CTCWordBeamSearch
1.0.0
具有字典和语言模型 (LM) 的联结时间分类 (CTC) 解码器。
pip install .tests/并执行pytest检查安装是否有效以下玩具示例展示了如何使用词束搜索。假设模型(例如文本识别模型)能够识别 3 个不同的字符:“a”、“b”和“ ”(空格)。该玩具示例中的单词可以包含字符“a”和“b”(但不能包含“”,它是单词分隔符)。语言模型是根据仅包含两个单词的文本语料库进行训练的:“a”和“ba”。
在此代码片段中,创建了词束搜索的实例,并解码了 TxBx(C+1) 形状的 numpy 数组:
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )解码器返回一个列表,其中包含每个批处理元素的已解码标签字符串。要最终获取字符串,请将每个标签映射到其对应的字符:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )示例:
tests/test_word_beam_search.py中找到WordBeamSearch类的构造函数的参数:
0<len(wordChars)<len(chars) 。如果只需要检测单个单词,则不需要分隔符,因此两个参数也可以相等: 0<len(wordChars)<=len(chars) WordBeamSearch.compute方法的输入:
词束搜索是一种CTC解码算法。它用于序列识别任务,例如手写文本识别或自动语音识别。
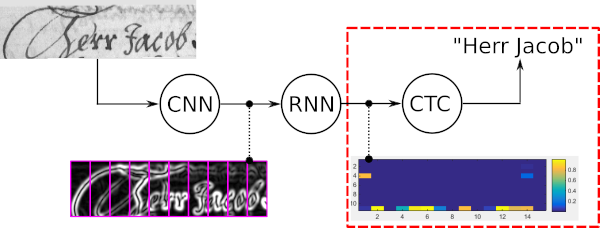
词束搜索的四个主要属性是:
以下示例显示了词束搜索的典型用例以及五个不同解码器给出的结果。最佳路径解码和普通波束搜索会出现错误,因为这些解码器仅使用光学模型的噪声输出。通过字符级 LM 扩展普通波束搜索,仅允许可能的字符序列,从而改善结果。令牌传递使用字典和单词级 LM,因此可以正确获取所有单词。但是,它无法识别数字等任意字符串。词束搜索能够利用字典来识别单词,但也能够正确识别非单词字符。

更多信息:
extras/prototype/extras/tf/ 如果您在研究工作中使用词束搜索,请引用以下论文。
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


