UniIR
1.0.0
主页| ?数据集(M-BEIR Benchmark) | ?检查点( UniIR型号) | arXiv | GitHub
该存储库包含 ECCV-2024 论文“ UniIR :通用多模态信息检索器的训练和基准测试”的代码库
我们提出了UniIR (通用多模态信息检索)框架来学习单个检索器来完成(可能)任何检索任务。与传统的 IR 系统不同, UniIR需要按照说明进行异构查询,以从具有数百万个不同模式的候选者的异构候选池中进行检索。
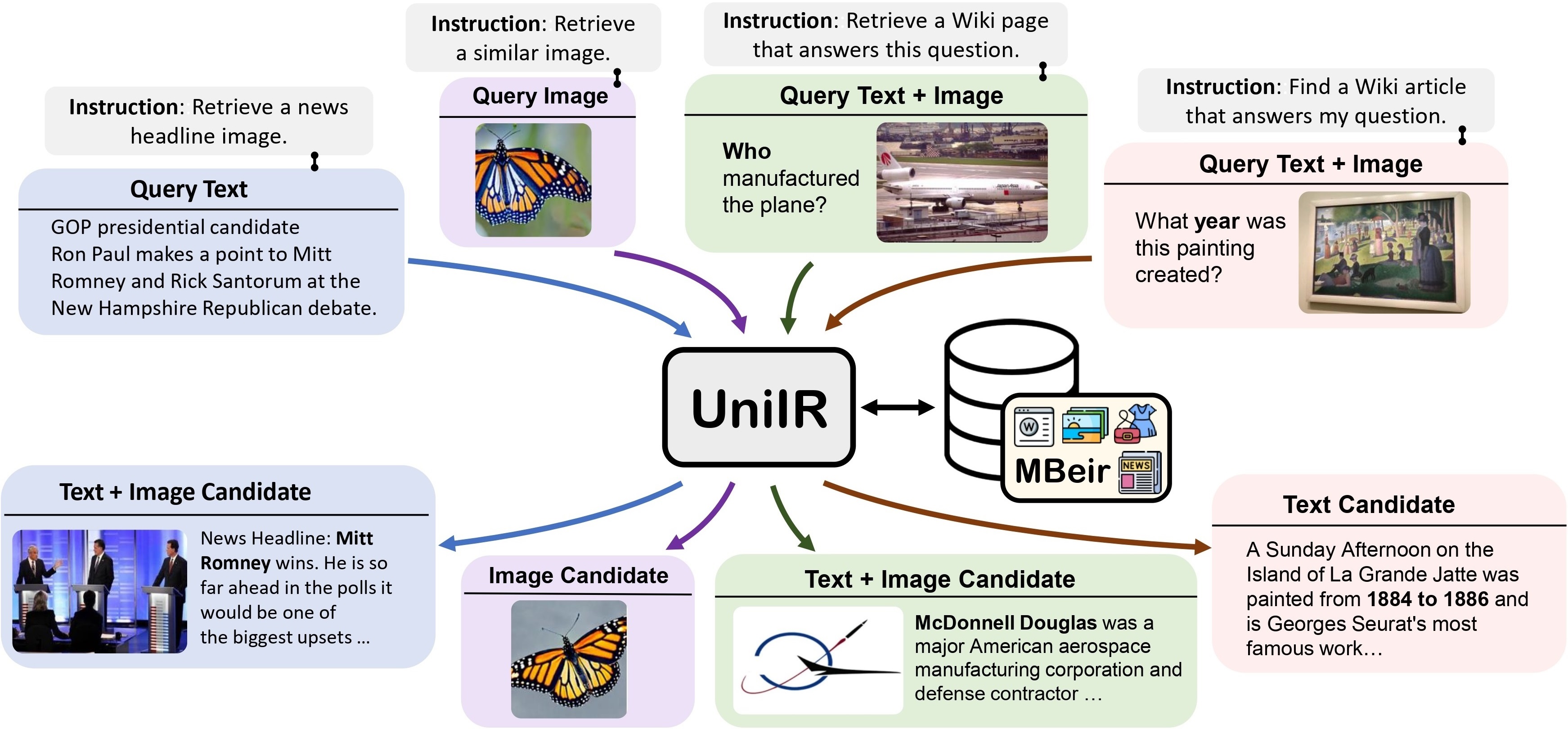 UniIR Teaser" style="width: 80%;最大宽度:100%;">
UniIR Teaser" style="width: 80%;最大宽度:100%;">
为了训练和评估通用多模态检索模型,我们构建了一个名为M-BEIR (指导检索的多模态基准)的大规模检索基准。
我们在?中提供 M-BEIR 数据集。数据集。请按照 HF 页面上提供的说明下载数据集并准备用于训练和评估的数据。您需要设置 GiT LFS 并直接克隆存储库:
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
我们提供用于训练和评估UniIR CLIP-ScoreFusion、CLIP-FeatureFusion、BLIP-ScoreFusion 和 BLIP-FeatureFusion 模型的代码库。
使用以下命令准备UniIR项目和 Conda 环境的代码库:
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.yml要从预训练的 CLIP 和 BLIP 检查点训练UniIR模型,请按照以下说明进行操作。脚本将自动下载预训练的 CLIP 和 BLIP 检查点。
请按照M-BEIR部分中的说明下载 M-BEIR 基准测试。
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/修改inbatch.yaml以进行超参数调整,并run_inbatch.sh以适应您自己的环境和路径。
run_inbatch.sh中的UniIR _DIR修改为要存储检查点的目录。run_inbatch.sh中的MBEIR_DATA_DIR修改为M-BEIR基准测试的存储目录。run_inbatch.sh中的SRC_DIR修改为存储UniIR项目代码库的目录(此存储库)。WANDB_API_KEY 、 WANDB_PROJECT和WANDB_ENTITY的.env环境。然后您可以运行以下命令来训练UniIR CLIP_SF Large 模型。
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/修改inbatch.yaml以进行超参数调整,并run_inbatch.sh以适应您自己的环境和路径。
bash run_inbatch.sh我们在 M-BEIR 基准上提供UniIR模型的评估流程。
请为 FAISS 库创建一个环境:
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.yml请按照M-BEIR部分中的说明下载 M-BEIR 基准测试。
您可以按照模型动物园部分中的说明从头开始训练UniIR模型或下载预先训练的UniIR检查点。
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/根据您自己的环境、路径和评估设置修改embed.yaml 、 index.yaml 、 retrieval.yaml和run_eval_pipeline_inbatch.sh 。
run_eval_pipeline_inbatch.sh中的UniIR _DIR修改为您要存储大文件(包括检查点、嵌入、索引和检索结果)的目录。然后您可以将clip_sf_large.pth文件放置在以下路径中: $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthembed.yaml文件中model.ckpt_config指定的默认路径。run_eval_pipeline_inbatch.sh中的MBEIR_DATA_DIR修改为M-BEIR基准测试的存储目录。run_eval_pipeline_inbatch.sh中的SRC_DIR修改为存储UniIR项目代码库的目录(此存储库)。默认配置将在 M-BEIR(5.6M 异构候选池)和 M-BEIR_local(同质候选池)基准上评估UniIR CLIP_SF Large 模型。 yaml文件中的UNION指的是M-BEIR(5.6M异构候选池)。您可以按照yaml文件中的注释并修改配置以仅在M-BEIR_local基准测试上评估模型。
bash run_eval_pipeline_inbatch.sh embed 、 index 、 logger和retrieval_results将保存在$ UniIR _DIR目录中。
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/同样,如果您下载我们预训练的UniIR模型,则可以将blip_ff_large.pth文件放置在以下路径中:
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pth默认配置将在 M-BEIR 和 M-BEIR_local 基准测试上评估UniIR BLIP_FF Large 模型。
bash run_eval_pipeline_inbatch.shUniRAG 评估与默认评估非常相似,但存在以下差异:
retrieval_results下。当检索到的结果将用于 RAG 等下游应用程序时,这非常有用。retrieval.yaml中的retrieve_image_text_pairs设置为True时,将为每个仅text或仅image模式的候选者获取补集候选者。通过这种设置,候选词及其补语将始终具有image, text形态。通过使用原始候选作为查询来获取补充候选(例如,查询文本->候选图像->补充候选文本)。InBatch和inbatch替换为UniRAG和unirag 。 我们在?中提供UniIR模型检查点检查站。您可以直接使用检查点进行检索任务,也可以针对自己的检索任务微调模型。
| 型号名称 | 版本 | 型号尺寸 | 型号链接 |
|---|---|---|---|
| UniIR (CLIP-SF) | 大的 | 5.13GB | 下载链接 |
| UniIR (BLIP-FF) | 大的 | 7.49 GB | 下载链接 |
您可以通过以下方式下载它们
git clone https://huggingface.co/TIGER-Lab/UniIR
参考书目:
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

