mlmm evaluation
1.0.0
多语言大语言模型评估框架
该存储库包含多语言大型语言模型 (LLM) 的基准数据集和评估脚本。这些数据集可用于评估 26 种不同语言的模型,并涵盖三个不同的任务:ARC、HellaSwag 和 MMLU。这是作为我们的 Okapi 框架的一部分发布的,该框架用于根据人类反馈进行强化学习的多语言指令调整法学硕士。
目前,我们的数据集支持 26 种语言:俄语、德语、中文、法语、西班牙语、意大利语、荷兰语、越南语、印度尼西亚语、阿拉伯语、匈牙利语、罗马尼亚语、丹麦语、斯洛伐克语、乌克兰语、加泰罗尼亚语、塞尔维亚语、克罗地亚语、印地语、孟加拉语、泰米尔语、尼泊尔语、马拉雅拉姆语、马拉地语、泰卢固语和卡纳达语。
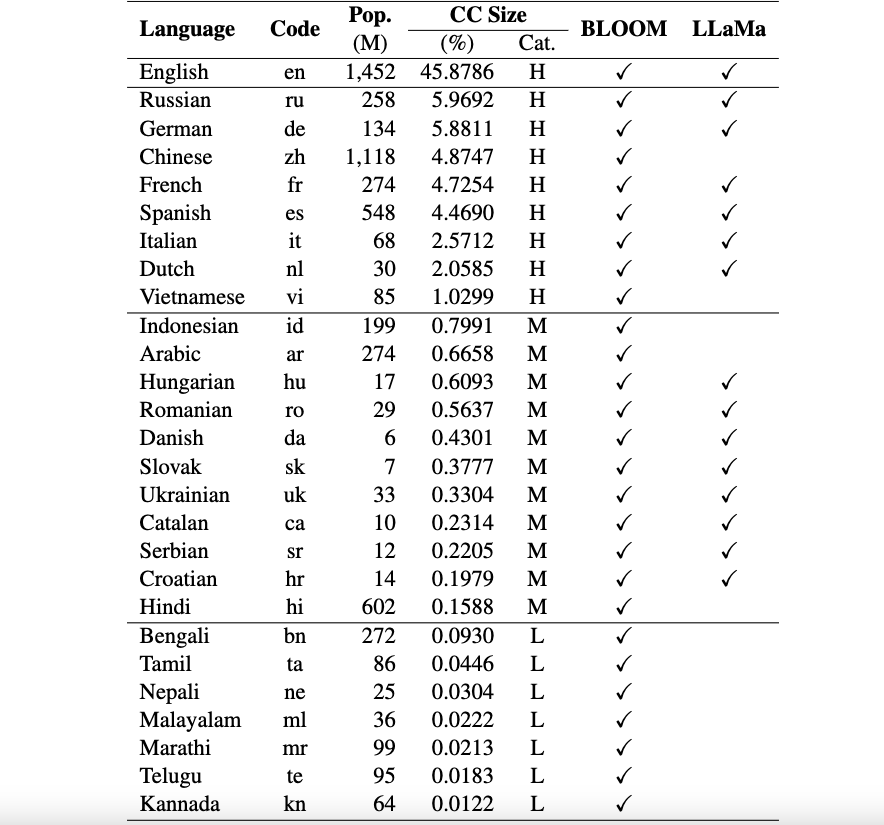
这些数据集是使用 ChatGPT 从原始 ARC、HellaSwag 和 MMLU 数据集翻译成英文的。您可以在此处找到我们为 Okapi 编写的技术论文,该论文描述了数据集以及多个多语言 LLM(例如 BLOOM、LLaMa 和我们的 Okapi 模型)的评估结果。
使用和许可声明:我们的评估框架仅供研究使用并获得许可。数据集为 CC BY NC 4.0(仅允许非商业用途),不得在研究目的之外使用。
要从我们的存储库主分支安装lm-eval ,请运行:
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " 首先,您需要使用以下脚本下载多语言评估数据集:
bash scripts/download.sh要在三个任务上评估模型,您可以使用以下脚本:
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]例如,如果您想评估我们的 Okapi Vietnam 模型,您可以运行:
bash scripts/run.sh vi uonlp/okapi-vi-bloom我们维护一个排行榜来跟踪多语言法学硕士的进度。
我们的框架主要继承自 EleutherAI 的 lm-evaluation-harness 存储库。如果您使用该代码,还请引用他们的存储库。
如果您使用此存储库中的数据、模型或代码,请引用:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

