KoGPT2
1.0.0
GPT-2 是一种能够很好地预测给定文本中下一个单词的语言模型,并且针对句子生成进行了优化。 KoGPT2是一种韩语decoder语言模型,使用超过 40GB 的文本进行学习,以克服韩语语言性能不足的问题。
 |
使用tokenizers包中的Character BPE tokenizer进行训练。
字典大小为51,200,通过添加表情符号和表情符号(例如对话中经常使用的表情符号)来提高令牌的识别能力,如下所示。
?, ?, ?, ?, ?, .. ,
:-),:),-),(-:...
此外,还定义了未使用的标记,例如<unused0>至<unused99>以便可以根据所需任务自由定义和使用它们。
> from transformers import PreTrainedTokenizerFast
> tokenizer = PreTrainedTokenizerFast . from_pretrained ( "skt/ KoGPT2 -base-v2" ,
bos_token = '</s>' , eos_token = '</s>' , unk_token = '<unk>' ,
pad_token = '<pad>' , mask_token = '<mask>' )
> tokenizer . tokenize ( "안녕하세요. 한국어 GPT-2 입니다.?:)l^o" )
[ '▁안녕' , '하' , '세' , '요.' , '▁한국어' , '▁G' , 'P' , 'T' , '-2' , '▁입' , '니다.' , '?' , ':)' , 'l^o' ]| 模型 | 参数数量 | 类型 | 层数 | 头数 | ffn_dim | 隐藏的尺寸 |
|---|---|---|---|---|---|---|
KoGPT2 -base-v2 | 125M | 解码器 | 12 | 12 | 3072 | 第768章 |
> import torch
> from transformers import GPT2LMHeadModel
> model = GPT2LMHeadModel . from_pretrained ( 'skt/ KoGPT2 -base-v2' )
> text = '근육이 커지기 위해서는'
> input_ids = tokenizer . encode ( text , return_tensors = 'pt' )
> gen_ids = model . generate ( input_ids ,
max_length = 128 ,
repetition_penalty = 2.0 ,
pad_token_id = tokenizer . pad_token_id ,
eos_token_id = tokenizer . eos_token_id ,
bos_token_id = tokenizer . bos_token_id ,
use_cache = True )
> generated = tokenizer . decode ( gen_ids [ 0 ])
> print ( generated )
근육이 커지기 위해서는 무엇보다 규칙적인 생활습관이 중요하다 .
특히 , 아침식사는 단백질과 비타민이 풍부한 과일과 채소를 많이 섭취하는 것이 좋다 .
또한 하루 30 분 이상 충분한 수면을 취하는 것도 도움이 된다 .
아침 식사를 거르지 않고 규칙적으로 운동을 하면 혈액순환에 도움을 줄 뿐만 아니라 신진대사를 촉진해 체내 노폐물을 배출하고 혈압을 낮춰준다 .
운동은 하루에 10 분 정도만 하는 게 좋으며 운동 후에는 반드시 스트레칭을 통해 근육량을 늘리고 유연성을 높여야 한다 .
운동 후 바로 잠자리에 드는 것은 피해야 하며 특히 아침에 일어나면 몸이 피곤해지기 때문에 무리하게 움직이면 오히려 역효과가 날 수도 있다 ...| NSMC(acc) | KorSTS(矛兵) | |
|---|---|---|
| KoGPT2 2.0 | 89.1 | 77.8 |
除了韩语维基百科之外,还使用新闻、大家语料库v1.0等各种数据来训练模型。
演示链接
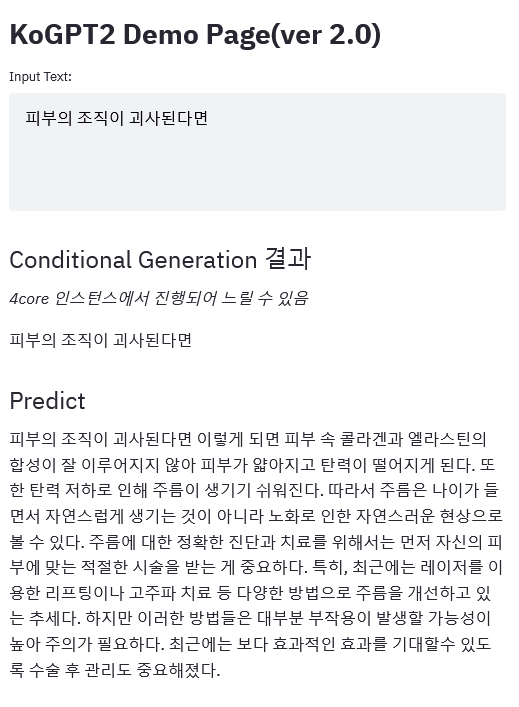 |
请在此发布与KoGPT2相关的问题。
KoGPT2根据 CC-BY-NC-SA 4.0 许可证发布。使用模型和代码时请遵守许可条款。完整的许可证可以在 LICENSE 文件中找到。


