icl selective annotation
1.0.0
论文代码选择性注释使语言模型更好少样本学习者
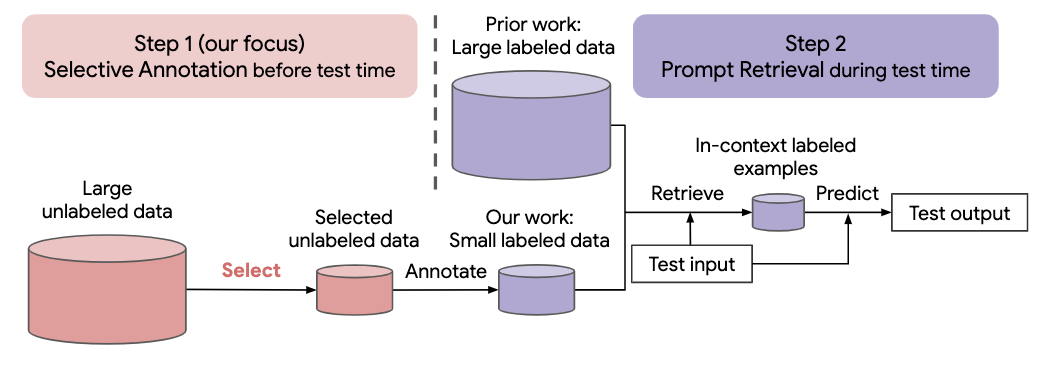
最近许多自然语言任务的方法都是建立在大型语言模型的卓越能力之上的。大型语言模型可以执行上下文学习,从一些任务演示中学习新任务,而无需任何参数更新。这项工作研究了上下文学习对于为新的自然语言任务创建数据集的影响。与最近的上下文学习方法不同,我们制定了一个高效注释的两步框架:选择性注释,提前从未标记的数据中选择一个示例池进行注释,然后进行提示检索,从注释池中检索任务示例测试时间。基于这个框架,我们提出了一种无监督的、基于图的选择性注释方法, vote-k ,来选择多样化的、有代表性的示例进行注释。对 10 个数据集(涵盖分类、常识推理、对话和文本/代码生成)的广泛实验表明,我们的选择性注释方法大幅提高了任务性能。平均而言,与随机选择示例进行注释相比,vote-k 在 18/100 的注释预算下实现了12.9%/11.4% 的相对增益。与最先进的监督微调方法相比,它在 10 个任务中产生相似的性能,但注释成本降低了 10-100 倍。我们进一步分析了我们的框架在各种场景中的有效性:不同大小的语言模型、替代的选择性注释方法以及存在测试数据域转移的情况。随着大型语言模型越来越多地应用于新任务,我们希望我们的研究能够成为数据注释的基础
运行以下命令来克隆此存储库
git clone https://github.com/HKUNLP/icl-selective-annotation
要建立环境,请在 shell 中运行以下代码:
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
这将创建我们使用的环境selective_annotation。
通过运行激活环境
conda activate selective_annotation
GPT-J作为上下文学习模型,DBpedia作为任务,vote-k作为选择性标注方法(1个GPU,40GB内存)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
如果您发现我们的工作有帮助,请引用我们
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


