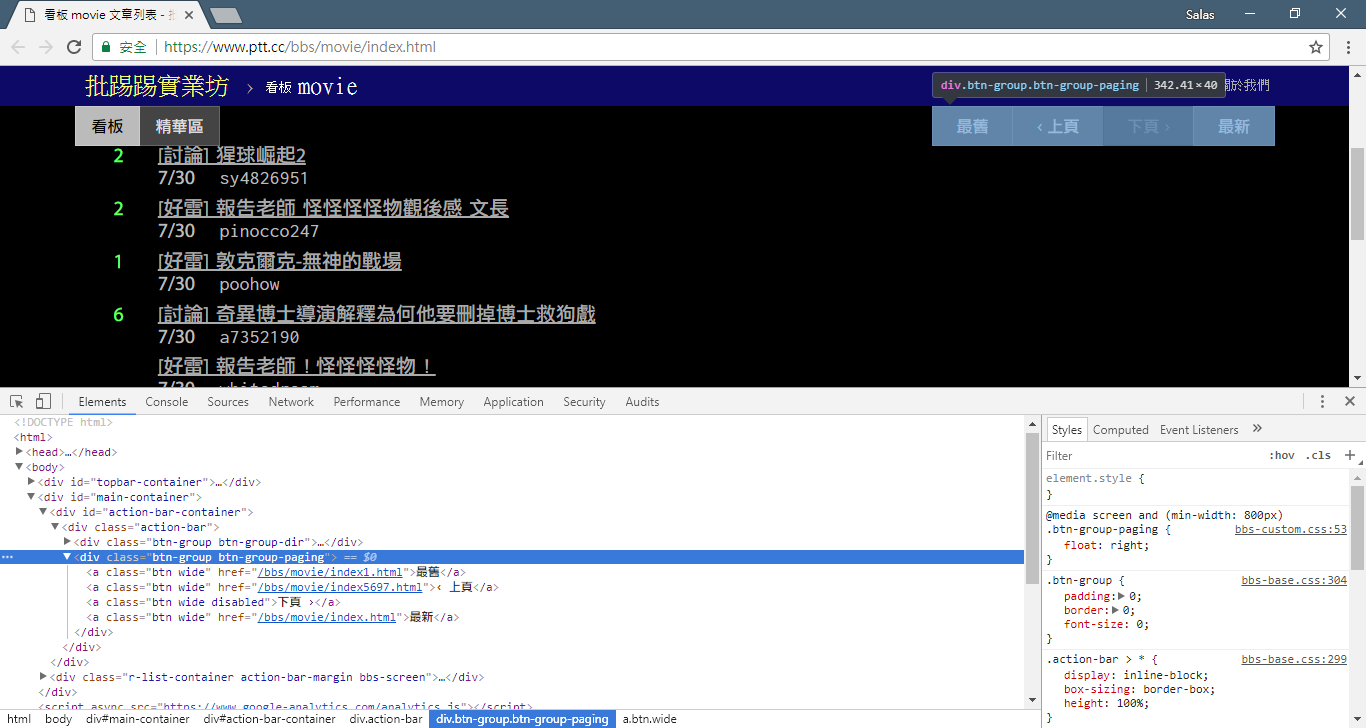
而我们需要的是「上页」的功能,为什么呢?因为PTT 是最新的文章显示在前面啊~所以要挖资料必须往前翻。
那怎么使用呢?先去抓出control中第二个(index 为1)的href ,然后他可能长这样/bbs/movie/index3237.html ;而完整的网址(URL) 必须要有https://www.ptt.cc/ (domain url) 开头,所以用urljoin() (或是字串直接相接) 把Movie 首页连结和新的link 比对合并成完整的URL!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url现在我们将函式重新整理一下方便后续说明,让第三步:让我们来看看这些标题讯息吧中处理每个文章元素的范例变成独立的函式parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return results接下来,我们就可以处理多页内容
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_url输出结果:
取得文章列表资讯后,再来就是取得文章(PO 文)内容(post content)了! 在metadata 中的link就是每篇文章的连结,同样使用urllib.parse.urljoin串接出完整网址之后发出HTTP GET 来取得该篇文章的内容。 我们可以观察到去抓每篇文章内容的任务是高度重复性的,很适合使用平行化的方法来处理。
在Python 中,可以使用multiprocessing.Pool来做high-level 的multiprocessing programming~这是Python 中使用multi-process 最简便的方法!非常适合这种SIMD (Single Instruction Multiple Data) 的应用场景。使用with statement 语法让使用完之后将process 资源自动释放。而ProcessPool 的用法也很简单, pool.map(function, items) ,有点像functional programming 的概念,将function 套用在每一个item 上,最后得出跟items 一样数量的结果列表。
使用在前面介绍的抓取文章内容的任务上:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )附上实验实测结果:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章可以看出整体执行速度加速了将近五倍,但并不一定Process越多越好,除了必须看CPU 等硬体规格,主要还是取决于网卡、网速等外部装置的限制。
上面的程式码都可以在( src/basic_crawler.py ) 中可以找到!
PTT Web 新功能:搜寻!终于可以在网页版使用了
一样使用PTT 的电影版作为我们的爬虫目标啰!在新版功能中可以搜寻的内容包含,
前三者都可以从新版的页面原始码及送出请求发现规则,不过推文数搜寻似乎还没有在网页版UI 介面中出现;所以这边是笔者从PTT 網站原始碼中挖掘出来的参数。平常我们浏览的PTT 其实包含BBS server (就是BBS),以及前台的Web server (网页版),而前台的Web server 是用Go 语言(Golang) 写的,可以直接存取后端BBS 资料,并且以一般网站互动模式将内容渲染成网页形式供浏览。
那其实要使用这些新功能非常简单,只需要透过HTTP GET形式的request 并且加上标准的query string 方式就能获得这些资讯。提供搜寻功能的endpoint URL 为/bbs/{看板名稱}/search ,只要用对应的query 即可从这边获得搜寻结果。首先以标题关键字为例,
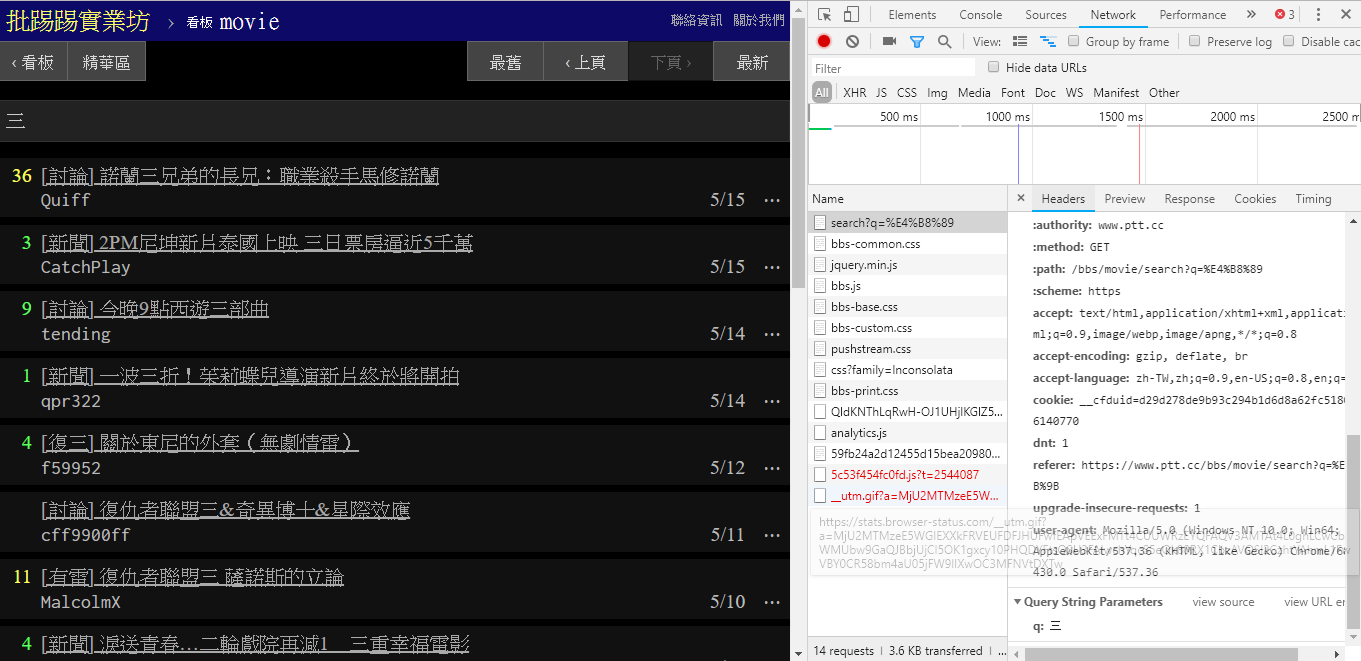
从图片中右下角可以看出,在搜寻时其实是对endpoint送出q=三的GET请求,所以整个完整的URL 应该像是https://www.ptt.cc/bbs/movie/search?q=三,不过从网址列复制下来的网址可能会是https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89这样的形式,是因为中文被HTML encode 过了但代表的是相同意思。而在requests中,想要增加额外的query 参数不用自己手动建构字串形式,只要透过param=的dict() 放到函式参数即可,就像是这样:
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })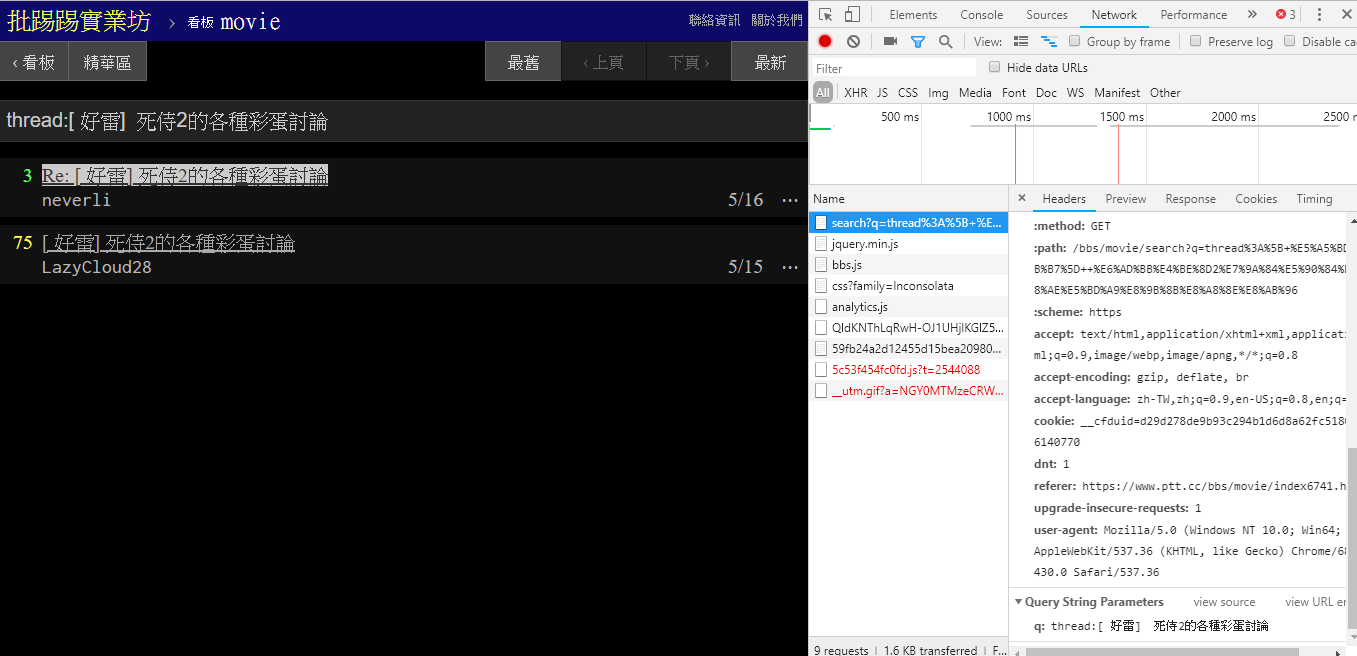
在搜寻相同文章(thread) 时,可以由右下角资讯看出,其实就是将thread:这个字串串到标题前面后送出查询。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })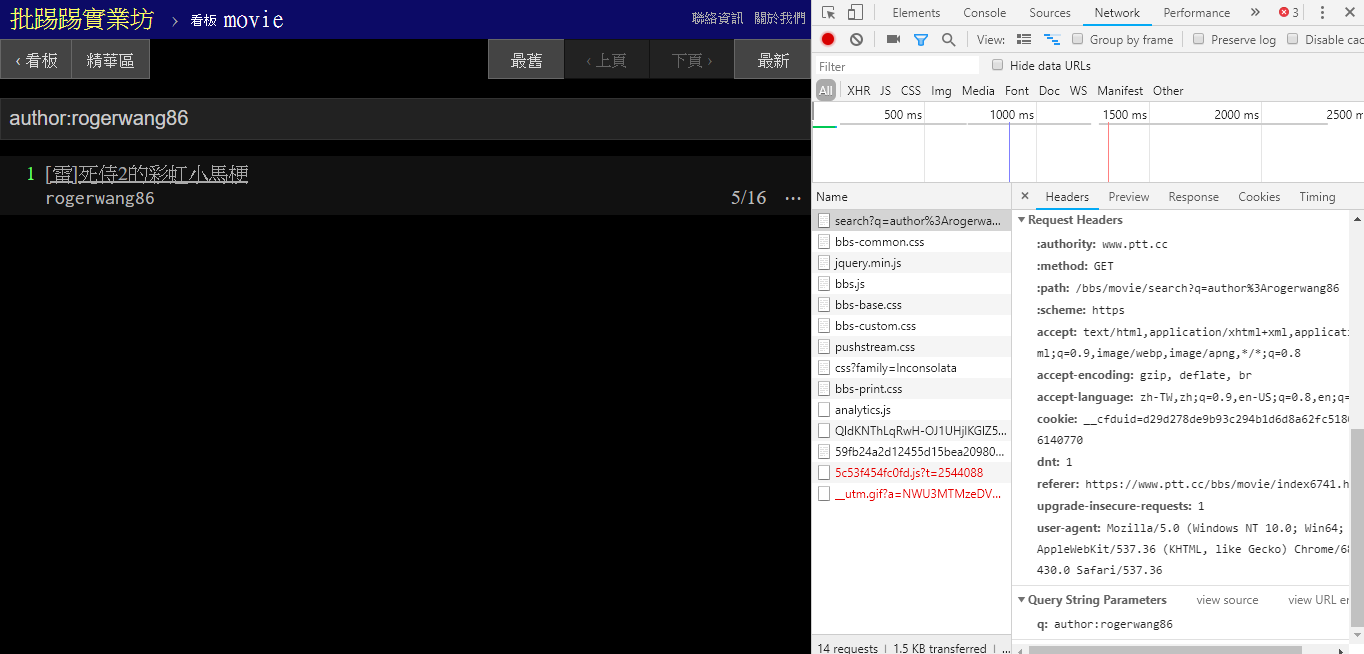
在搜寻相同作者文章(author) 时,同样由右下角资讯看出是将author:这个字串串上作者名字后送出查询。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })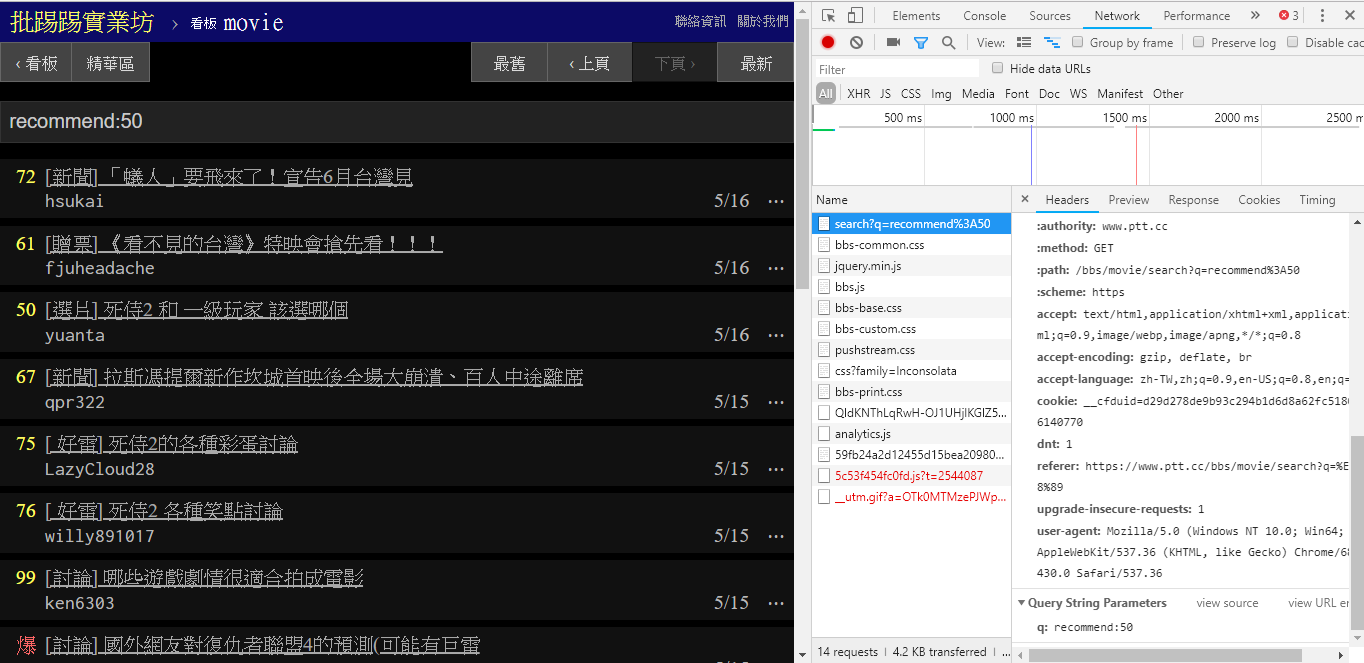
在搜寻推文数大于多少(recommend) 的文章时,就是将recommend:这个字串串上希望搜寻到的最低推文数后送出查询。另外可以从PTT Web server 原始码中发现推文数只能设定在±100 间。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })PTT Web parsing 这些参数的function 原始码
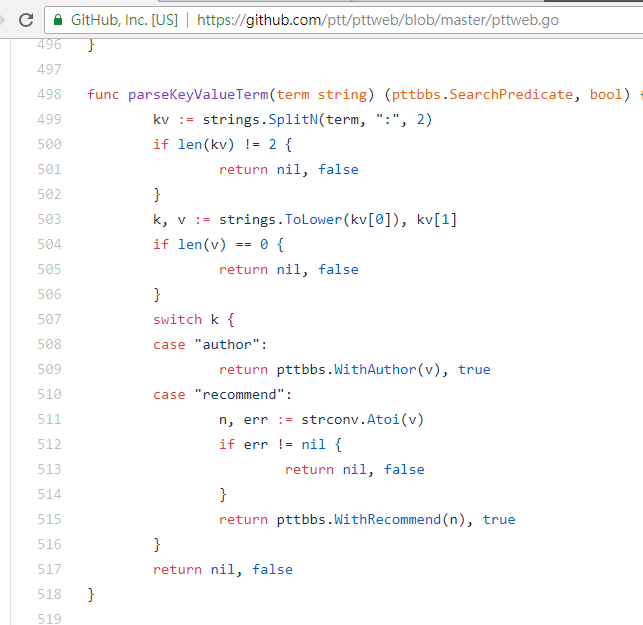
另外值得一提的是,搜寻结果最后的呈现也跟基础篇里提到的一般版面相同,所以可以直接将前面的function 再拿来重复利用, Don't do it again!
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用]在搜寻中有另一个参数,页数page就跟Google 搜寻一样,搜寻到的东西也许有很多页,那么就可以透过这个额外的参数来控制要取得第几页结果,而不需要再去parse 页面上的link。
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 })将前面所有的功能通通整合进ptt-parser,可以提供command-line 功能以及可程式化呼叫的API 形式的爬蟲。
scrapy稳定爬取PTT 资料。
本著作由leVirve制作,以创用CC 姓名标示4.0 国际授权条款释出。


