pianola
1.0.0
 钢琴演奏中" style="max-width: 100%;">
钢琴演奏中" style="max-width: 100%;">
pianola是一款播放人工智能生成的钢琴音乐的应用程序。用户通过在键盘上弹奏音符或从经典作品中选择示例片段来播种(即“提示”)AI 模型。
在本自述文件中,我们解释了人工智能的工作原理,并详细介绍了模型的架构。
音乐可以用多种方式表示,从原始音频波形到半结构化 MIDI 标准。在pianola中,我们将音乐节拍分解为规则的、均匀的音程(例如十六分音符/十六分音符)。在一个音程内演奏的音符被认为属于同一个时间步,一系列时间步形成一个序列。使用基于网格的序列作为输入,AI 模型预测下一个时间步中的音符,进而将其用作以自回归方式预测后续时间步的输入。
除了要演奏的音符之外,该模型还预测每个音符的持续时间(按下音符的时间长度)和力度(敲击琴键的力度)。
该模型由三个模块组成:嵌入器、变压器和解码器。这些模块借鉴了 Inception 网络、LLaMA 变压器和多标签分类器链等众所周知的架构,但适合处理音乐数据并以新颖的方法组合。
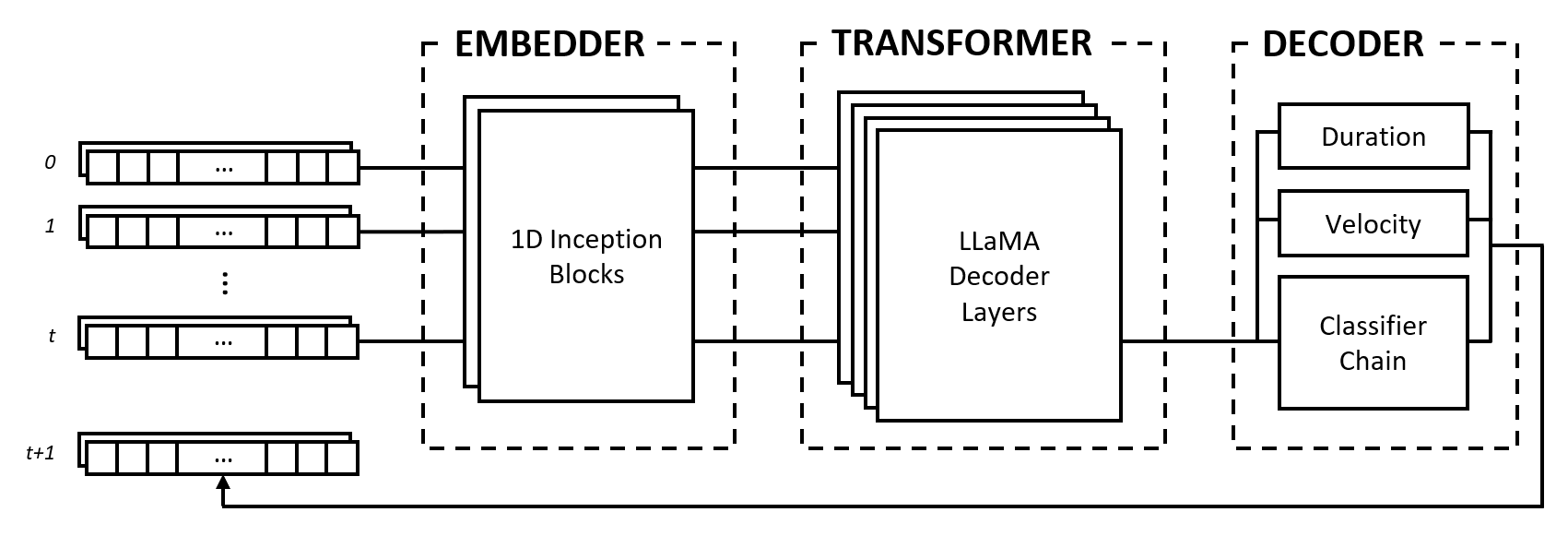
嵌入器将形状(num_notes, num_features)的每个输入时间步转换为可以馈送到变压器中的嵌入向量。然而,与将单热向量映射到另一个维度空间的文本嵌入不同,我们通过在输入上应用卷积层和池化层来提供归纳偏差。我们这样做有很多原因:
2^num_notes ,其中num_notes对于普通钢琴来说是 64 或 88 ),因此不可能将它们表示为 one-hot 向量。为了让嵌入器了解哪些距离有用,我们从 Inception 网络和不同内核大小的堆栈卷积中获得灵感。
Transformer 模块由 LLaMA Transformer 层组成,这些层将自注意力机制应用于输入嵌入向量序列。
与许多生成式 AI 模型一样,该模块仅使用 Vaswani 等人的原始 Transformers 模型的“解码器”部分。 (2017)。我们在这里使用标签“transformer”来区分该模块与以下模块,后者对自注意力层产生的状态进行实际解码。
我们选择 LLaMA 架构而不是其他类型的 Transformer,主要是因为它使用旋转位置嵌入 (RoPE),该嵌入对随着时间步长的距离衰减的相对位置进行编码。鉴于我们将音乐数据表示为固定间隔,时间步之间的相对位置和距离是重要的信息,变压器可以明确地使用这些信息来理解和生成具有一致节奏的音乐。
解码器接收参与状态并预测要一起演奏的音符及其持续时间和速度。该模块由几个子组件组成,即用于音符预测的分类器链和用于特征预测的多层感知器(MLP)。
分类器链由num_notes个二元分类器组成,即钢琴上的每个琴键一个分类器,以创建多标签分类器。为了利用音符之间的相关性,二元分类器被链接在一起,以便先前音符的结果影响后续音符的预测。例如,如果八度音符之间存在正相关,则活跃的较低音符(例如C3 )导致较高音符(例如C4 )被预测的较高概率。这在负相关的情况下也是有益的,在这种情况下,人们可以在两个相邻音符之间进行选择,从而产生大调或小调音阶(例如CDE与CD-Eb ),但不能同时选择两者。
为了计算效率,我们将链的长度限制为 12 个链接,即 1 个八度。最后,使用采样解码策略来选择与其预测概率相关的音符。
持续时间和速度特征被视为回归问题,并使用普通 MLP 进行预测。虽然预测每个音符的特征,但我们在训练期间使用自定义损失函数,该函数仅聚合活动音符的特征损失,类似于具有本地化任务的图像分类中使用的损失函数。
我们选择将音乐数据表示为网格有其优点和缺点。我们通过将其与 Oore 等人提出的基于事件的词汇进行比较来讨论这些观点。 (2018),音乐生成领域被高度引用的贡献。
我们方法的主要优点之一是对音乐的微观和宏观理解的解耦,这导致嵌入器和变压器之间的职责明确分离。前者的作用是在微观层面上解释音符的相互作用,例如音符之间的相对距离如何形成和弦等音乐关系,后者的任务是在时间维度上综合这些信息,以从宏观上理解音乐风格等级。
相比之下,基于事件的表示将全部负担放在序列模型上来解释单热标记,这些标记可以表示音调、时间或速度这三个不同的概念。黄等人。 (2018)发现有必要在他们的 Transformer 模型中添加相对注意机制,以便生成连贯的延续,这表明该模型需要归纳偏差才能在这种表示上表现良好。
在网格表示中,间隔长度的选择是数据保真度和稀疏性之间的权衡。较长的间隔会降低音符计时的粒度,降低音乐表现力,并可能压缩颤音和重复音符等快速元素。另一方面,较短的间隔会引入大量空时间步,从而呈指数级增加稀疏性,这对于 Transformer 模型来说是一个重要问题,因为它们受到序列长度的限制。
此外,音乐数据可以通过时间的流逝( 1 timestep == X milliseconds )或以乐谱形式写入( 1 timestep == 1 sixteenth note/semiquaver )映射到网格,每个数据都有自己的权衡。基于事件的表示通过将时间的流逝指定为事件来完全避免这些问题。
尽管有其缺点,网格表示法仍具有实际优势,因为它在pianola的开发中更容易使用。模型输出是人类可读的,时间步数对应于固定的时间量,使得新功能的开发更快。
此外,对扩展 Transformer 模型序列长度的研究以及对硬件的持续改进将逐步减少数据稀疏引起的问题,截至 2023 年末,我们将看到可以处理数万个标记的大型语言模型。随着技术的优化和强大的硬件变得更容易使用,我们相信保真度将继续提高,就像图像生成一样,从而使人工智能生成的音乐具有更大的表现力和细微差别。
为了学术研究和知识共享的目的,该项目的源代码是公开可见的。除非明确授予许可,否则所有权利均由创建者保留。
站点图标修改自 Freepik - Flaticon。
通过 Outlook.com 联系,地址为bruce <dot> ckc 。


